Deep dive do observability AI agentů s Microsoft Agent Framework - OpenTelemetry semantic conventions a použití OTEL kolektoru
AI agenti a multi-agentní workflow jsou pro debugging, nákladovost a bezpečnost citlivější než klasické CRUD API – bez dobré observability jen těžko zjistíte proč se odpovědi liší, kam mizí tokeny nebo kde roste latence. Cílem celé série je ukázat jak dostat maximum z otevřených standardů tak, abyste nemuseli přepisovat kód při změně backendu a přitom měli data kvalitně očištěná a levná.
Celé řešení najdete na mém GitHubu
Microsoft Agent Framework je výborný vývojový kit pro tvorbu AI agentů a multi-agentních řešení od jednoduchých scénářů až po orchestrační workflow (sekvenční nebo grafové postupy agentů) nebo plný multiagent přístup po vzoru Magentic (případně Group Chat a podobné topologie). Umí používat OpenAI, Foundry (včetně non-OpenAI modelů). Foundry agenty, externí agenty přes A2A, ale i vlastní řešení. V této sérii se zaměříme na observabilitu a závěry z ní můžete samozřejmě aplikovat i na jiné frameworky jako je Lang Graph. Všechno budeme stavět na otevřených standardech a jako vizualizační backendy využijeme různé platformy včetně open source projektů jako je Aspire Dashboard, LangFuse nebo Prometheus s Grafanou, ale i zabudované funkce v Azure platformě v rámci AI Foundry a Application Insights.
Pojďme ale postupně - dnes si probereme instrumentaci kódu a proč rád používám OpenTelemetry collector, který dávám mezi aplikaci a monitorovací řešení.
OpenTelemetry a sémantické konvence pro genAI
OpenTelemetry podporuje přidávání jakýchkoli atributů do trasování a to v minulosti vytvářelo poměrně zmatek, protože řešení jako je OpenInference, LangFuse nebo LangSmith pojmenovávali atributy různě a přestože tak máte OpenTelemetry standard, tak různé hotové reporty, vizualizace a analýzy nefungovaly univerzálně. Dnes