Asynchronní pattern pro vaše AI aplikace
Máte ve vaší webové aplikaci nějaké zpracování uživatelského vstupu v AI, například rozpoznání obrázku (ověření kvality, vhodnosti, generování tagů, popisků, kategorií), dokumentu (vytěžení údajů, tabulek, shrnutí, kategorizace) nebo vyhodnocení vstupního textu? Pokud používáte jazykové modely, tak celá odpověď může trvat minimálně vteřiny, ale spíše desítky vteřin. Na rozdíl od chatu, kde uživatele můžete “zabavit” streamováním odpovědi do okna, extrakce dat prostě musí doběhnout do konce.
Jednoduchá odpověď je často backend API, které prostě vrátí odpověď - třeba za 10 vteřin, ale takové synchronní řešení nebude robustní, škálovatelné, ani dobře monitorovatelné. Doporučoval bych určitě na tohle jít asynchronně a připravil jsem primitivní ukázku.
Veškerý kód mikroslužeb i Terraform pro nasazení do Azure najdete na mém GitHubu.
Asynchronní pattern z pohledu frontendu
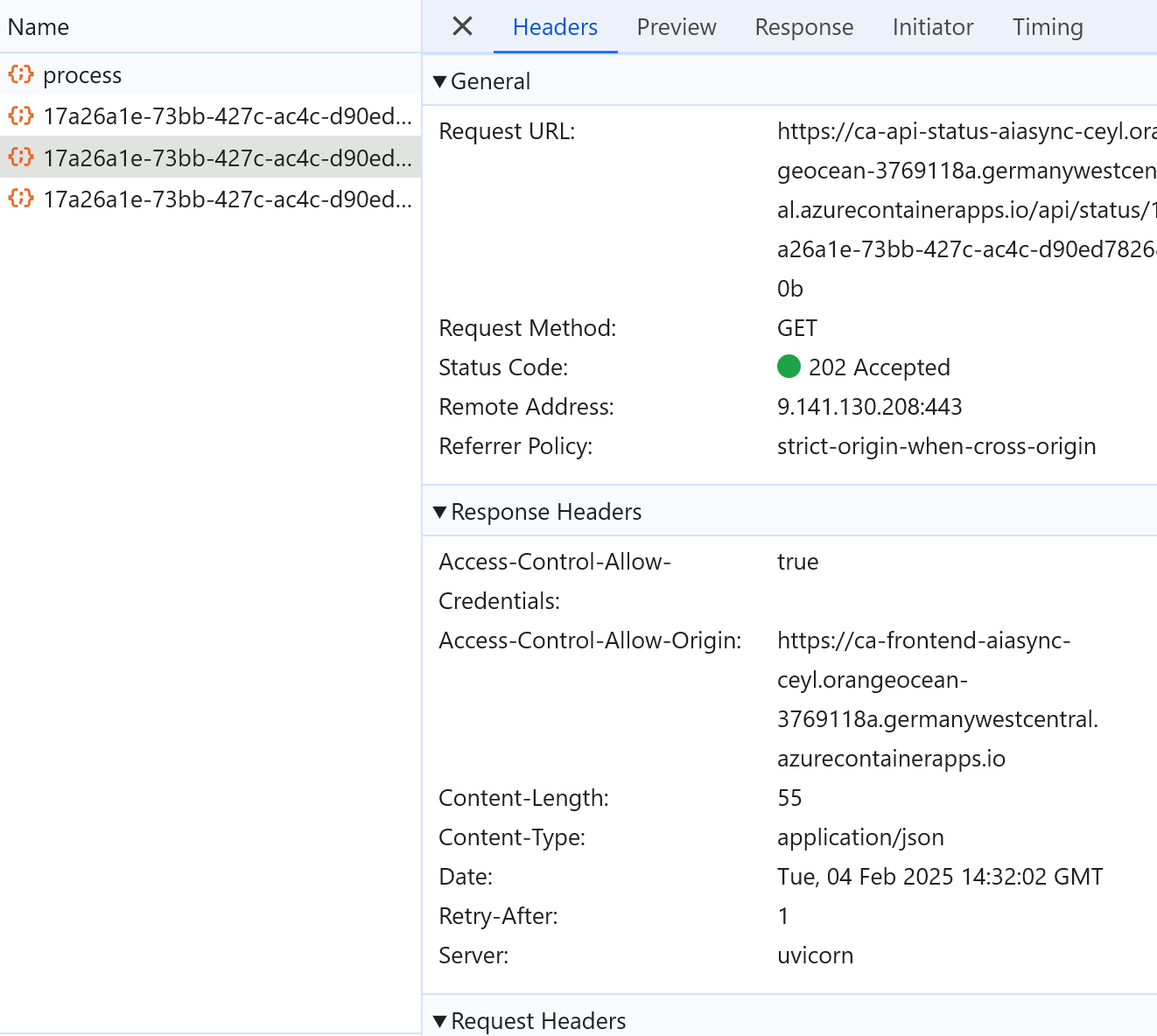
Frontend zavolá na backend a ten jeho požadavek přijme (například uloží dokument do blob storage a vystřelí zprávu do fronty či topicu), přiřadí požadavku nějaké ID a vrátí frontendu kód 202 Accepted s tímto ID a také URL, kde si může později vyzvednout výsledek. Frontend si tedy zavolá, jestli už to má hotové a příslušná služba mu buď řekne, že ještě ne (může to být 404, ale to zní moc chybově, takže bývá lepší opět 202) a doporučí mu za jak dlouho se zeptat znova (Retry-After hlavička) a nebo mu vrátí výsledek.
