Deep dive do observability AI agentů s Microsoft Agent Framework - metriky a logy, konverze na managed Prometheus a Grafana v Azure
Tracing je pro AI agenty nejdůležitější disciplínou, ale logy a metriky také mají svoje místo. Klasické logy lze doručovat přes OpenTelemetry a konečně tak krásně sjednotit logovací cesty případně je korelovat s trasováním. No a metriky? Hloubkové analýzy, složité query a skvělé možnosti filtrací a agregací v UI jsou fajn, ale často uvítáte jednoduchou vizualizaci v Grafaně. Žádné složitosti - klíčové metriky přes základní dimenze. I to jste dnes schopni řešit přes OpenTelemetry s kolektorem.
V prvním dílu série jsme se zaměřili na sémantické konvence GenAI v OpenTelemetry a základní instrumentaci Microsoft Agent Frameworku včetně důvodů použití kolektoru. Na to nyní navazujeme praktičtější částí o metrikách a logování.
Proč řešit metriky a ne jen trasování
Jak už jsem naznačoval trasování a logování jsou poměrně hutné disciplíny o to jak co do vyhodnocení výsledků, tak co do ceny cloudové služby nebo prostoru ve storage. Metriky jsou jednodušší z několika pohledů.
Backend používá typicky nějakou time-series databázi a to je případ jak slavného Promethea, tak třeba Mimir od Grafana nebo Azure Monitoru. Tyto databáze jsou optimalizované na časové řady s dimenzemi a jsou tak velmi rychlé a ve finále levné. Je to díky tomu, že uložení jako log se budou často opakovat metadata a databáze bude řádkově orientovaná (optimalizovaná na přidávání, filtrace, tedy operace přes řádky). Metriky jsou uspořádané jinak a dokonce i hodnoty samotné se komprimují například přes XOR - časové řady jsou si často podobné (např. o něco rostou nebo oscilují kolem nějaké hodnoty), takže velká bitová část odečtu (čísla) se opakuje a lze ji vynechat (říká se, že samotné metriky lze běžně komprimovat 8x - a k tomu přidejme to efektivní uložení, kde se neopakují metadata).
Dotazovací jazyky jsou podle mě taky jednodušší. Když srovnám PromQL (zlatý standard, který umí jak samotný Prometheus tak i Azure Monitor for Prometheus nebo Mimir) s jazyky pro logy či trasování (KQL v Azure, QL u Elastic, SPL u Splunk, LogQL u Loki), metriky pochopím o dost rychleji. Navíc v grafických nástrojích si většinu věcí jednoduše naklikáte (například Grafana dashboard), což u logovadel snadné není (tam snadno filtrujete, ale agregační dotazy jsou složitější).
Ve finále tedy Metriky chci!
Pro AI agenty se nejčastěji osvědčuje mít counter pro vstupní/výstupní tokeny (odvození nákladů přes cenu na token v dashboardu), histogram pro latenci požadavků kvůli p95/p99 tail analýze a counter pro chyby s dimenzí typu chyby. Vyhýbejte se ukládání plných promptů nebo volných textů do metrik – patří do trasování nebo řízených logů s anonymizací. Sledujte kardinalitu: model version, scénář a uživatelská role jsou většinou bezpečné, zatímco per-user či per-session metriky rychle rostou.
Instrumentace
Microsoft Agent Framework emituje nejjednodušší metriky v rámci své instrumentace, takže se na ně stačí jen koukat.