ale existují tzv. semantic conventions pro GenAI, které Microsoft dodržuje a dokonce je před časem rozšířil pro atributy na multi-agent scénáře (už to bylo do standardu oficiálně přijato) a Microsoft Agent Framework tyto všechny dodržuje. Dokumentaci najdete na Semantic conventions for generative AI systems.
Výsledek pak vypadá nějak takhle:
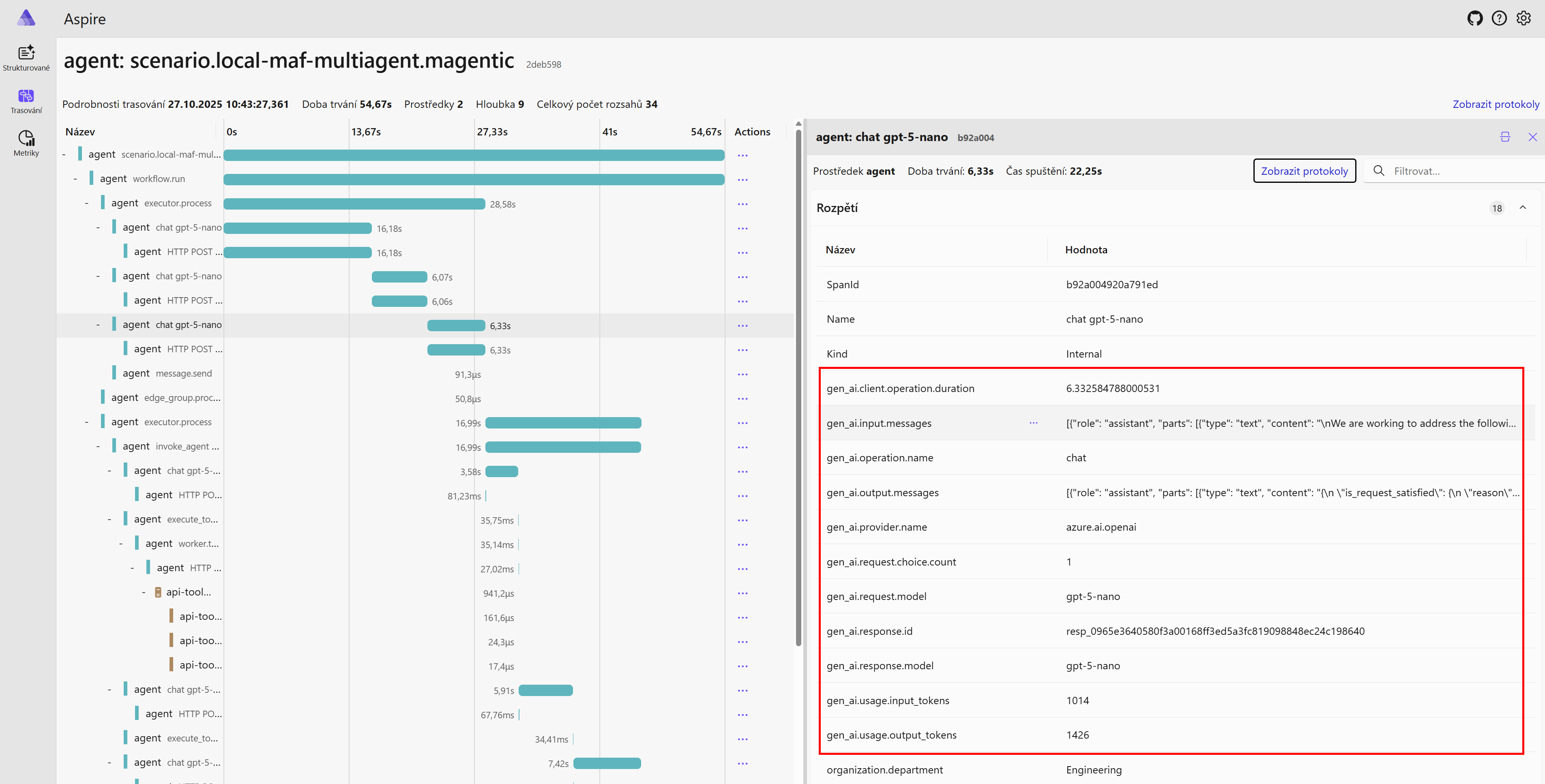
Instrumentace Microsoft Agent Frameworku
Zapnutí observability v Microsoft Agent Framework je v základním režimu otázka jediného příkazu a importu potřebných knihoven.
1
2
3
4
5
from agent_framework.observability import get_tracer, get_meter, setup_observability
setup_observability(
enable_sensitive_data=enable_sensitive,
otlp_endpoint=otlp_endpoint,
)
Jak uvidíte později v sérii, přidávám k tomu něco navíc z následujících důvodů:
- Chci do spanů integrovat vlastní dynamické atributy, abych podle nich mohl dělat agregace nebo vyhledávání. Typicky jde o user id, session id, uživatelské role, experiment. V kombinaci se statickými atributy (typ modelu, název agenta) mi tak pak umožňuje například počítat náklady per uživatel, per uživatelská role, hledat podle session či experimentovat a verzovat a filtrovat tak zprávy pro jednotlivé experimenty (to souvisí s evaluations - velmi příbuzné téma)
- Chci do vnitřních spanů propisovat svoje custom atributy tak, aby se mi na backendu lépe filtrovalo (byť tím zvyšuji náklady) a přidávám tzv. baggage procesor
- Kromě trasování chci posílat i aplikační logy a metriky a to včetně mých vlastních, takže to také vyžaduje přidat do instrumentace
- Kromě AI komponent chci instrumentovat i jiné věci v aplikaci týkající se provozu agenta - zejména různá HTTP volání a přístupy do dat typu Redis, SQL, PostgreSQL. Nemusí se to instrumentovat ručně, ale pro každou technologii potřebuji natáhnout příslušný autoinstrumentační procesor.
