OpenTelemetry pro observabilitu v LangGraph aplikaci do Aspire dashboardu a Application Insights
OpenTelemetry
OpenTelemetry je standard pro push-based monitoring pro všechny tři základní typy observability - logy, traces i metriky. Jak si vede?
- O jeho převaze právě v trasování není pochyb a stavět to na něčem jiném by byl nesmysl, zejména, když standard podporují prakticky všichni velcí hráči v backendech pro observabilitu samozřejmě včetně Azure Monitoru (Application Insights).
- Metriky mají stabilní standard od roku 2023 a jde o oblast, ve které vždy dominoval Prometheus. OpenTelemetry se s ním umí obousměrně integrovat, takže OpenTelemetry Collector může metriky v Prometheus formátu sbírat a naopak OpenTelemetry data lze posílat do Promethea (dříve přes exportér, dnes umí Prometheus OLTP nativně). Může tak mít nejen end-to-end metriky přes OpenTelemetry, ale sbírat z aplikací používajících Prometheus nebo už přecházet na OpenTelemetry SDK a přitom dostat data do tradičního Promethea. Poslední průzkum co jsem viděl tvrdí, že Prometheus používá 70% respondentů, 20% OpenTelemetry na metriky, ale 38% uvažuje o sjednocení metrik nad OpenTelemetry.
- Logy jsou v OpenTelemetry stále poměrně čerstvé, nicméně už plně funkční. Na rozdíl od trasování, kde je rozhodnuto a od metrik, kde asi dojde k splynutí či prolnutí s Prometheem, SDK pro logy ještě není plně stabilní pro všechny jazyky. Nicméně třeba Elastic nebo Loki už podporují přímo ingesting OpenTelemetry, takže cesta k jednotné instrumentaci aplikací vypadá dobře.
LangGraph
Monitoring AI aplikací je velmi aktuální téma, ke kterému se ještě jednou vrátím v souvislosti s AI hub. LangGraph je velmi populární open source framework z dílny tvůrců LangChainu, kterýžto je na mě až příliš abstrahovaný a nejsem zas tak velkým fanouškem. Ale LangGraph je jiný - nízkoúrovnější, elegantnější, méně skryté magie a s podporou pro flexibilní scénáře a multi-agent architektury. Jak tento framework monitorovat?
Je to jednoduché, protože k LangGraph existuje auto-instrumentace - jednoduše přidáte SDK a máte nádherné komplexní trasování včetně obsahu LLM dotazů a odpovědí (pokud chcete) a metriky jako je spotřebované množství tokenů.
Základní nahození OpenTelemetry SDK jsem udělal tak, abych si mohl přidávat i vlastní metriky (jednu jsem rovnou definoval) a používat vlastní logy.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
import logging
import os
from opentelemetry import metrics, trace
from opentelemetry._logs import set_logger_provider
from opentelemetry.exporter.otlp.proto.grpc._log_exporter import (
OTLPLogExporter,
)
from opentelemetry.exporter.otlp.proto.grpc.metric_exporter import OTLPMetricExporter
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk._logs import LoggerProvider, LoggingHandler
from opentelemetry.sdk._logs.export import BatchLogRecordProcessor
from opentelemetry.sdk.metrics import MeterProvider
from opentelemetry.sdk.metrics.export import PeriodicExportingMetricReader
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.sdk.resources import Resource, SERVICE_NAME
from dotenv import load_dotenv
def configure_otel(
endpoint: str = None
) -> trace.Tracer:
load_dotenv()
# Configure Tracing
service_name = os.getenv("OTEL_SERVICE_NAME", "multi-agent")
resource = Resource.create({SERVICE_NAME: service_name})
traceProvider = TracerProvider(resource=resource)
processor = BatchSpanProcessor(OTLPSpanExporter(endpoint=endpoint))
traceProvider.add_span_processor(processor)
trace.set_tracer_provider(traceProvider)
# Configure Metrics
reader = PeriodicExportingMetricReader(OTLPMetricExporter(endpoint=endpoint))
meterProvider = MeterProvider(resource=resource, metric_readers=[reader])
metrics.set_meter_provider(meterProvider)
meter = metrics.get_meter(__name__)
# Define metrics
global message_count_counter
message_count_counter = meter.create_counter(
name="agent_message_count",
description="Number of agent messages processed",
unit="1"
)
# Configure Logging
logger_provider = LoggerProvider(resource=resource)
set_logger_provider(logger_provider)
exporter = OTLPLogExporter(endpoint=endpoint)
logger_provider.add_log_record_processor(BatchLogRecordProcessor(exporter))
handler = LoggingHandler(level=logging.NOTSET, logger_provider=logger_provider)
handler.setFormatter(logging.Formatter("Python: %(message)s"))
# Attach OTLP handler to root logger
logging.getLogger().addHandler(handler)
tracer = trace.get_tracer(__name__)
return tracer
def get_message_count_counter():
global message_count_counter
return message_count_counter
Samotná instrumentace LangGraphu je jediný řádek:
1
2
from opentelemetry.instrumentation.langchain import LangchainInstrumentor
LangchainInstrumentor().instrument()
Co se týče logování, použiji klasicky logger a už mám nastaveno, že ten to posílá přes OpenTelemetry. Přidám ještě výstup na obrazovku.