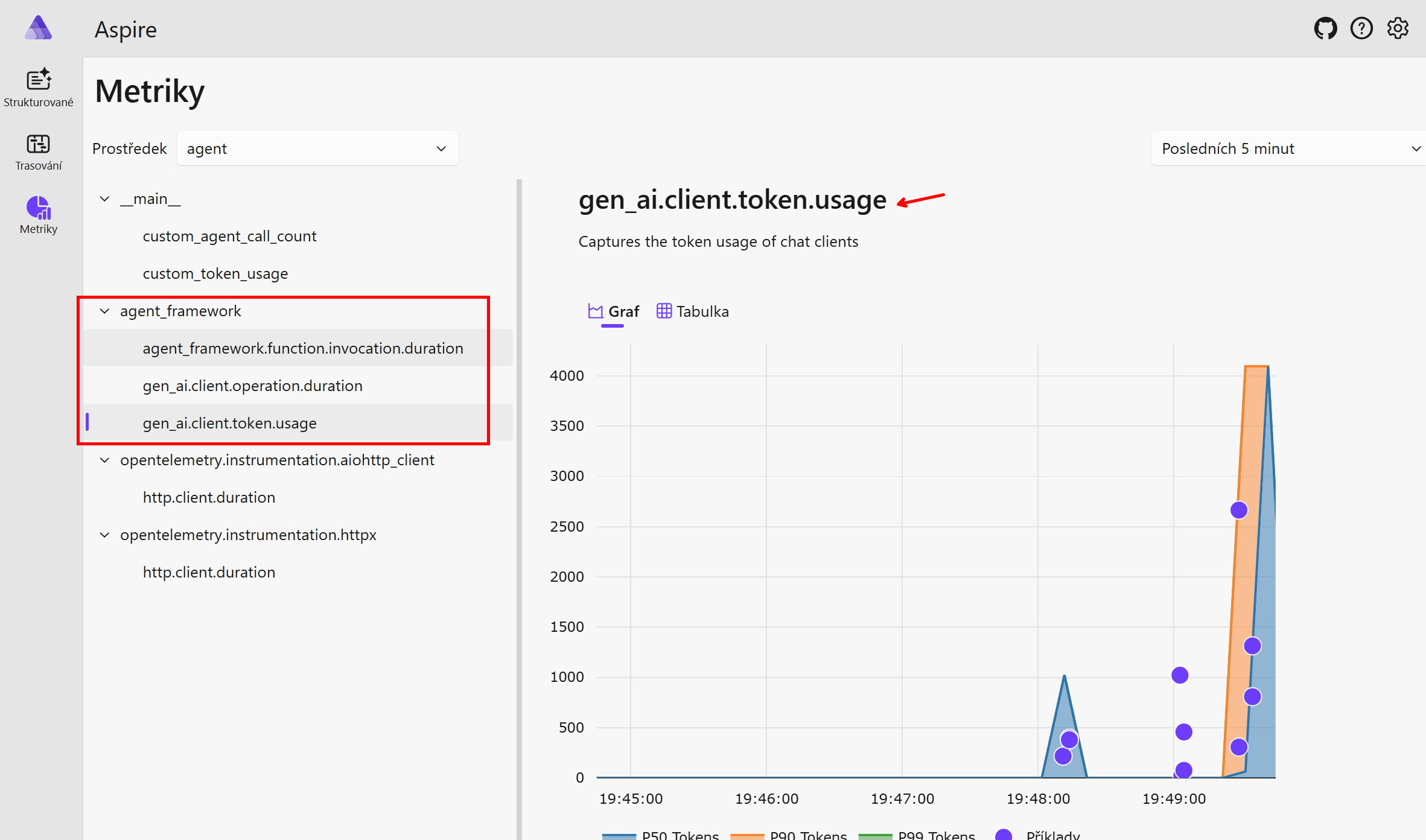
Tady jsou zabudované dimenze, podle kterých lze snadno filtrovat a měnit vizualizaci. Například vstupní a výstupní tokeny, použitý LLM model, provider, endpoint.