Rozšíření o vlastní atributy
S využitím baggage span procesoru to není těžké, navíc zdá se, že tento kontext odchází i v headeru při HTTP komunikaci, takže se atributů lze chytit například v zavolaném nástroji, pokud bychom chtěli.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# Add BaggageSpanProcessor to automatically propagate baggage to all spans
from opentelemetry import trace as trace_api
tracer_provider = trace_api.get_tracer_provider()
if hasattr(tracer_provider, 'add_span_processor'):
baggage_processor = BaggageSpanProcessor()
tracer_provider.add_span_processor(baggage_processor)
logger.info("BaggageSpanProcessor registered for automatic context propagation")
from opentelemetry import baggage, context
ctx = context.get_current()
ctx = baggage.set_baggage("user.id", user_context.get("user.id", "unknown"), ctx)
ctx = baggage.set_baggage("session.id", user_context.get("session.id", "unknown"), ctx)
ctx = baggage.set_baggage("organization.department", user_context.get("organization.department", "unknown"), ctx)
roles = user_context.get("user.roles", [])
if roles:
ctx = baggage.set_baggage("user.roles", ",".join(roles), ctx)
token = context.attach(ctx)
OpenTelemetry kolektor - rozhazování do nástrojů, anonymizace, filtrace, konverze
Tady se dnes zastavíme o trochu déle. OpenTelemetry SDK má institut exportéru a tím je konkrétní implementace backendu, pokud je jiná, než standardní OpenTelemetry endpoint (App Insights používají na backendu jiný formát, ale OTEL endpoint podporuje třeba Honeycomb, SigNoz, Uptrace, Tempo, New Relic, Datadog, AppDynamics nebo Dynatrace). Nicméně existuje také OpenTelemetry collector, který dokáže sloužit jako endpoint pro aplikace/agenty a posílat údaje do backendů. Proč rád používám kolektor?
Je to centrální rozbočovač telemetrie – jeden stabilní OTLP endpoint pro aplikaci a všechna ostatní kouzla (routing, anonymizace, sampling, více backendů, převody) se dějí mimo kód. Tím pádem buildím agenty jednou a provozní strategie můžu ladit rychle iteracemi jen úpravou konfigurace collectoru.
- Odděluji konfiguraci v aplikaci od backendů, takže lze mít zcela univerzální kontejner s jedním OTEL endpointem konfigurovaným přes env a o zbytek se postará kolektor - autentizace k backendu, jiný backend pro různé clustery, scénáře, lokální debug a tak podobně
- Můžu mít snadno víc destinací, například mám rád použití Aspire Dashboard (z dílny .NETu, ale standalone funguje jako plně samostatné řešení), který je jednoduchý, podporuje logy, trasování i metriky a běží jako jeden jediný kontejner s pěkným UI. Rychlé (vše je tam vidět okamžitě), jednoduché, běží kdekoli. To mám rád pro rychlý troubleshooting. Na analytiku a dlouhodobé uložení pak mám App Insights.
- Dají se provádět různé transformace jako je filtrování atributů a odstraňování osobních informací. To je také velmi užitečné. Dají se tak udělat třeba tyto tři kategorie destinací a to bez zásahu do aplikace.
- “Enterprise” logy v Azure (auditovatelnost a tak podobně), ale bez samotného obsahu zpráv (takže ano pro user id a další identifikátory, ale ne pro samotný obsah konverzací). Slouží pro provoz, analýzu, SRE.
- “AI observability” logy, kde je i plný obsah konverzací, ale pouze u uživatelů z určité skupiny (např. ti, co zaškrtli, že souhlasí s použitím konverzací na vylepšování řešení). Slouží pro evaluace.
- “Dev” logy, kde jsou zamaskovány veškeré údaje vedoucí k identifikaci (user id, email, IP adresa, samozřejmě obsah zpráv). Slouží běžně pro vývojáře pro rychlý náhled na latence, tokeny, problémy.
- Potenciálně zlepšuje výkon, protože aplikace “odloží” vše do blízkého kolektoru (typicky ve stejném Kubernetes nebo Container App clusteru) a kolektor se postará o doručení do cloudových backendů včetně bufferování a retry.
- Pokročilé konverze přes jazyk OTTL (OpenTelemetry Transformation Language) jako různá přejmenovávání či přepočty atributů (např. pro účely standardizace), obohacení dat, převod metrik z tracing na metriku a tak podobně.
- Sampling pro snížení množství dat, kdy můžete dělat chytrá rozhodnutí jako je posílání plného trasování pro kritické uživatele, ale jen malý vzorek pro běžné uživatele (například Application Insights se platí podle objemu vstupů, takže sampling pouhého 1% uživatelských dotazů znamená 99% úsporu nákladů). Sampling navíc dokážete dělat chytře - nejen procentem nebo pravděpodobnostně (ta se dynamicky určuje podle počtu zpráv), ale různé tail-based mechanismy. Jste tak například schopni držet data v kolektoru po nějakou dobu, analyzovat a poslat pouze vybrané - například ty, které měly chybu nebo trvaly moc dlouho. Kolektor tak dokáže mít pravidla, kterými (samozřejmě za cenu zpoždění v délce časového okna, třeba minuty) můžete vybrat ty nejdůležitější události - šetřit na backendu a přitom tam mít vše podstatné.
