Your own data (RAG) for your AI agent, part one - step by step with Python and PostgreSQL
From unreliable memory through full-text and embeddings to hybrid search with re-ranking.
When I ask you about factual information, perhaps something from a corporate policy, give you a question from an Azure test, or ask which movie you would recommend to someone who liked Matrix, you may try to answer from memory. You might struggle to remember exactly, you might make mistakes, get something a bit wrong, and if I ask you to cite the source (which page of which document mentions it) you often will not know where you learned it.
Compare that with letting you look online before answering, leaf through notes, skim a printed policy, or click through Azure docs. Accuracy will improve significantly and you will be able to cite sources. Great. But what if instead of focused docs I dump pages from the whole library at you with no covers and no ordering? It will help, but it will take much longer, you will lose energy, and if most pages are irrelevant you will lose attention and miss the right answer somewhere in the middle.
Why RAG matters
If I ask you for factual information, perhaps something from company policies, a question from an Azure test, or a movie recommendation for someone who liked The Matrix and wants something similar, you can try to answer from memory.
You may not remember everything precisely. You may make a mistake, mix something up a little, and if I ask you to cite the necessary sources (which page of which document says it), you often will not know where your knowledge came from.
Compare that with a situation where I tell you that before answering you may search the Internet, browse notes, skim printed policies, or click through Azure documentation. I assume that this will significantly improve the accuracy of your answers and that you will also tell me where the information is written and cite the sources.
But what if, instead of pointing you to a relevant part of the documentation or policy, I give you pages from an entire library without covers, ordering, or any index of titles? Will it help? Probably yes, but it will take much longer, consume much more energy, and if most pages are irrelevant, you may lose attention and miss the correct answer somewhere in the middle.
What I have just described also applies to large language models (LLMs), and it is called Retrieval Augmented Generation (RAG).
Ideally the model receives the most precisely targeted documents where the answer is hidden, so it can produce accurate, fast, and cheap output. If we miss and give it documents that are not very relevant, the answers get worse. If we have a model with a large context window and dump the whole library into it, it will be expensive, slow, and still not as good as using well-selected reference documents.
Today I want to focus on finding the right supporting material for your LLM. This time we will not solve document preparation and chunking, nor more complex knowledge bases built on graphs of relationships and summaries. That is for another time.
We will work with PostgreSQL because it lets me learn what is happening under the hood. For real projects, definitely consider Azure AI Search as well, because it can do all of this directly and also handles chunking and ingestion.
RAG progression in this article
1Full-text
classic search over words and their stems.
2Query rewriting
adjusting the query so it is easier to search for.
3Embeddings
semantic search in latent space.
4Hybrid search
combining full-text and vectors.
5Re-ranking
a smaller model reorders preselected results by relevance.
We will show all techniques on a simple example with movies and their descriptions. Next time we will move to more complex techniques that require deeper data processing, hierarchical and graph approaches, and summarization.
Preparing data in PostgreSQL
Please open the Jupyter Notebook on my GitHub. It contains concrete results and outputs, and I recommend keeping it next to the article while reading.
The story starts by taking documents, in this case movie descriptions, and loading them into PostgreSQL. I create a combined column with the title and overview so vectors are easier to make. The required infrastructure, such as Azure OpenAI models and Azure PostgreSQL Flexible Server, can be deployed from my Terraform in the relevant directory.
Data
movie titles and descriptions.
Database
PostgreSQL, so I can see what happens under the hood.
Models
Azure OpenAI for embeddings.
Goal
understand retrieval layers, not build a finished enterprise product.
Before importing the data, I need to add several extensions:
Extension
Why I use it
azure_ai
Call Azure OpenAI for embeddings, and potentially other Azure AI services, directly from PSQL.
pgvector
Store embeddings in PostgreSQL and perform vector search.
pg_diskann
Search embedding vectors faster and more efficiently.
I create a table, add an embedding column with 2000 dimensions, add another full_text_search column for tsvector (statistics for full-text search, essentially word stems and their occurrences), and add a DiskANN index. Then I insert the data and add embeddings with an SQL UPDATE command and an azure_ai function, so the database calls Azure OpenAI by itself.
Search techniques
First, let us use full-text search. PostgreSQL goes through the descriptions, identifies word stems, counts them, and stores the statistics for each movie. We ask a question, run it through full-text search, and take the first 10 nearest answers. The questions and answers are in the linked Jupyter notebook and then we feed them to an LLM to formulate the answer.