1
2
3
4
5
6
7
8
9
10
11
12
13
import logging
logger = logging.getLogger("multiagent")
# Ensure logger prints to console as well as OpenTelemetry
if not any(isinstance(h, logging.StreamHandler) for h in logger.handlers):
console_handler = logging.StreamHandler()
console_handler.setFormatter(logging.Formatter("%(asctime)s %(levelname)s %(message)s"))
logger.addHandler(console_handler)
logger.setLevel(logging.INFO)
def print_agent_message(agent_name: str, message: str, timestamp: str):
logger.info(f"[{timestamp}] {agent_name.upper()}: {message}")
Aspire dashboard
Z dílny .NETu pochází jeden krásný projekt - open source Aspire dashboard, malý a hezký jedno-kontejnerový nástroj pro rychlý sběr a vizualizaci metrik, logů i trasování z OpenTelemetry. Lokální použití je nejjednodušší v kontejneru:
1
2
3
4
5
docker run --rm -it `
-p 18888:18888 `
-p 4317:18889 `
--name aspire-dashboard `
mcr.microsoft.com/dotnet/aspire-dashboard:latest
Pak stačí nastavit environmentální proměnnou OTEL_EXPORTER_OTLP_ENDPOINT na http://localhost:4317 a spustit aplikaci. V Aspire dashboardu pak vidíte krásné grafy a tabulky s metrikami, logy i trasováním. Link na dashboard s bezpečnostním kódem najdete ve výstupu kontejneru.
Podívejme se nejdřív na logy v Aspire dashboardu.
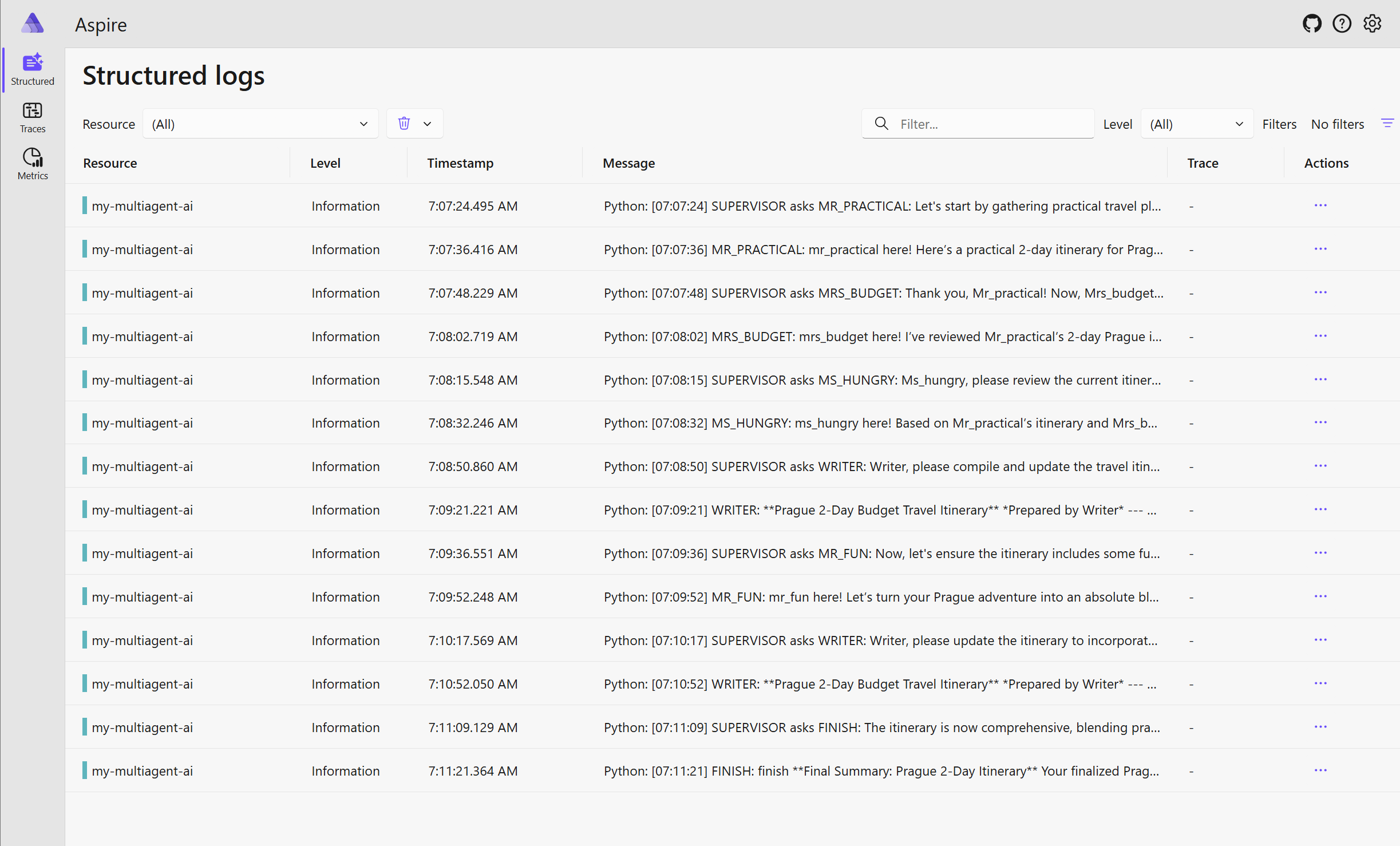
Metadata pro filtrování zahrnují například service name (název aplikace) nebo service instance id (například replika v rámci Azure Container Apps).
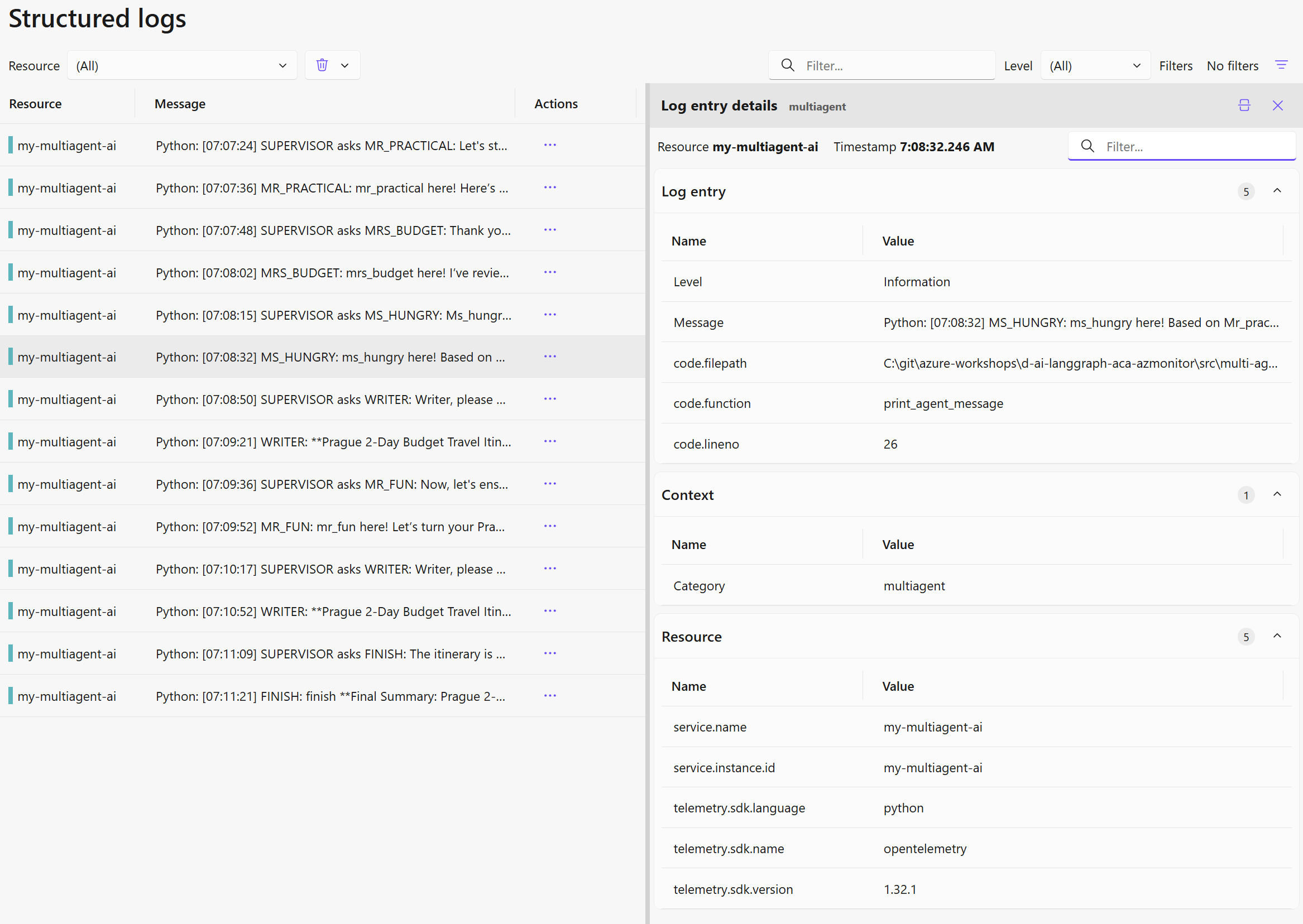
Pokud logujete do JSON nebo XML, vizualizace s tím počítá.