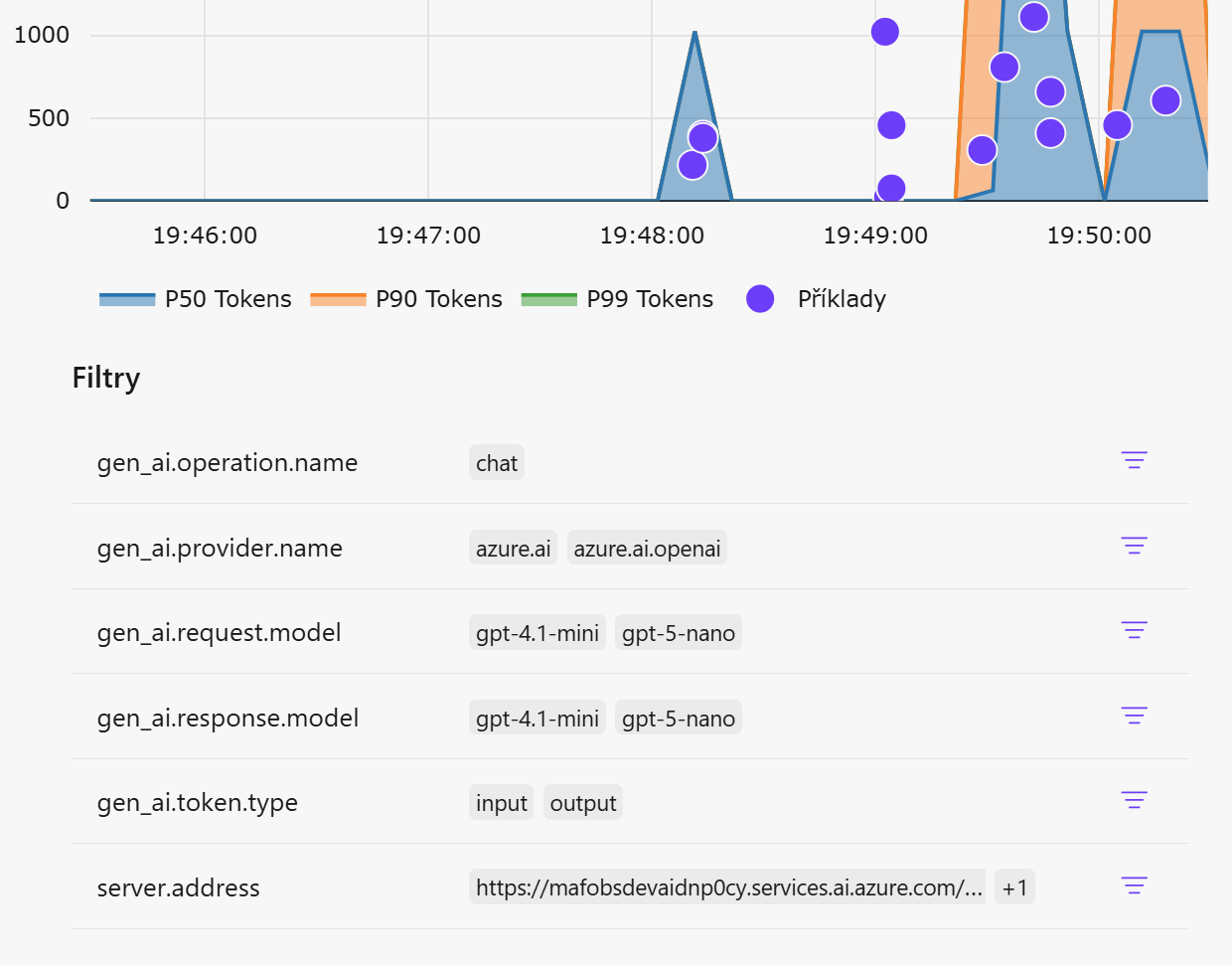
Dobré ale je, že mohu poměrně snadno přidat svoje vlastní metriky a jejich dimenze. Typicky to budou byznys metriky jako je počet zpracovaných objednávek a tak podobně. Já jsem se rozhodl udělat si vlastní metriku na počet tokenů. Rozšířit ty stávající se mi zdálo hodně komplikované (na rozdíl od možnosti přidat atributy do trasování), tak jsem si udělal svoje a přidal k nim další dimenze.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
metric_resource = Resource(attributes={