Pro PII pseudonymizaci umí OTTL kombinovat operace typu set, delete_key, delete_matching_keys, replace_all_patterns a hashování (SHA256()) – ideálně se SALTem z env proměnné pro odolnost proti slovníkovým útokům.
Příklad tail‑based samplingu (jen ilustrace – zapojili byste ho do processors a traces pipeline):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
processors:
tail_sampling:
decision_wait: 30s # jak dlouho držím buffery
num_traces: 50000 # cílové množství in-memory
expected_new_traces_per_sec: 200
policies:
- name: errors
type: status_code
status_code:
status_codes: [ERROR]
- name: slow
type: latency
latency:
threshold_ms: 2000 # nad 2s vždy zachovat
- name: vip_users
type: string_attribute
string_attribute:
key: user.is_vip
values: ["true"]
- name: baseline_sample
type: probabilistic
probabilistic:
hash_seed: 22
sampling_percentage: 5
service:
pipelines:
traces:
receivers: [otlp]
processors: [memory_limiter, tail_sampling, batch]
exporters: [otlp, azuremonitor]
Výborné je, že tohle všechno lze nastavit v ConfigMap, pokud používáte Azure Kubernetes Service. Moje vypadá zatím takhle:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ include "maf-demo.fullname" . }}-otel-collector-config
labels:
{{- include "maf-demo.labels" . | nindent 4 }}
app.kubernetes.io/component: otel-collector
data:
config.yaml: |
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
processors:
batch:
timeout: 5s
send_batch_size: 1024
memory_limiter:
check_interval: 1s
limit_mib: 512
# Transform processor for anonymization - strips PII and sensitive data
transform/anonymize:
error_mode: ignore
trace_statements:
- context: span
statements:
# Pseudonymize user.id using SHA256 for consistent hashing
- set(attributes["user.id"], SHA256(attributes["user.id"])) where attributes["user.id"] != nil
# Remove VIP status - boolean flag considered PII
- delete_key(attributes, "user.is_vip")
- delete_key(attributes, "user.roles")
# Pseudonymize department for correlation while protecting identity
- set(attributes["organization.department"], SHA256(attributes["organization.department"])) where attributes["organization.department"] != nil
# Pseudonymize session and thread IDs
- set(attributes["session.id"], SHA256(attributes["session.id"])) where attributes["session.id"] != nil
- set(attributes["thread.id"], SHA256(attributes["thread.id"])) where attributes["thread.id"] != nil
# Strip tool arguments and results - may contain sensitive data
- delete_key(attributes, "tool.arguments")
- delete_key(attributes, "tool.result")
# Strip GenAI input/output messages - contains user queries and LLM responses
- delete_key(attributes, "gen_ai.input.messages")
- delete_key(attributes, "gen_ai.output.messages")
- delete_key(attributes, "gen_ai.prompt")
- delete_key(attributes, "gen_ai.completion")
- delete_key(attributes, "gen_ai.request.model")
- delete_key(attributes, "gen_ai.response.model")
# Strip any other GenAI content using pattern matching
- delete_matching_keys(attributes, "gen_ai\\..*\\.content")
- delete_matching_keys(attributes, "gen_ai\\..*messages.*")
# Redact common PII patterns in remaining string attributes
- replace_all_patterns(attributes, "value", "\\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\\.[A-Z|a-z]{2,}\\b", "EMAIL_REDACTED")
- replace_all_patterns(attributes, "value", "\\b\\d{3}[-.]?\\d{3}[-.]?\\d{4}\\b", "PHONE_REDACTED")
- replace_all_patterns(attributes, "value", "\\b\\d{4}[\\s-]?\\d{4}[\\s-]?\\d{4}[\\s-]?\\d{4}\\b", "CARD_REDACTED")
- context: resource
statements:
# Pseudonymize user.id in resource attributes
- set(attributes["user.id"], SHA256(attributes["user.id"])) where attributes["user.id"] != nil
# Remove VIP status from resource
- delete_key(attributes, "user.is_vip")
- delete_key(attributes, "user.roles")
# Pseudonymize department in resource
- set(attributes["organization.department"], SHA256(attributes["organization.department"])) where attributes["organization.department"] != nil
# Pseudonymize session in resource
- set(attributes["session.id"], SHA256(attributes["session.id"])) where attributes["session.id"] != nil