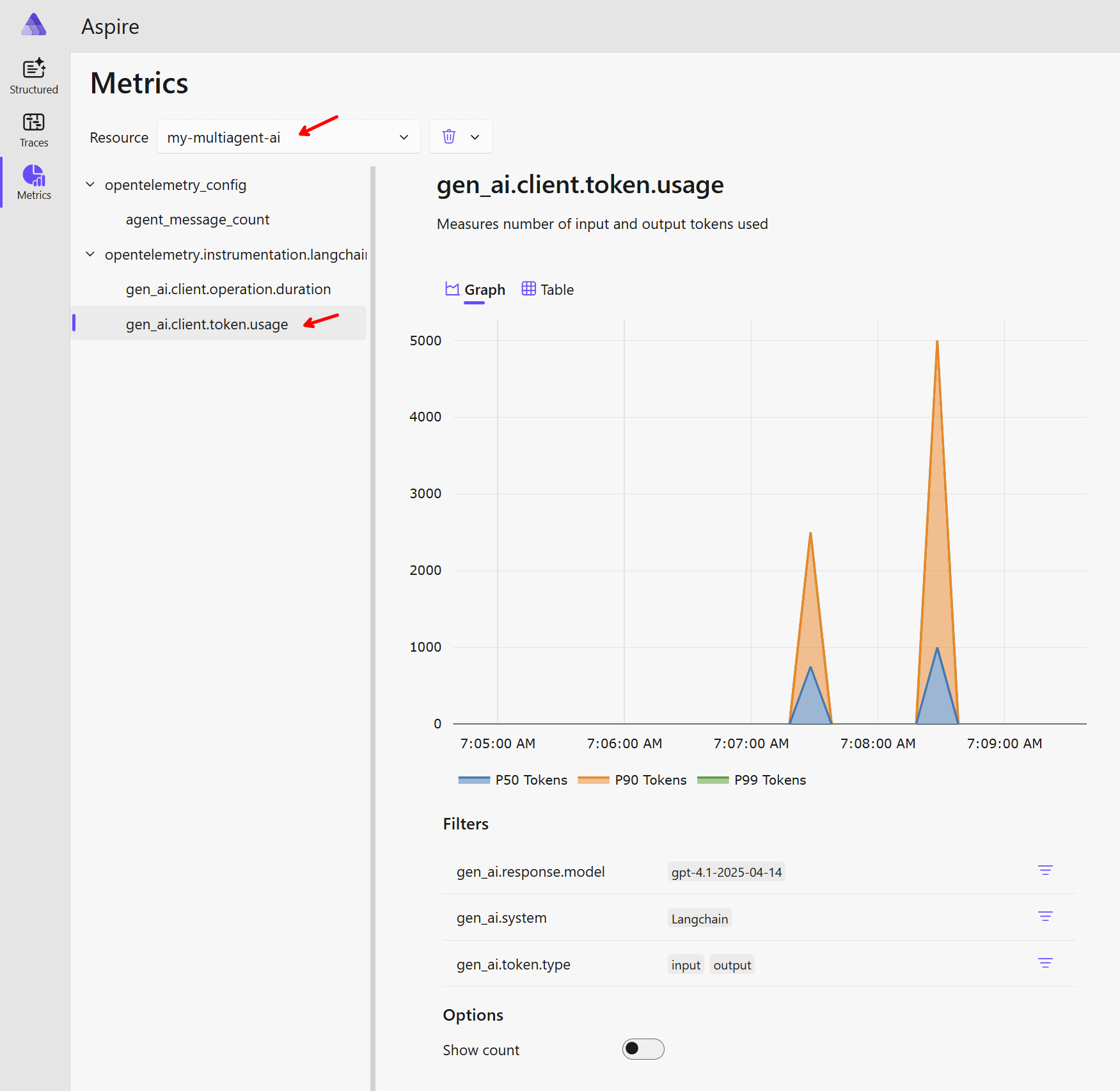
Metriky vypadají krásně. LangGraph autoinstrumentace pro nás rovnou generuje metriku o spotřebovaných tokenech s potřebnými dimenzemi, takže si ji můžeme dál filtrovat podle vstup/výstup, model a tak podobně.