Uvedený scénář můžeme ještě ošperkovat tím, že frontendu aktivně řekneme, že to má hotové třeba přes SignalR nebo websocket, ale to pro náš případ není nutné (přecijen nepotřebujeme do frontendu streamovat hromady dat třeba pro nějaké grafy v reálném čase nebo zprávy chatu apod.).
Zpracování
V mém případě služba api-processing přijme soubor, vygeneruje GUID a pod ním ho jako JPEG uloží do Blob storage. Současně do fronty uloží zprávu, že byl soubor přijat (tady bychom mohli využít toho, že Blob Storage podporuje push notifikaci přes Event Grid, ale já preferoval zprávu, aby bylo možné na tom stavět i robustnost typu nedokončené zpracování zprávy a tak podobně). API jako takové běží v Azure Container Apps a používá HTTP škálování, takže v případě velké zátěže se nahodí další repliky a tím se i zvýší počet klientů do Service Bus i Blob storage, což zas zvyšuje škálovatelnost.
Processing kód je tady
Workery jsou udělané bez závislosti na něčem dalším, takže ve smyčce koukají, jestli nejsou nové zprávy k vyzvednutí. Tady by se to dalo určitě vylepšit použítím frameworku, který to bude dělat aktivně - typicky DAPR trigger nebo Azure Function trigger, ale pro jednoduchost jsem zůstal jen kódu samotného. Počet workerů díky Azure Container Apps škáluje