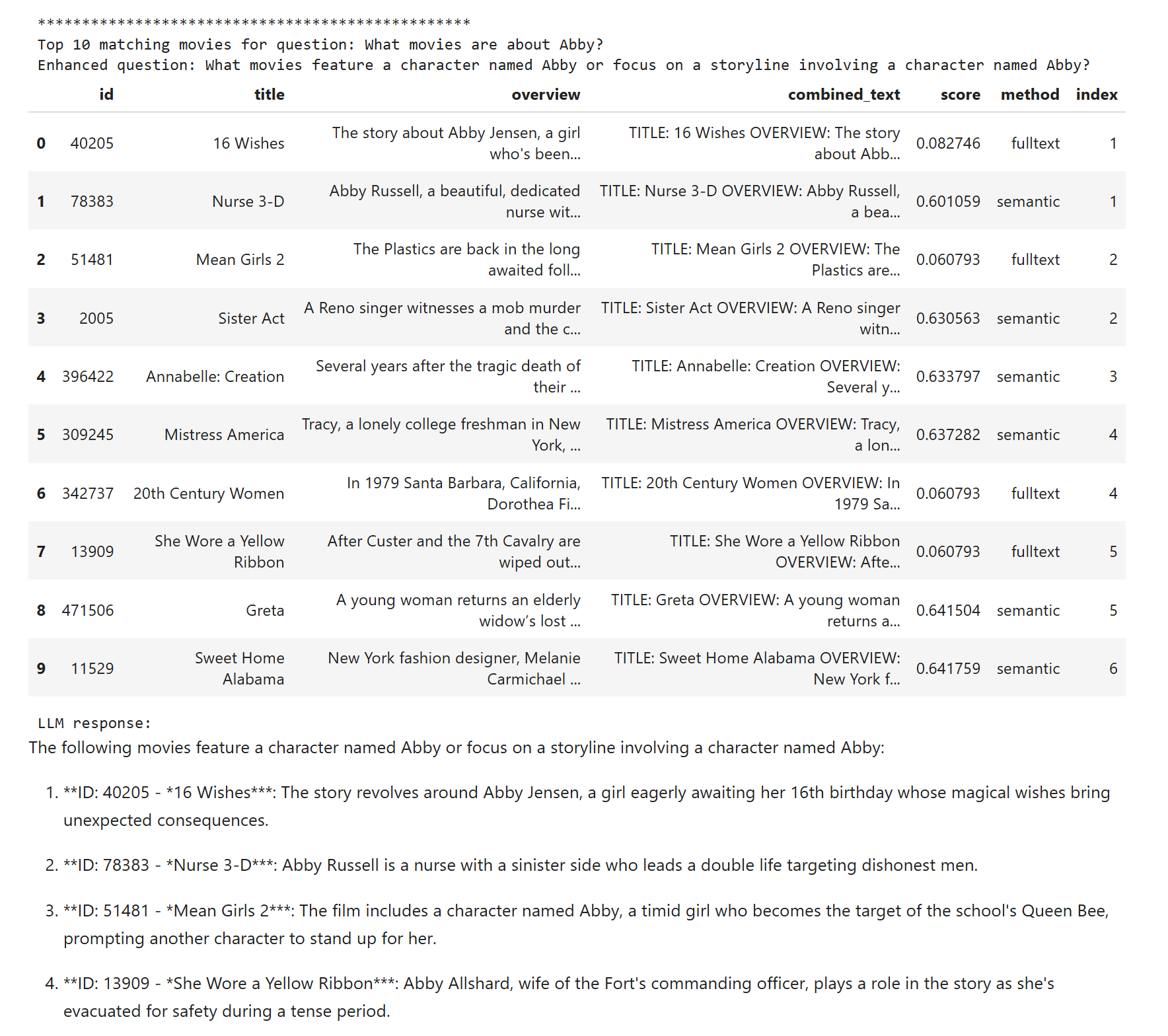
The first attempt is not great. The Abby question returns only one movie, which is too little, and the others are not very good either. The issue is that full-text search is not ChatGPT, so the question What movies are about Abby? is poorly suited for it. We search all these words even though, except for Abby, none of them really matters.
Let's do question rewriting: we let a smaller language model (I use gpt-4o-mini) reformulate and optimize the query for full-text search. In the notebook you can see this scenario, including the rewritten query, and the Abby results are much better this time (4 movies).
