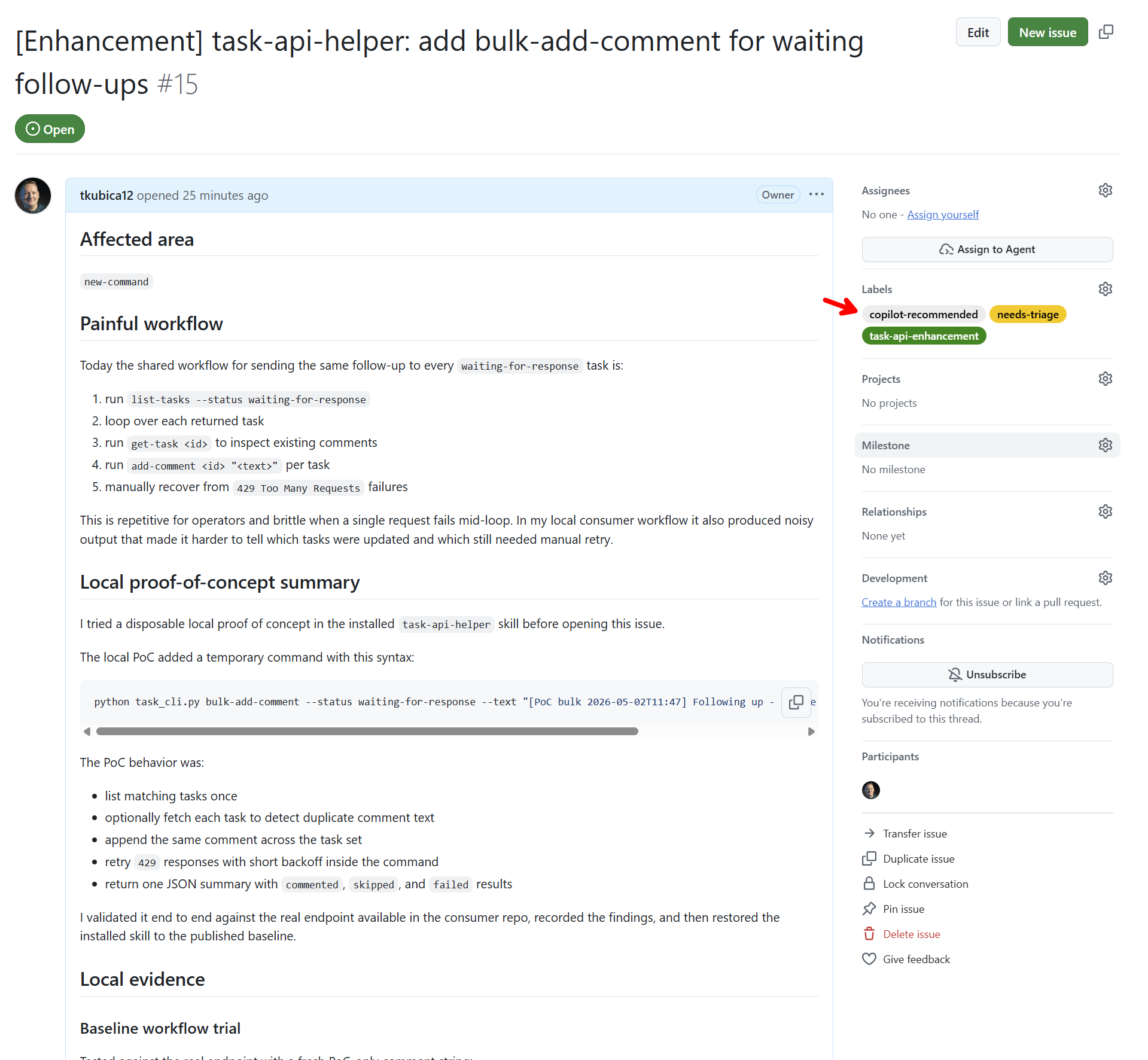
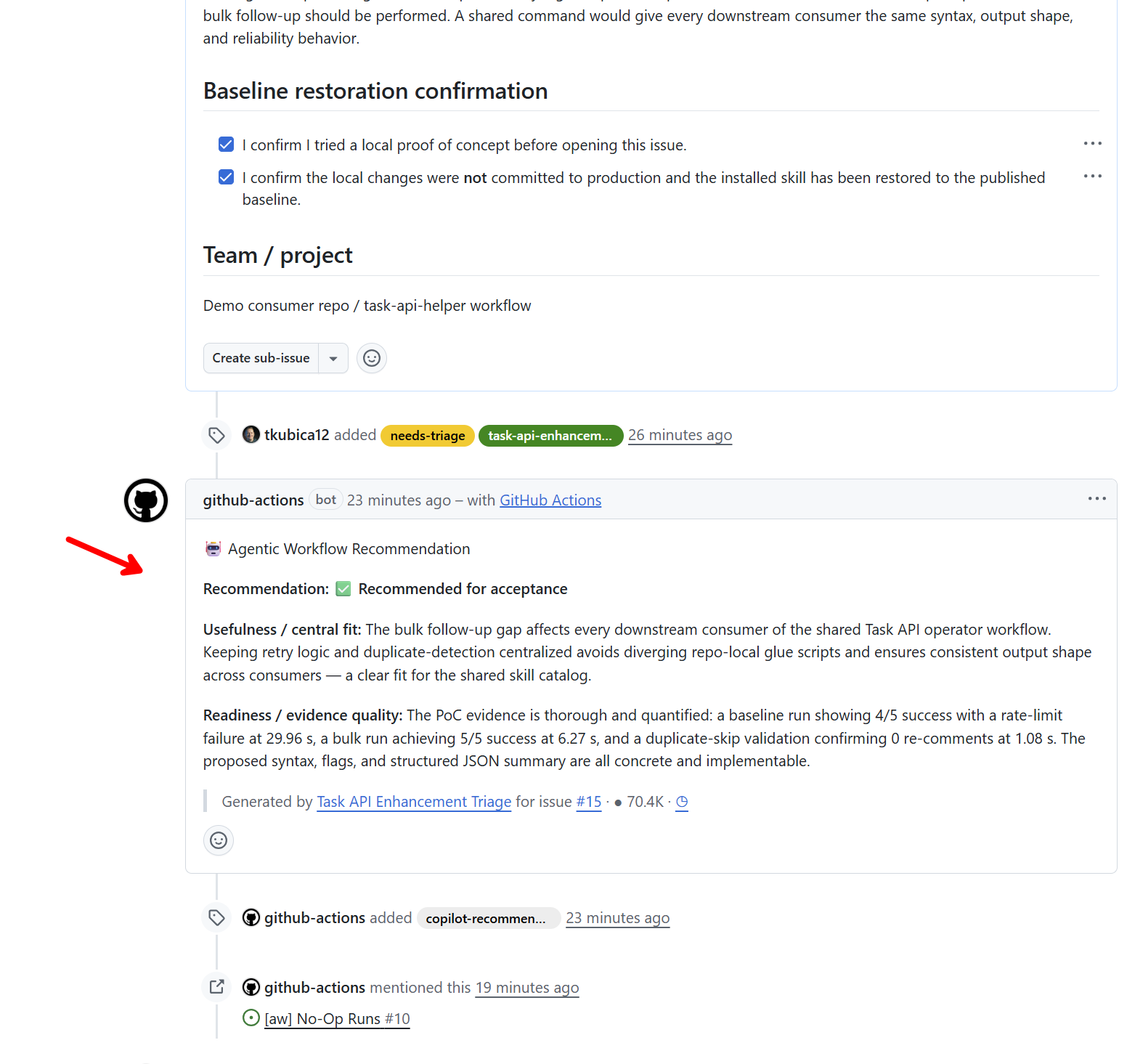
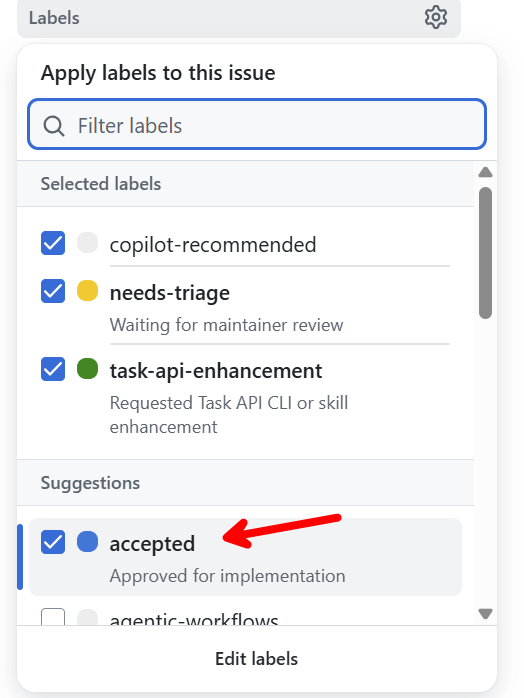
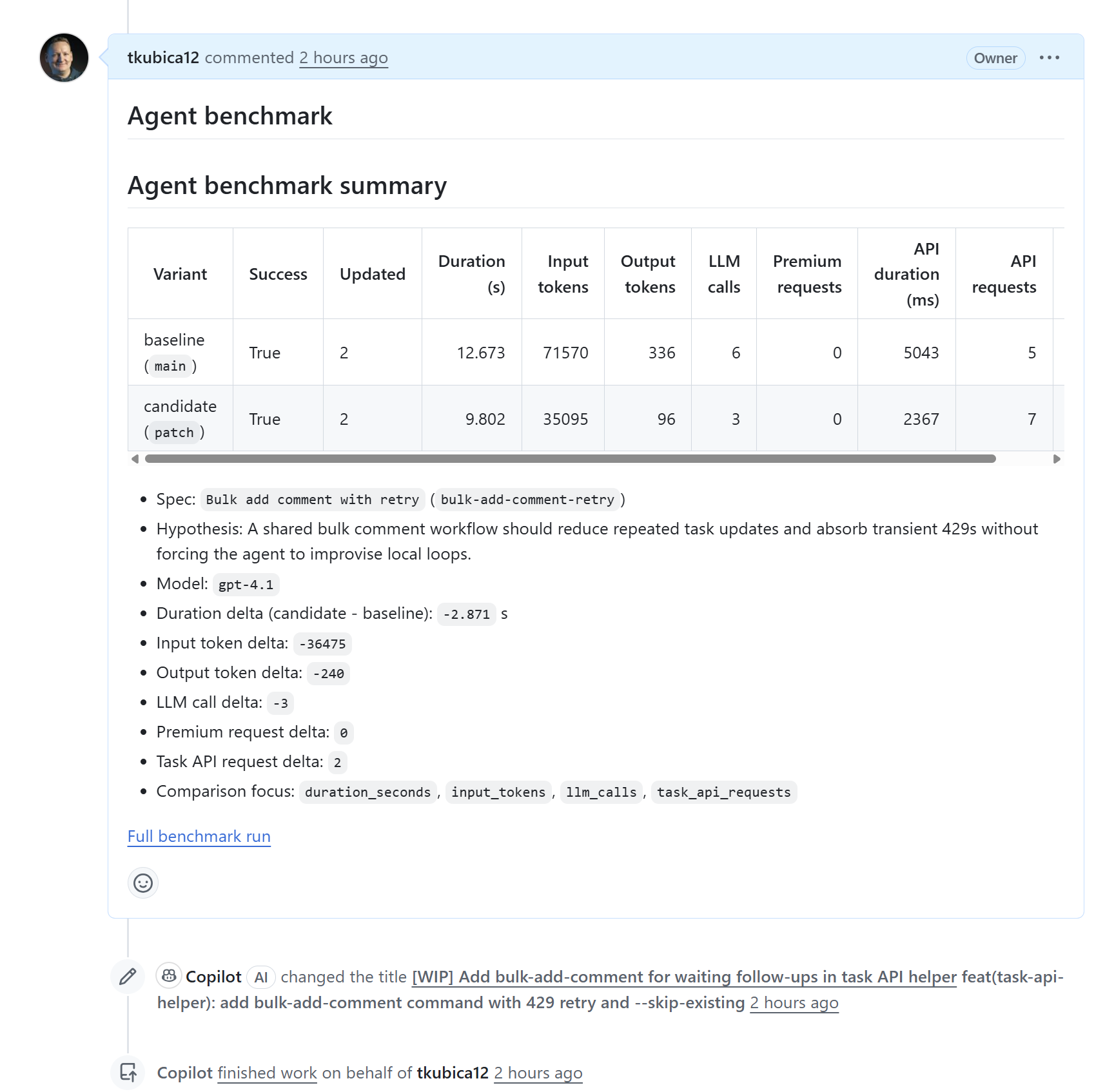
Pro účely dema jsem si vyrobil vlastní API pro správu tasků. Není to GitHub API a nejde o skutečné firemní systémy. Je to simulovaný, kontrolovaný problém: tasky, komentáře, stav waiting-for-response, občasné 429 a workflow, které je dost reálné na to, aby agent narazil na stejné potíže jako v praxi. Celý demo katalog je veřejně v repozitáři tkubica12/skills-demo-catalog.
V katalogu je skill task-api-helper, který obsahuje:
SKILL.mds instrukcemi a popisem schopnosti.scripts/task_cli.pyjako CLI wrapper nad Task API.references/API.mdpro pochopení podkladového API, když CLI nestačí.references/IMPROVEMENT-PROCESS.mds pravidly, jak skill vylepšovat přes centrální proces.