SERVICE_NAME: os.getenv("OTEL_SERVICE_NAME", "agent")
})
metric_reader = PeriodicExportingMetricReader(
OTLPMetricExporter(endpoint=otlp_endpoint, insecure=True),
export_interval_millis=5000, # Export every 5 seconds for testing
)
meter_provider = MeterProvider(resource=metric_resource, metric_readers=[metric_reader])
otel_metrics.set_meter_provider(meter_provider)
is_vip = "vip" in user_context.get("user.roles", [])
self.agent_call_counter.add(
demo_value,
attributes={
"service.name": os.getenv("OTEL_SERVICE_NAME", "agent"),
"user.id": user_context.get("user.id", "unknown"),
"user.is_vip": str(is_vip).lower(),
"organization.department": user_context.get("organization.department", "unknown"),
"session.id": user_context.get("session.id", "unknown"),
"scenario_id": "local-maf-multiagent",
"scenario_type": "multi-agent",
"orchestration": "magentic",
}
)
print(f"📊 Custom metric recorded: custom_agent_call_count={demo_value}")
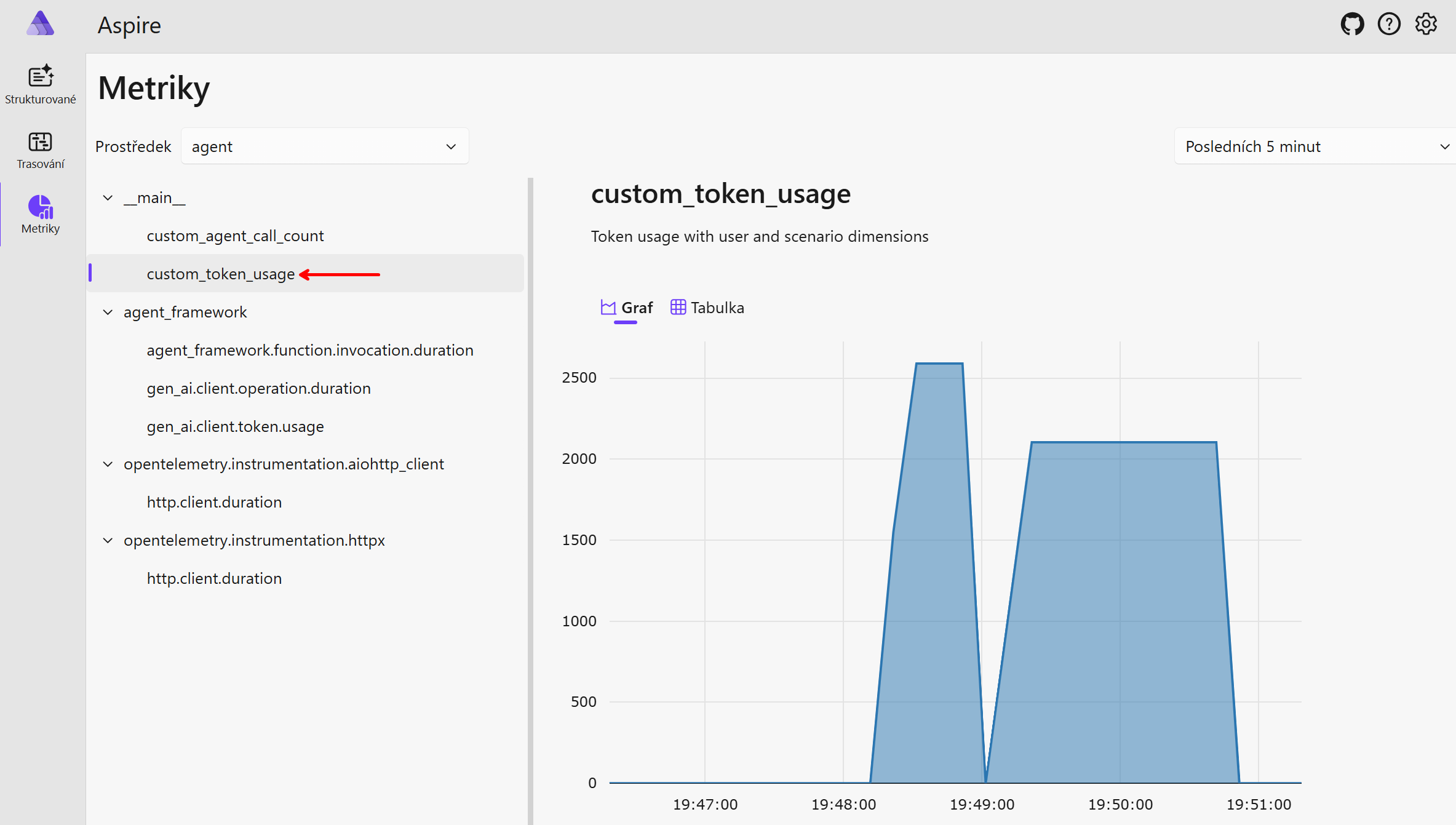
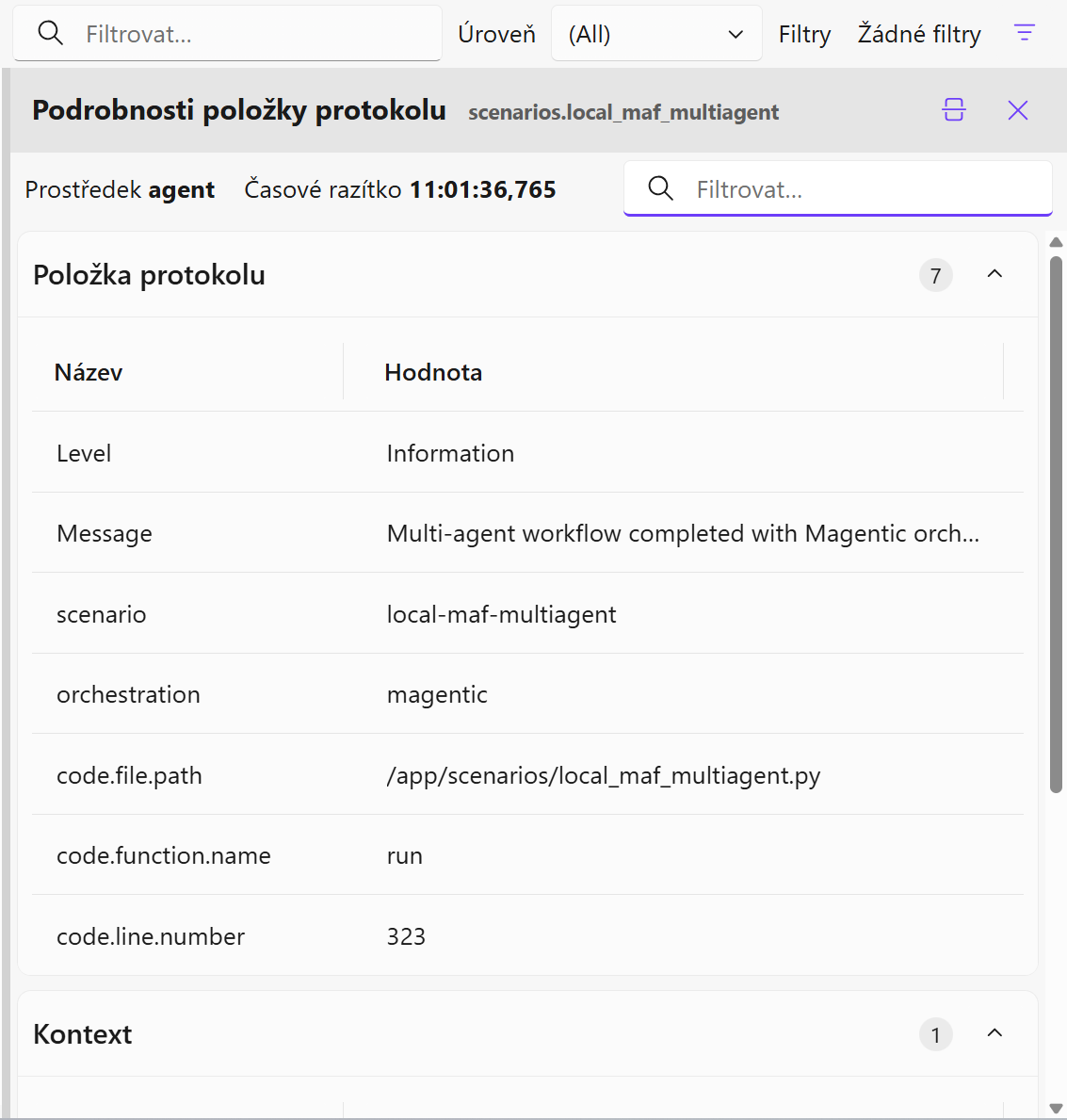
Vidíme tam i moje přidané dimenze, podle kterých lze snadno filtrovat a vizualizovat.