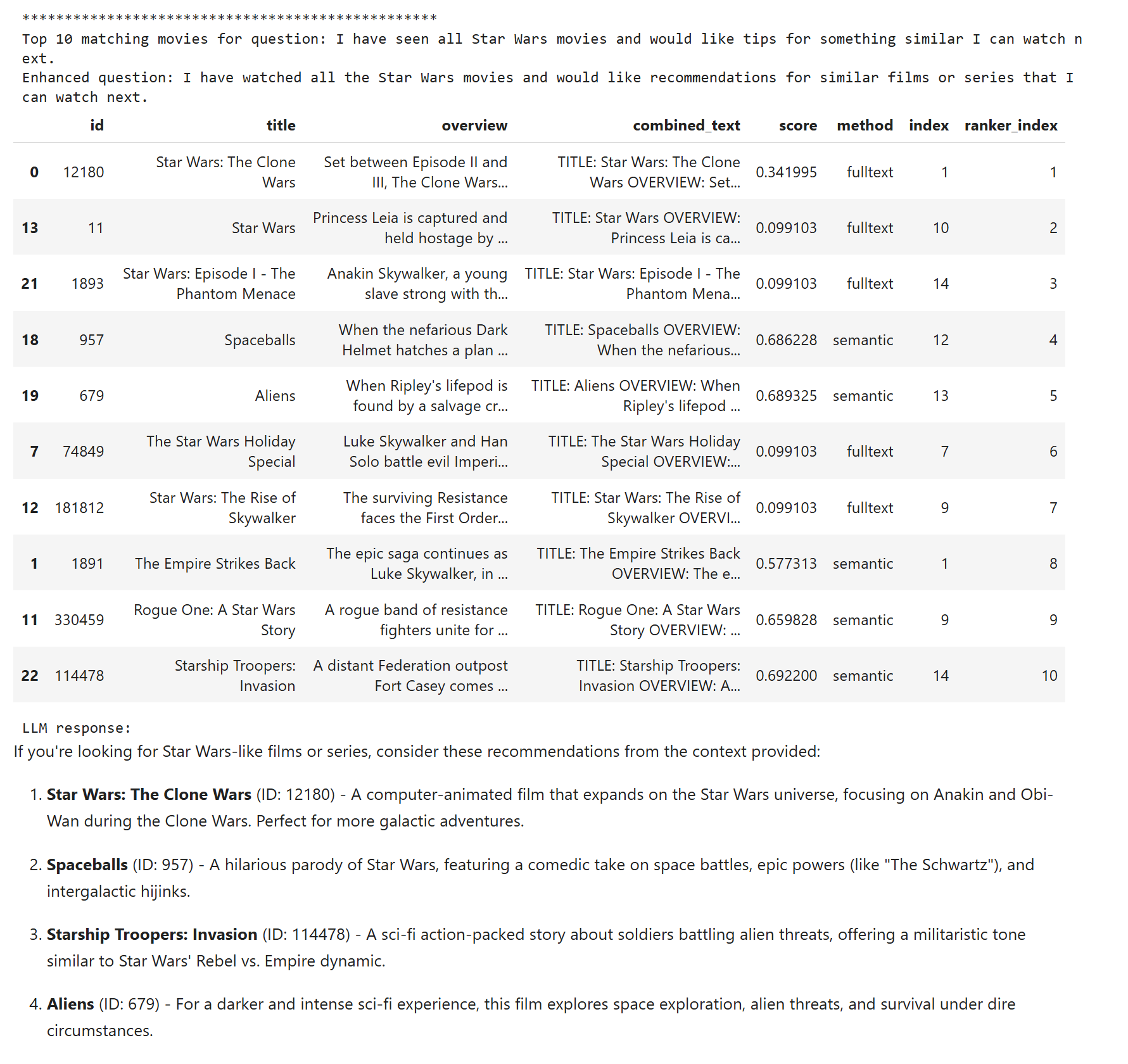
However, the other two queries are still bad. We are looking for movies like Star Wars, but not Star Wars, and full-text has no way to understand that, so it finds Star Wars movies we do not want. It looks like we need to search by meaning instead.
In machine learning it is common to simplify a world with huge variability and complexity into a smaller number of properties - essentially compress it in a lossy way. This is not zip compression; imagine something closer to MP3.