podle délky fronty (používá se tam KEDA), takže počet instancí se zvětšuje dle potřeby. Nicméně i v samotné jediné instanci jsou věci v souběhu, protože je vše řešené asynchronním způsobem a zpracovává se celá dávka zpráv najednou.
Worker si zprávu pouze “vypůjčí” a na konci zpracování ji potvrdí. Pokud se tak cokoli v průběhu stane, například process padne nebo LLM vrátí chybu, worker buď aktivně vrátí zprávu zpět nebo se tak stane po určité době samovolně. To zvyšuje robustnost celého řešení, protože zpráva se neztratí a dojde k novým pokusům o její zpracování (až po několika neúspěších bude odložena do dead letter fronty).
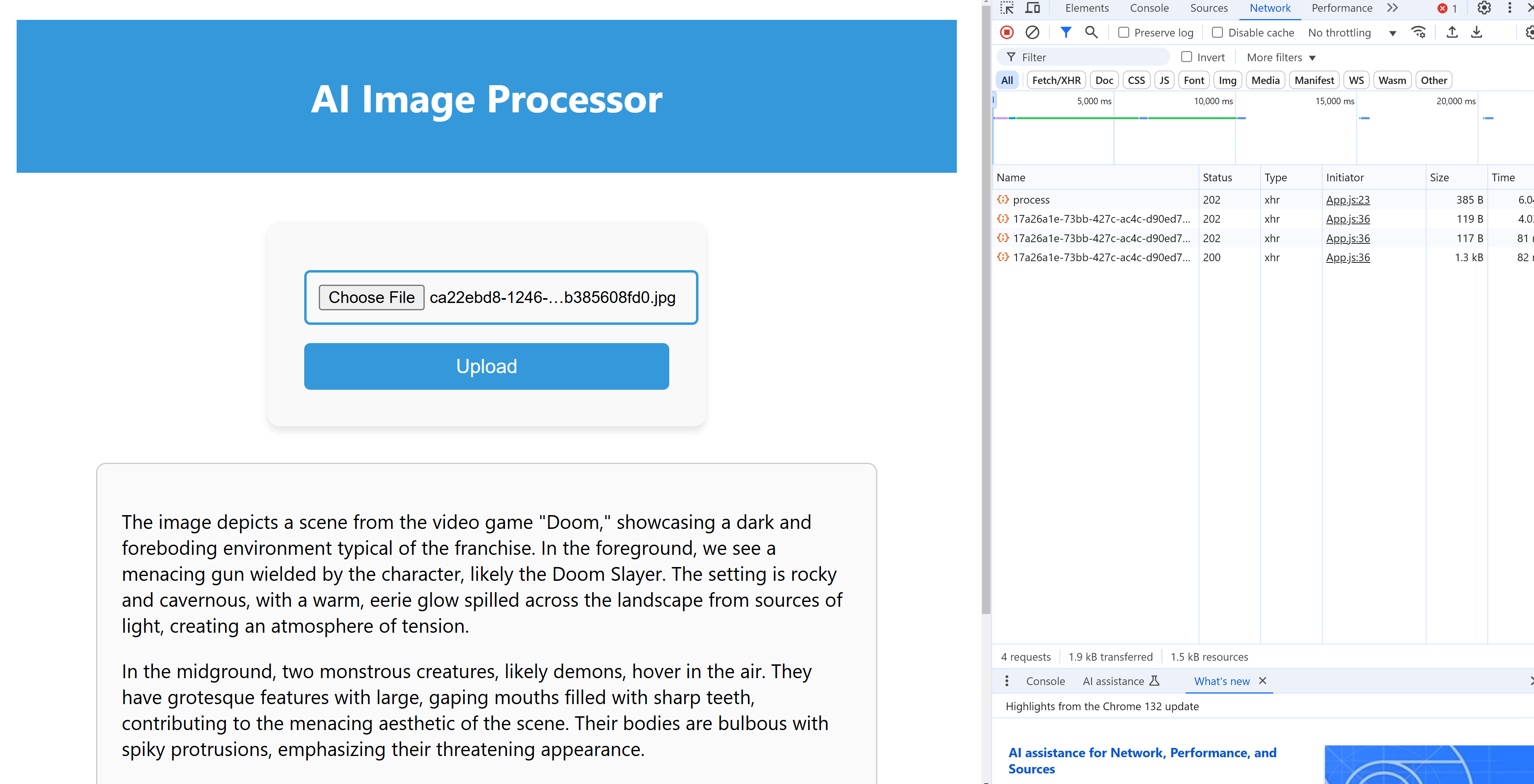
Co worker dělá? Vyzvedne zprávu, stáhne si soubor z blob storage a s příslušným promptem pošle do Azure OpenAI service. Výsledek vezme a uloží do CosmosDB se záznamem, jehož ID je GUID našeho zpracování. Tím máme hotovo, ale všimněte si, že nic z toho frontend vůbec nezajímá. Worker se škáluje a nasazuje zcela samostatně bez ohledu na API pro zpracovávání, status API i frontend.
Všimněme si také toho, že počet workerů krásně škáluje automaticky přes Azure Container Apps. Můžeme do toho ale přidat další faktor - jiné AI modely nebo endpointy. Tak například worker si může při