log_statements:
- context: log
statements:
# Pseudonymize user identifiers in logs
- set(attributes["user.id"], SHA256(attributes["user.id"])) where attributes["user.id"] != nil
# Remove sensitive log attributes
- delete_key(attributes, "user_message")
- delete_key(attributes, "response")
- delete_key(attributes, "tool_name")
- delete_key(attributes, "arguments")
- delete_key(attributes, "result")
- delete_key(attributes, "user.is_vip")
- delete_key(attributes, "user.roles")
# Pseudonymize department and session
- set(attributes["organization.department"], SHA256(attributes["organization.department"])) where attributes["organization.department"] != nil
- set(attributes["session.id"], SHA256(attributes["session.id"])) where attributes["session.id"] != nil
# Redact PII patterns in log body if it's a string
- replace_all_patterns(attributes, "value", "\\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\\.[A-Z|a-z]{2,}\\b", "EMAIL_REDACTED") where IsString(body)
- replace_all_patterns(attributes, "value", "\\b\\d{3}[-.]?\\d{3}[-.]?\\d{4}\\b", "PHONE_REDACTED") where IsString(body)
- context: resource
statements:
# Pseudonymize user.id in resource attributes for logs
- set(attributes["user.id"], SHA256(attributes["user.id"])) where attributes["user.id"] != nil
# Pseudonymize department in resource for logs
- set(attributes["organization.department"], SHA256(attributes["organization.department"])) where attributes["organization.department"] != nil
metric_statements:
- context: datapoint
statements:
# Pseudonymize user identifiers in metrics
- set(attributes["user.id"], SHA256(attributes["user.id"])) where attributes["user.id"] != nil
# Remove VIP status from metrics
- delete_key(attributes, "user.is_vip")
# Pseudonymize department in metrics
- set(attributes["organization.department"], SHA256(attributes["organization.department"])) where attributes["organization.department"] != nil
- context: resource
statements:
# Pseudonymize user.id in resource attributes for metrics
- set(attributes["user.id"], SHA256(attributes["user.id"])) where attributes["user.id"] != nil
# Remove VIP status from resource for metrics
- delete_key(attributes, "user.is_vip")
# Pseudonymize department in resource for metrics
- set(attributes["organization.department"], SHA256(attributes["organization.department"])) where attributes["organization.department"] != nil
exporters:
# Console exporter for troubleshooting
debug:
verbosity: detailed
sampling_initial: 5
sampling_thereafter: 200
# OTLP exporter for Aspire Dashboard
otlp:
endpoint: {{ include "maf-demo.fullname" . }}-aspire-dashboard:18889
tls:
insecure: true
# OTLP exporter for Anonymized Aspire Dashboard
otlp/anonymized:
endpoint: {{ include "maf-demo.fullname" . }}-aspire-dashboard-anon:18889
tls:
insecure: true
# Azure Monitor exporter for Application Insights
# Supports traces and logs (metrics not supported by App Insights OTLP ingestion)
azuremonitor:
connection_string: {{ .Values.appInsights.connectionString | quote }}
# Langfuse OTLP exporter for LLM observability
# Exports traces to Langfuse via HTTP/protobuf protocol
otlphttp/langfuse:
endpoint: {{ .Values.langfuse.endpoint | default "http://langfuse-web.langfuse.svc.cluster.local:3000/api/public/otel" | quote }}
headers:
Authorization: {{ .Values.langfuse.authorization | default "Basic " | quote }}
# Prometheus Remote Write exporter for Azure Monitor Prometheus
# Uses sidecar container for Azure AD token management
# The sidecar listens on localhost:8081 and injects the Authorization header
prometheusremotewrite:
endpoint: "http://localhost:8081/api/v1/write"
tls:
insecure: true
resource_to_telemetry_conversion:
enabled: true
service:
pipelines:
traces:
receivers: [otlp]
processors: [memory_limiter, batch]
exporters: [otlp, azuremonitor, otlphttp/langfuse]
# Anonymized trace pipeline - strips PII before sending to anonymized dashboard
traces/anonymized:
receivers: [otlp]
processors: [memory_limiter, transform/anonymize, batch]