Poznámka ke kardinalitě: dimenze jako user.id a session.id jsou vysoce kardinalitní a u metrik mohou výrazně zvýšit náklady i zátěž backendu – u metrik proto raději agregujte na úroveň rolí, scénáře nebo VIP flagu; v trasování si tyto identifikátory ponechejte, protože tam jsou pro analýzu a korelaci užitečné.

Jak nastavit OpenTelemetry metriky do Azure managed služeb
V předchozím odstavci jsme používali Aspire Dashboard a ten přímo podporuje metriky. Většina z vás ale asi bude spíše znát Prometheus. Pod ním se skrývají tři věci - SDK pro aplikace a mechanismus vystavování metrik (v podstatě přes webovou stránku, kam dá aplikace své metriky k odečtu), databáze pro uložení metrik a dotazovací jazyk PromQL. V našem případě odstraníme Prometheus SDK - nebudeme používat, chceme jít cestou OpenTelemetry a push. Z druhé strany si určitě chceme ponechat PromQL, protože ten je velmi používaný a příjemný. OpenTelemetry kolektor dokáže vzít OTEL metriky a poslat je dál ve formátu Prometheus použitím tzv. remote-write. V mém případě to ale nebude skutečný Prometheus, ale s ním kompatibilní jiná technologie. Tak jak Grafana Mimir dokáže nahradit Prometheus a přitom být plně kompatibilní, tak Azure Monitor for Prometheus dělá něco podobného.
Bohužel Azure Monitor for Prometheus vyžaduje přísné enterprise zabezpečení a to se špatně nastavuje přímo v kontejneru kolektoru, ale dá se to vyřešit sidecar - v té běží Prometheus bez zabezpečení, kolektor to do něj posílá přes remote-write a sidecar pak má autentizaci přes Managed Identity a remote-write do Azure Monitoru. Popsáno je to v dokumentaci