startu vybrat jeden z několika endpointů a modelů a tím defacto provádíme balancování. Nebo může worker mít schopnost přepnout na model záložní, pokud hlavní nestíhá nebo nefunguje. Podstatné je, že přestože takové situace mohou vést k prodloužení doby zpracování, nevedou na nějaké chyby frontendu nebo jiného API, nevedou k přesycení paměti nějakého backendu, který by si musel držet stovky session a tak podobně. Každá komponenta jede pěkně sama za sebe a ve svém tempu - to je výhoda asynchronního přístupu.
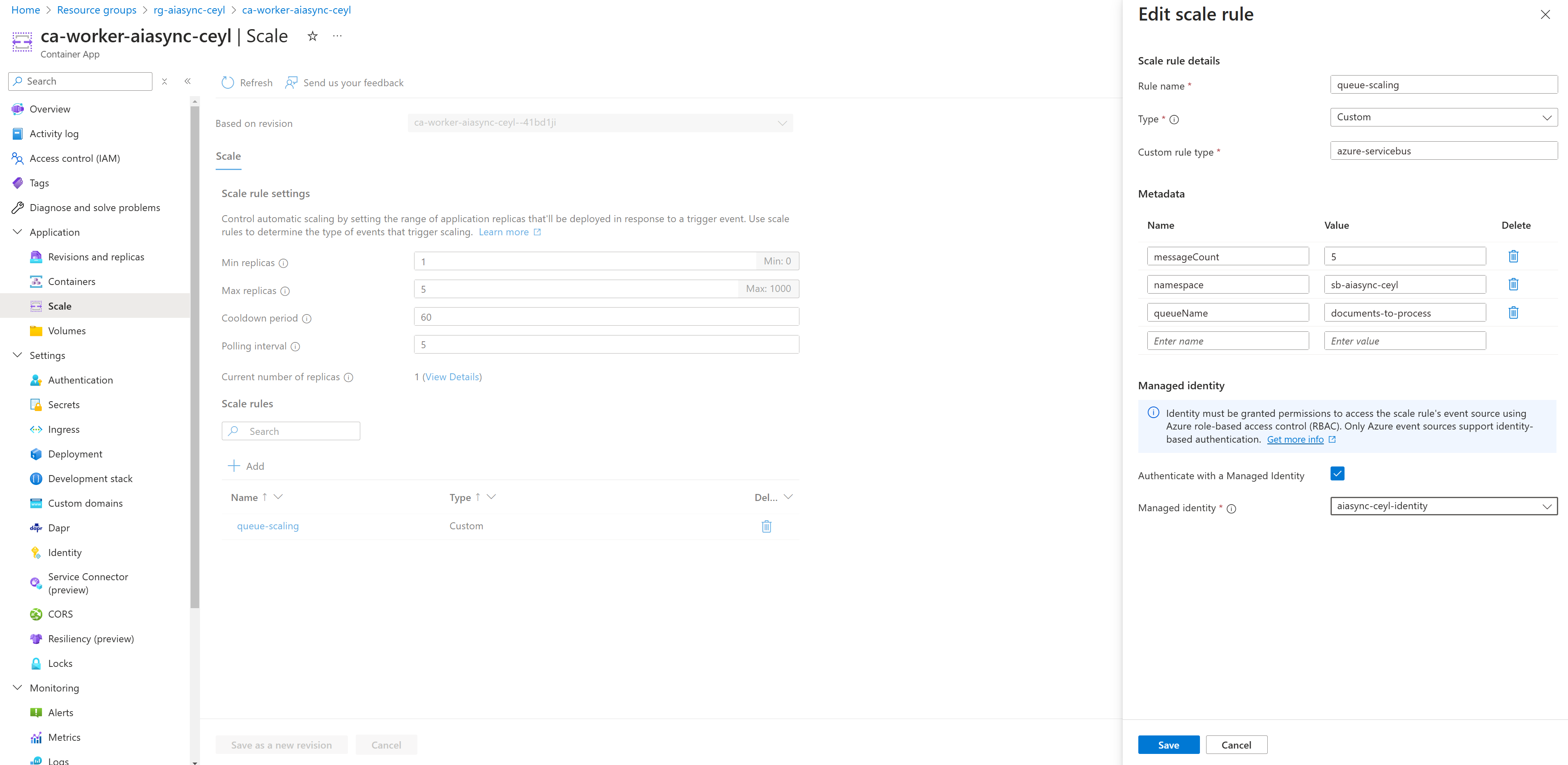
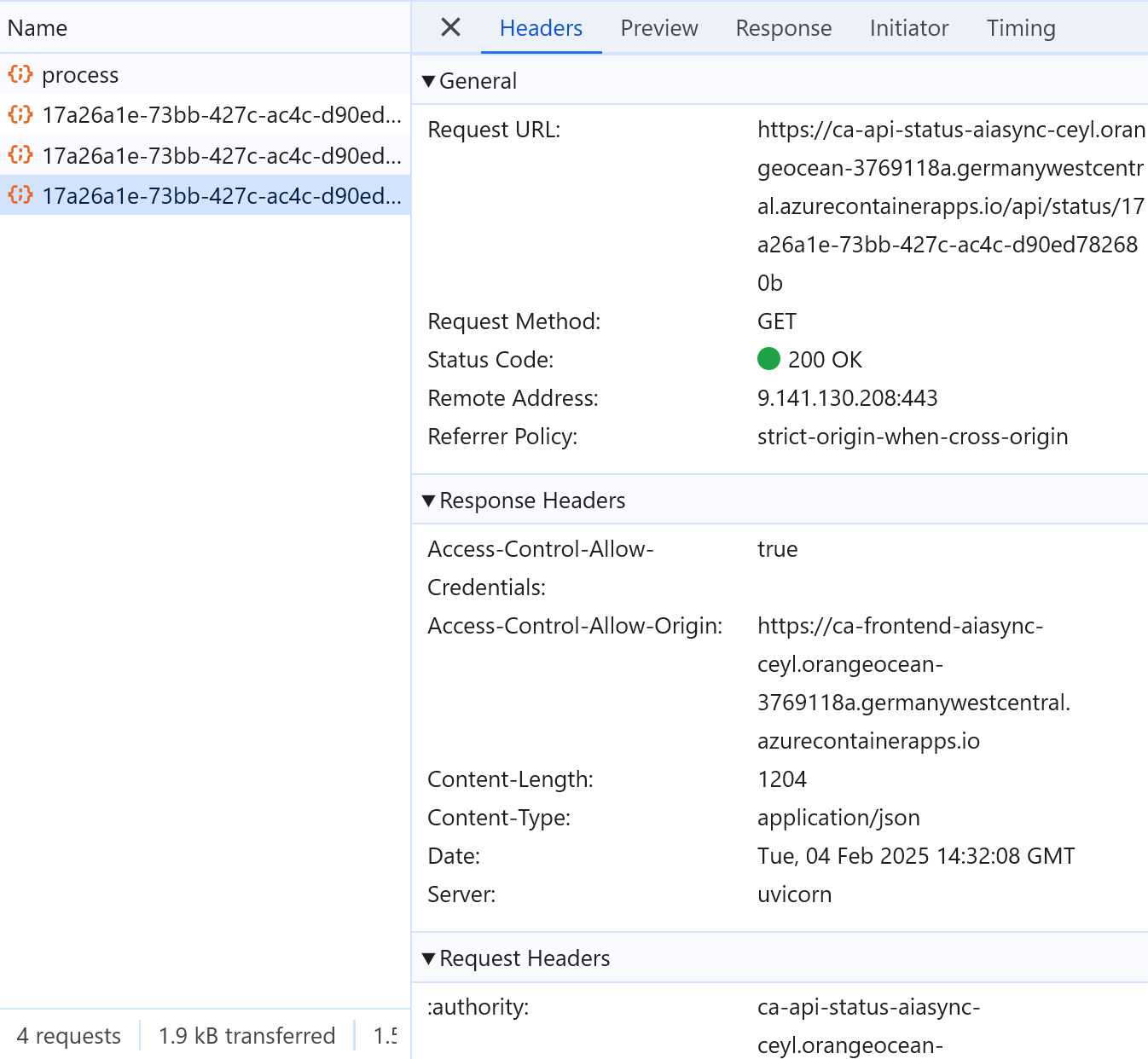
Na závěr zmíním službu status API, kterou frontend používá k vyzvednutí práce. API v url cestě dostane ID, a ověří, jestli už je v CosmosDB výsledek připraven. Pokud ne, vrátí 202, pokud ano, vrátí 200 s příslušným JSON objektem.
Kód vyzvedávacího API je tady
Monitoring a testování
Představte si, že toto řešení bude třeba zpracovávat obrázky, které uživatel uploaduje při žádosti o založení bankovního účtu, při registraci nebo třeba podávání přihlášky na střední školy. Může toho být najednou docela dost, takže bychom měli nejen škálovat, ale i umět testovat výkon a monitorovat.