For text, imagine scores in several dimensions such as “degree of poetry” or “degree of humor”. If we use hundreds of such properties, they can represent the original text well. In machine learning we do not dictate to the AI what the dimensions should be; we let it learn them.
These vectors - lists of numbers, scores for individual properties and dimensions - are embeddings. They represent the original input and are used for semantic extraction from text, images, and even diffusion models.
How do we search in it? First I let the model create an embedding for every movie description and store it. When a query arrives, I also place it into the latent space and look for points most similar to the query.
The third variant in the notebook is semantic search, meaning vector similarity search over embeddings. It fails on the first question, movies where Abby is a character. I wanted to demonstrate that vectors are usually great, but when we need a concrete short factual detail like an invoice number, they are not ideal.
For the other two questions the results are definitely better, although Star Wars is still a problem. This time we do get similar sci-fi movies, but too many Star Wars movies remain. In simple scenarios there is not much we can do: the construction is too complex for the embedding alone.
As with full-text, it can make sense to rewrite the query. I again used a smaller LLM (gpt-4o-mini) to make the question clear, well formulated, and free of typos and grammar mistakes. For real user input this helps retrieval.
The known HyDE technique (Hypothetical Document Embedding) lets the LLM imagine a fictional document that would be an ideal source for answering the question. We then perform vector search using that document. It sometimes works very well because documents are not usually phrased as questions.
Clearly, semantic search is suitable for some questions, while classic full-text works better elsewhere. So let's use both and deploy hybrid search.
The SQL query grew a bit, but nothing terrible. First I run full-text search and return 15 results, then semantic search and again get 15 results. I add a sequence number, priority, and method column to both tables. Then I union them and deduplicate by movie ID. Finally I sort the filtered results by priority and cut them to 10 rows.
Hybrid search in PostgreSQL
WITH fulltext AS (
SELECT
id,
title,
overview,
combined_text,
ts_rank(full_text_search, plainto_tsquery('english', %s)) AS score,
'fulltext' AS method,
ROW_NUMBER() OVER (ORDER BY ts_rank(full_text_search, plainto_tsquery('english', %s)) DESC) AS index
FROM movies
ORDER BY score DESC
LIMIT 15
),
semantic AS (
SELECT
id,
title,
overview,
combined_text,
(embedding <=> azure_openai.create_embeddings('text-embedding-3-large', %s, 2000, max_attempts => 5, retry_delay_ms => 500)::vector) AS score,
'semantic' AS method,