Kolektor pak vypadá nějak takhle:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
processors:
batch:
timeout: 5s
send_batch_size: 1024
memory_limiter:
check_interval: 1s
limit_mib: 512
exporters:
# Prometheus Remote Write exporter for Azure Monitor Prometheus
# Uses sidecar container for Azure AD token management
# The sidecar listens on localhost:8081 and injects the Authorization header
prometheusremotewrite:
endpoint: "http://localhost:8081/api/v1/write"
tls:
insecure: true
resource_to_telemetry_conversion:
enabled: true
service:
pipelines:
metrics:
receivers: [otlp]
processors: [memory_limiter, batch]
exporters: [prometheusremotewrite]
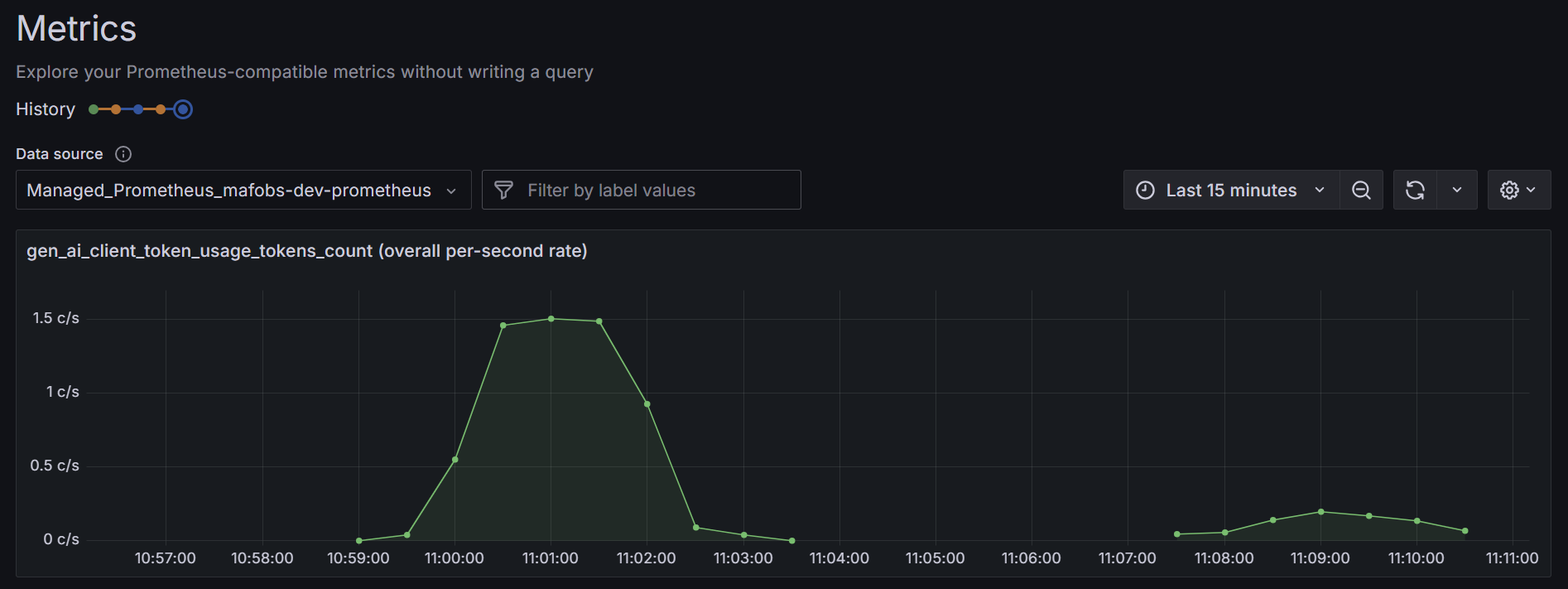
Následně mám nad tím Azure Managed Grafana a už se lze pustit do tvorby dashboardů.
Logování přes OpenTelemetry
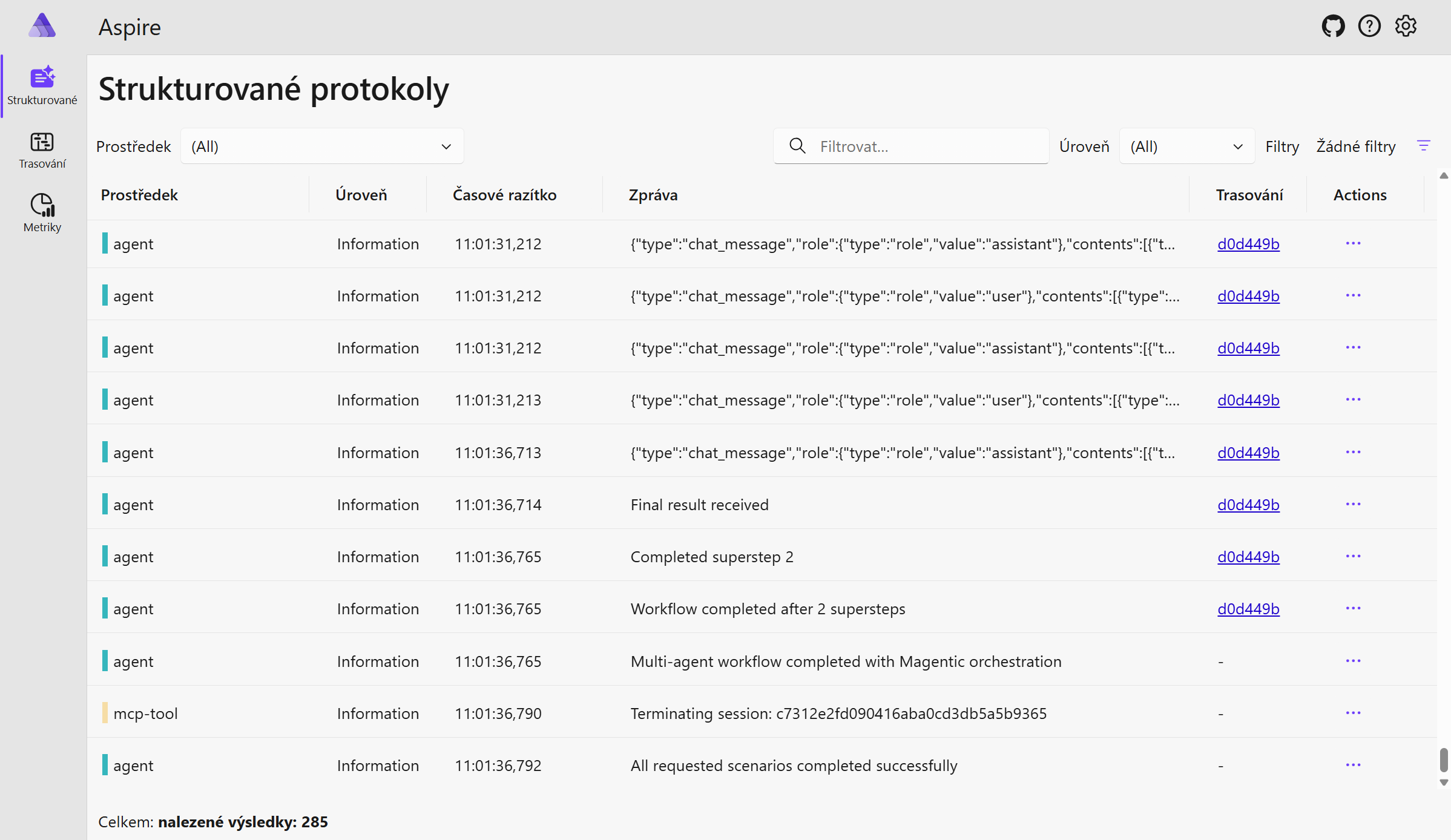
Klasický způsob logování je buď sběr obrazovky (stdout) nebo nástroje jako je Logstash, Fluentd nebo nativní nástroje konkrétního řešení jako je Graylog nebo Loki. OpenTelemetry ale přináší sjednocení a standardizaci, takže jednotné otevřené SDK můžete použít na trasování, metriky i logy. Bohužel v době psaní tohoto článku Azure Monitor ještě logy přes OpenTelemetry nepodporuje (ale prý se na tom pracuje), protože pod kapotou je Kusto ingestion pipeline a její enterprise nadstavby (např. RBAC podle zdroje) a není to triviální předělat. Nicméně pro účely mého zkoumání observability AI agentů jsem OpenTelemetry použil v kombinaci s Aspire Dashboard pro rychlý náhled.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# Configure OTLP logging