Pro testování výkonu můžeme použít službu Azure Load Testing Service, nicméně náš scénář není jednoduché pingátko (simulovaný uživatel musí uploadnout soubor, parsovat výsledek a koukat se na status URL dokud nevrátí zpracovaný výsledek) a tak bych musel jít do JMeter a ten do služby nahrát. Z jeho přívětivosti nejsem nejnadšenější, takže jsem šel do oblíbeného a skvělého k6 od Grafana Labs. Testovací skript najdete tady. Dá se pustit z lokálu, ale mám ho i zabalený do kontejneru a dá se rozběhnout jako job v Azure Container Apps. Měl bych si určitě i ukládat HTML report a/nebo posílat metriky do Azure Monitor for Prometheus nebo přes OpenTelemetry, ale pro jednoduchost jsem to zatím neudělal.
Monitoring je postavený na OpenTelemetry s exportérem do Azure Monitor. Fajn je, že Python SDK pro Azure má v sobě potřebné autoinstrumentace, takže ať už jde o Blob Storage, Service Bus nebo Cosmos DB, není potřeba vlastně nic moc dělat a vše se sbírá a trasuje automaticky. To platí i v případě, že použijete Azure Inference SDK. Já použil klasické OpenAI SDK, ale i to už v experimentálním režimu autoinstrumentaci umí, takže vidím i tokeny za jednotlivé requesty a tak podobně. Nepodařilo se mi zatím rozchodit logování obsahu odpovědí a chat API se mi nekoreluje s requestem, ale to určitě půjde doladit (až to dořeším, pošlu to do GitHubu).