exporters: [otlp/anonymized]
metrics:
receivers: [otlp]
processors: [memory_limiter, batch]
exporters: [otlp, prometheusremotewrite]
# Anonymized metrics pipeline
metrics/anonymized:
receivers: [otlp]
processors: [memory_limiter, transform/anonymize, batch]
exporters: [otlp/anonymized]
logs:
receivers: [otlp]
processors: [memory_limiter, batch]
exporters: [otlp, azuremonitor]
# Anonymized logs pipeline
logs/anonymized:
receivers: [otlp]
processors: [memory_limiter, transform/anonymize, batch]
exporters: [otlp/anonymized]
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: {{ include "maf-demo.fullname" . }}-otel-collector
labels:
{{- include "maf-demo.labels" . | nindent 4 }}
app.kubernetes.io/component: otel-collector
azure.workload.identity/use: "true"
annotations:
azure.workload.identity/client-id: {{ .Values.agent.clientId }}
azure.workload.identity/tenant-id: {{ .Values.agent.tenantId }}
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ include "maf-demo.fullname" . }}-otel-collector
labels:
{{- include "maf-demo.labels" . | nindent 4 }}
app.kubernetes.io/component: otel-collector
spec:
replicas: 1
selector:
matchLabels:
{{- include "maf-demo.otelCollectorSelectorLabels" . | nindent 6 }}
template:
metadata:
labels:
{{- include "maf-demo.otelCollectorSelectorLabels" . | nindent 8 }}
azure.workload.identity/use: "true"
spec:
serviceAccountName: {{ include "maf-demo.fullname" . }}-otel-collector
containers:
- name: otel-collector
image: otel/opentelemetry-collector-contrib:{{ .Values.otelCollector.tag }}
ports:
- containerPort: 4317 # OTLP gRPC
name: otlp-grpc
protocol: TCP
- containerPort: 4318 # OTLP HTTP
name: otlp-http
protocol: TCP
- containerPort: 8888 # Metrics
name: metrics
protocol: TCP
- containerPort: 8889 # Prometheus metrics
name: prometheus
protocol: TCP
volumeMounts:
- name: config
mountPath: /etc/otelcol-contrib
readOnly: true
resources:
{{- toYaml .Values.otelCollector.resources | nindent 10 }}
# Sidecar container for Azure Monitor Prometheus remote write authentication
# This container obtains Azure AD tokens using workload identity and proxies
# Prometheus remote write requests with the Authorization header injected
- name: prom-remotewrite
image: mcr.microsoft.com/azuremonitor/containerinsights/ciprod/prometheus-remote-write/images:prom-remotewrite-20250814.1
imagePullPolicy: Always
ports:
- name: rw-port
containerPort: 8081
protocol: TCP
env:
- name: INGESTION_URL
value: {{ .Values.prometheus.remoteWriteEndpoint | quote }}
- name: LISTENING_PORT
value: "8081"
- name: IDENTITY_TYPE
value: "workloadIdentity"
- name: CLUSTER
value: {{ .Values.clusterName | default "aks-cluster" | quote }}
livenessProbe:
httpGet:
path: /health
port: rw-port
initialDelaySeconds: 10
timeoutSeconds: 10
readinessProbe:
httpGet:
path: /ready
port: rw-port
initialDelaySeconds: 10
timeoutSeconds: 10
resources:
requests:
cpu: 50m
memory: 64Mi
limits:
cpu: 200m
memory: 128Mi
volumes:
- name: config
configMap:
name: {{ include "maf-demo.fullname" . }}-otel-collector-config
---
apiVersion: v1
kind: Service
metadata:
name: {{ include "maf-demo.fullname" . }}-otel-collector
labels:
{{- include "maf-demo.labels" . | nindent 4 }}
app.kubernetes.io/component: otel-collector
spec:
type: ClusterIP
ports:
- port: 4317
targetPort: otlp-grpc
protocol: TCP
name: otlp-grpc
- port: 4318
targetPort: otlp-http
protocol: TCP
name: otlp-http
- port: 8888
targetPort: metrics
protocol: TCP
name: metrics
selector:
{{- include "maf-demo.otelCollectorSelectorLabels" . | nindent 4 }}
Pokud nechcete dělat věci složitě, použijte Azure Container Apps místo AKS. Aplikace a agenty tam lze provozovat velmi snadno a systém má přímo zabudovaný OpenTelemetry kolektor, který snadno nastavíte v portálu nebo Terraformem/Bicepem. Nemáte možnost používat složité transformace (nicméně pro to není problém tam spustit vlastní kolektor), ale napojení na různé backendy vyřešíte velmi elegantně a automatizovatelně.
Příště si vyzkoušíme metriky a logy a pak už se vrhneme hloubkově na trasování.