from opentelemetry.sdk._logs import LoggerProvider, LoggingHandler
from opentelemetry.sdk._logs.export import BatchLogRecordProcessor
from opentelemetry.exporter.otlp.proto.grpc._log_exporter import OTLPLogExporter
from opentelemetry.sdk.resources import Resource, SERVICE_NAME
from opentelemetry._logs import set_logger_provider
# Create log provider with resource
log_resource = Resource(attributes={
SERVICE_NAME: os.getenv("OTEL_SERVICE_NAME", "agent")
})
logger_provider = LoggerProvider(resource=log_resource)
set_logger_provider(logger_provider)
# Add OTLP log exporter
otlp_log_exporter = OTLPLogExporter(endpoint=otlp_endpoint, insecure=True)
logger_provider.add_log_record_processor(BatchLogRecordProcessor(otlp_log_exporter))
# Attach OTLP handler to root logger for telemetry collection
otlp_handler = LoggingHandler(level=logging.INFO, logger_provider=logger_provider)
# Configure root logger: NO console handlers, only OTLP
root_logger = logging.getLogger()
root_logger.handlers.clear() # Remove all console handlers
root_logger.addHandler(otlp_handler) # Only OTLP handler
root_logger.setLevel(logging.INFO)
# Also configure our app logger
logger.addHandler(otlp_handler)
Takhle to vypadá v dashboardu.
Dnes jsme se zaměřili na metriky a logy a příště se můžeme vrhnout do našeho hlavního tématu, do toho, co je pro observabilitu AI agentů nejdůležitější - trasování. Začneme s open source nástroji Aspire Dashboard a LangFuse, pak přidáme Azure AI Foundry a App Insights.