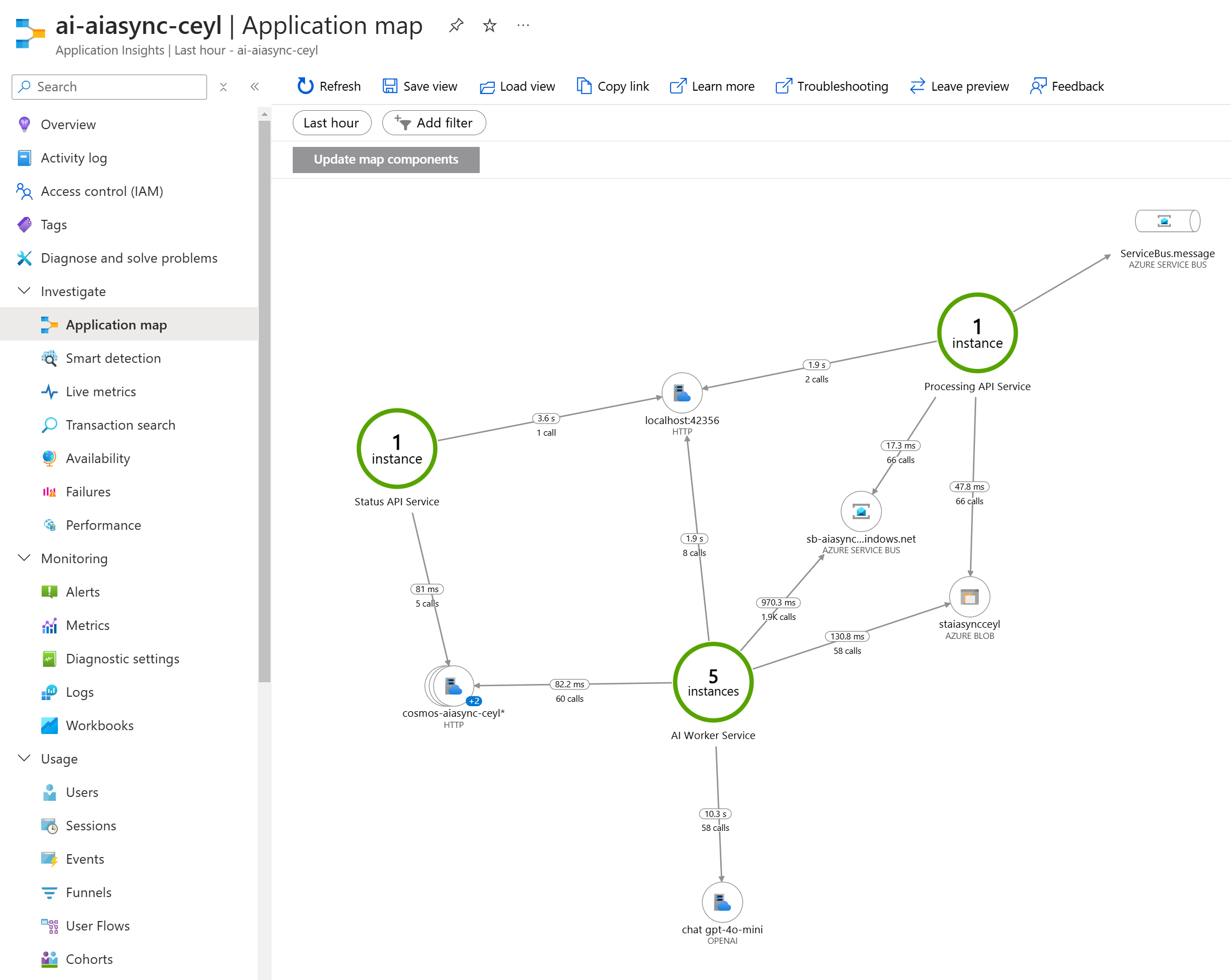
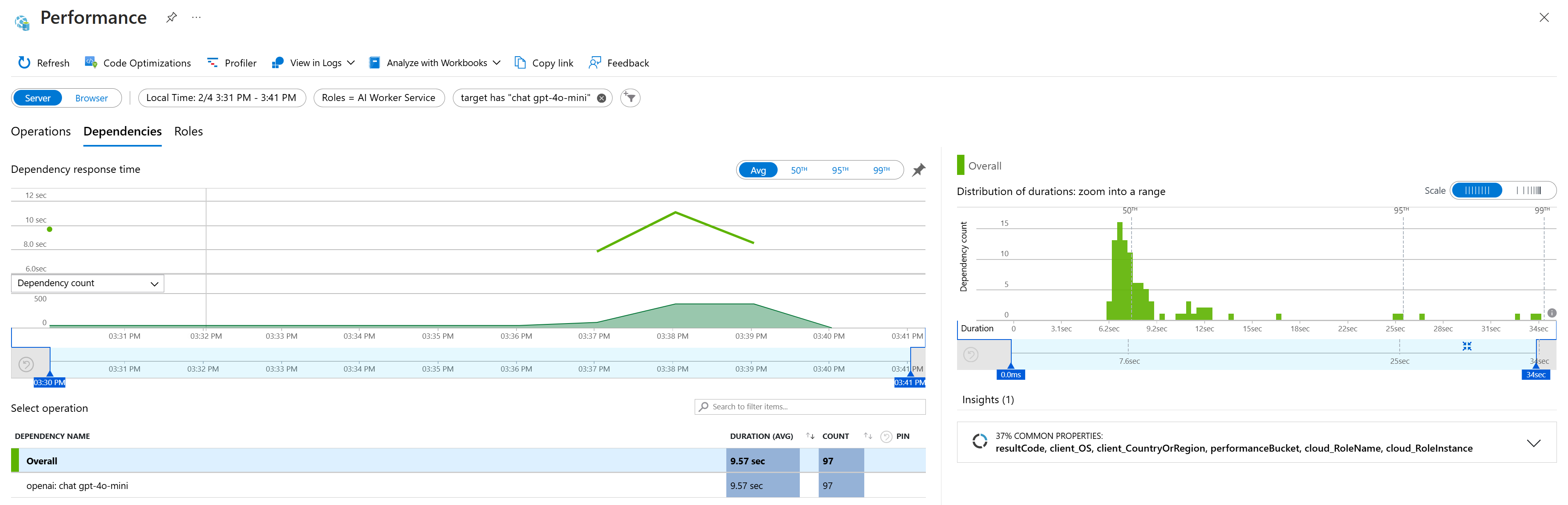
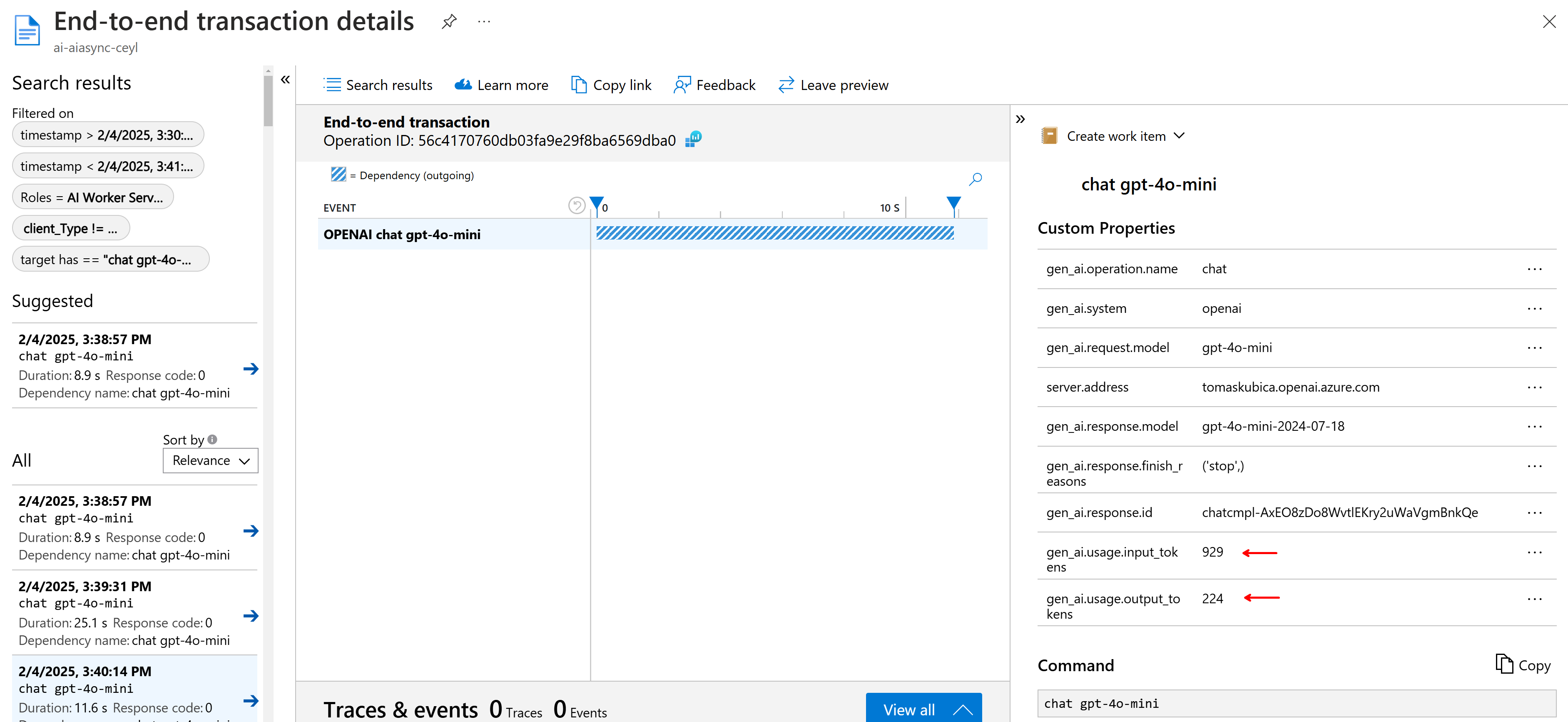
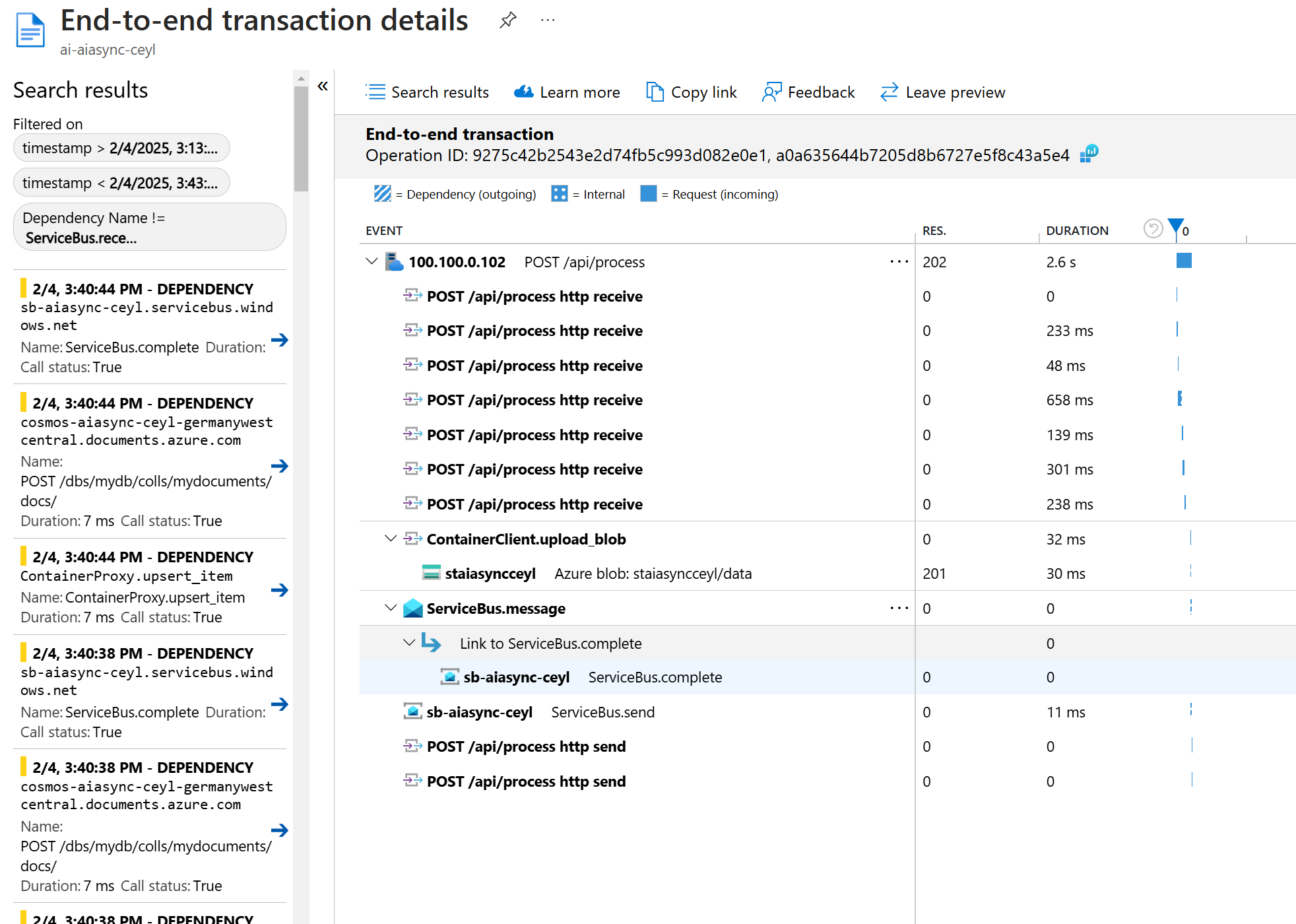
Závěr - proč asynchronně
Vyřešit to všechno na backendu jednou synchronní službou se může zdát snadné, ale při zátěži se myslím brzy pozná, že to není ideální řešení. Tady jsou výhody asychronního přístupu:
- Problém je rozdělen do samostatně vyvíjených, samostatně nasazovaných a samostatně škálovaných mikroslužeb - process API, status API, worker. To zlepšuje možnost postupného nasazování, škálování a vývoje.
- Každá komponenta se škáluje zvlášť, což je pro cloud ideální.
- Pokud řešení není moc vytěžované, můžeme škálovat do nuly (Azure Container Apps mikroslužbu probere teprve až to bude potřeba, do té doby neplatím).
- Chyby jsou izolované - problém ve workeru i včetně jeho pádu neovlivní ostatní části řešení (frontend, API) jinak, než tím, že zpracování bude trvat déle (žádné chyby nevznikají, workery to dřív nebo později vyřeší).
- Fronta slouží jako buffer a současně jako retry mechanismus, balancování AI služeb nebo izolaci problémů (dead letter fronta).
- Všechny části jsou dobře monitorovatelné podle ID zpracování, pod kterým se dají zkoumat logy, ale i nahrané soubory a záznamy v databázi.