ROW_NUMBER() OVER (ORDER BY (embedding <=> azure_openai.create_embeddings('text-embedding-3-large', %s, 2000, max_attempts => 5, retry_delay_ms => 500)::vector)) AS index
FROM movies
ORDER BY score
LIMIT 15
),
combined_results AS (
SELECT * FROM fulltext
UNION ALL
SELECT * FROM semantic
),
deduped_results AS (
SELECT DISTINCT ON (id)
id,
title,
overview,
combined_text,
score,
method,
index
FROM combined_results
)
SELECT * FROM deduped_results
ORDER BY index
LIMIT 10;
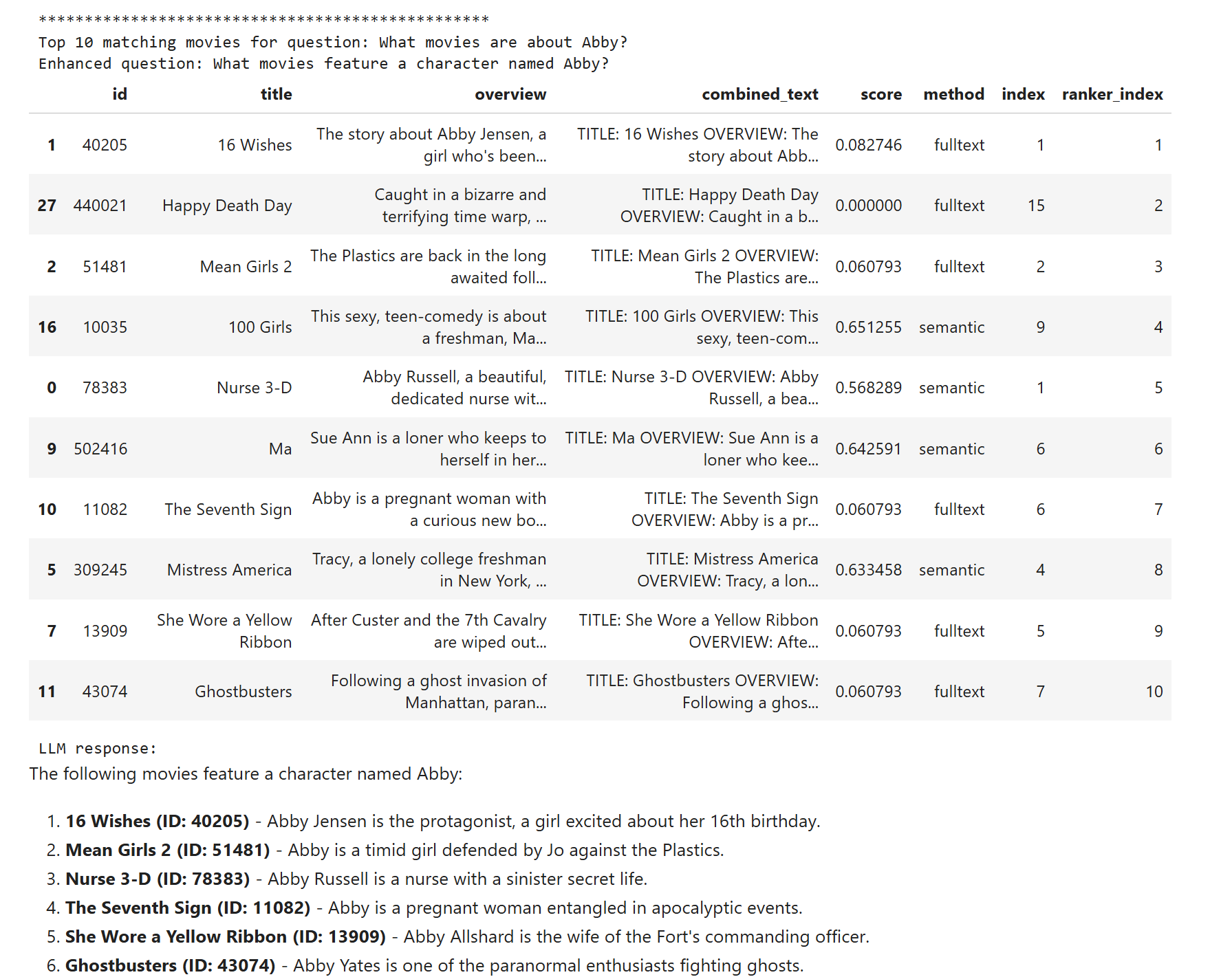
The Abby results are somewhere between full-text and semantic search, which makes sense. I removed the extreme bad cases: Abby via semantics and Star Wars via full-text.
Screenshot 2025-02-25-09-15-24
Now let us add another bit of magic: re-ranking. This is typically a small language model specifically trained to evaluate document relevance to a question.
It is too large to search with O(n) complexity over everything, but fast enough to examine a few dozen or hundred preselected results. Because it is not yet available as an extension for PostgreSQL in Azure Flexible Server, I do it on the server side in Python and use a simple MultiBERT model with about 33M parameters that runs comfortably on CPU.
The SQL query is the same; I just take all 30 results, let MultiBERT sort them by relevance, take the top 10 again, and send them to the LLM. The results are the best.
Abby is correct.
Screenshot 2025-02-25-09-21-01
Movies similar to Star Wars are a hard discipline, so the result is still not perfect, but compared with the other approaches it is the best.
Screenshot 2025-02-25-09-22-07
Where to go next
The RAG methods we tried together are not rocket science, but it is clear that the techniques significantly improve the results. Still, several problems remain.
Aggregate queries
not well covered because we do not have summarized data.
Information graph
concrete characters, actors, directors, genres, and relationships are beyond today's simple model.
Pre-processed data
next time we will need to extract attributes, connect them, and add summaries.
GraphRAG
this is exactly the direction to continue in.
That is what we will focus on next time: take the data, extract key attributes, connect them relationally, and add summarized and aggregated views.
I should also say that I used PostgreSQL because I am fascinated by its universality and extensibility, and it is the best way to learn what is happening.
However, I am somewhat reinventing the wheel. If you are in the cloud, try Azure AI Search directly. It includes not only what we did here but also other techniques. It is not only a storage and search solution, but also handles input processing such as indexing, extraction, chunking, and other RAG components we will discuss next time.
An LLM is not a database. Quality data and a smart way to access it are not a new problem for humanity - they help people, and they will help your AI agents too.