Jak vypadá metrika, kterou jsem si přidal sám? Šlo mi o počítání zpráv jednotlivých agentů a jako dimenzi posílat název agenta. To nám umožní si krásně filtrovat a agregovat.
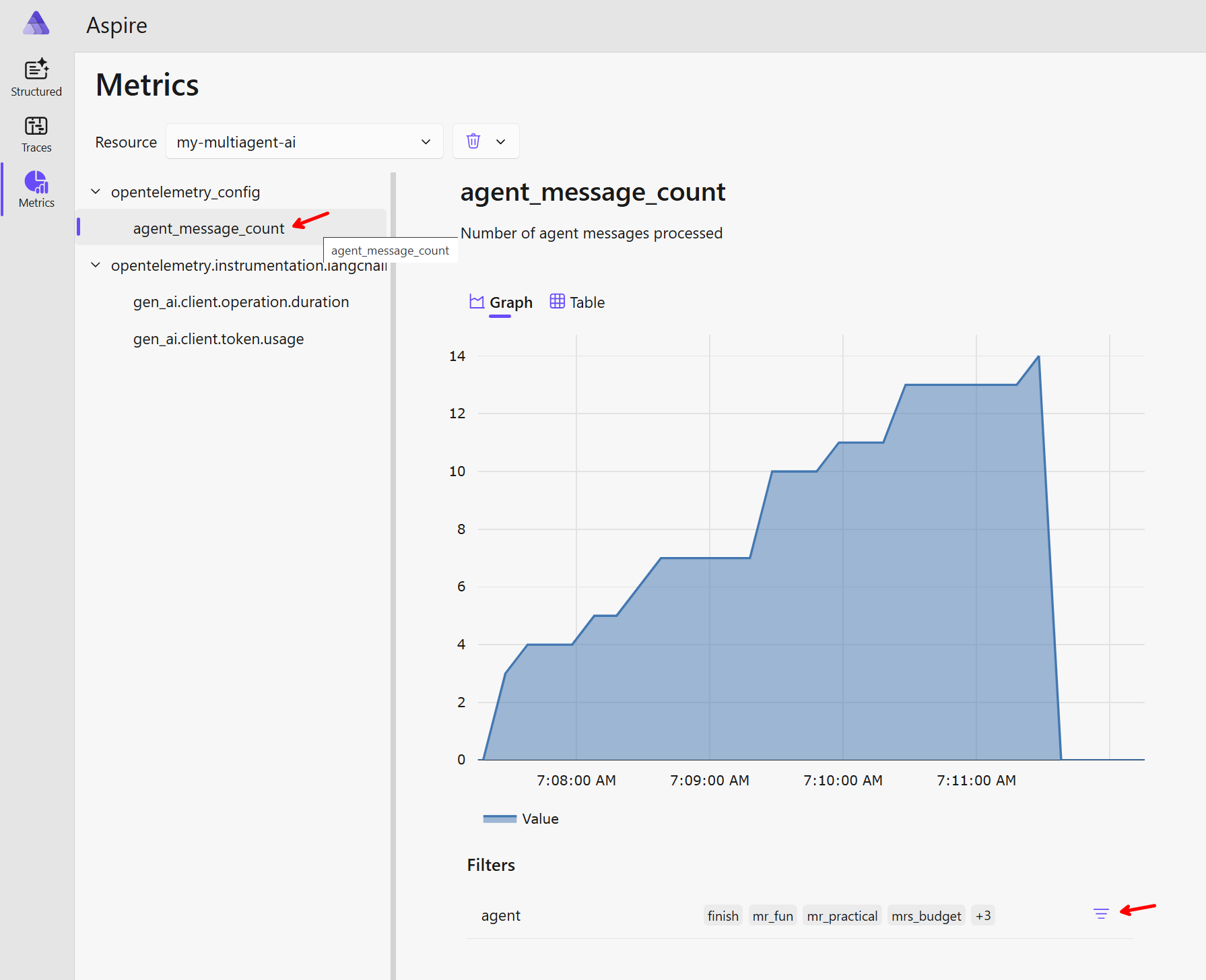
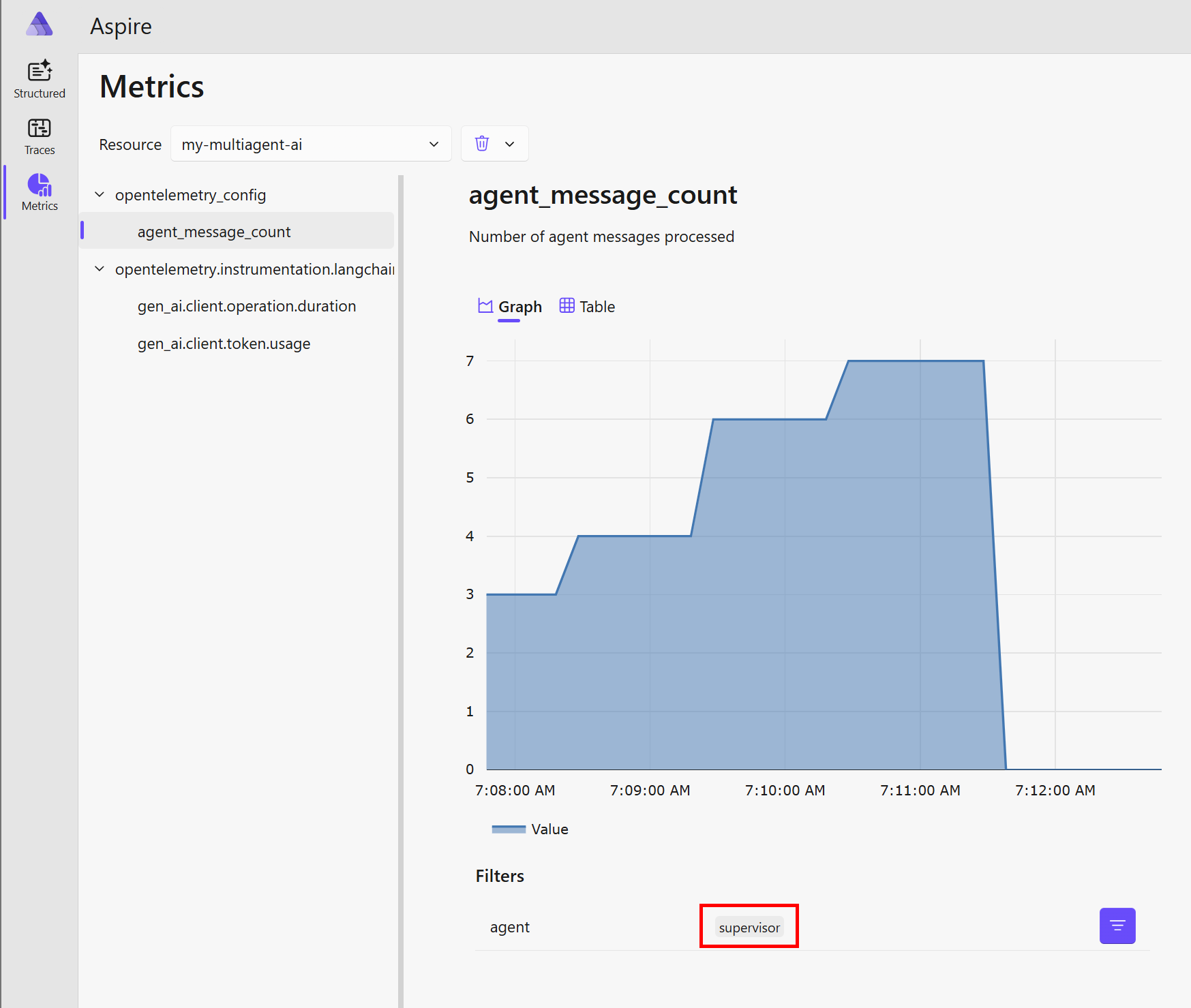
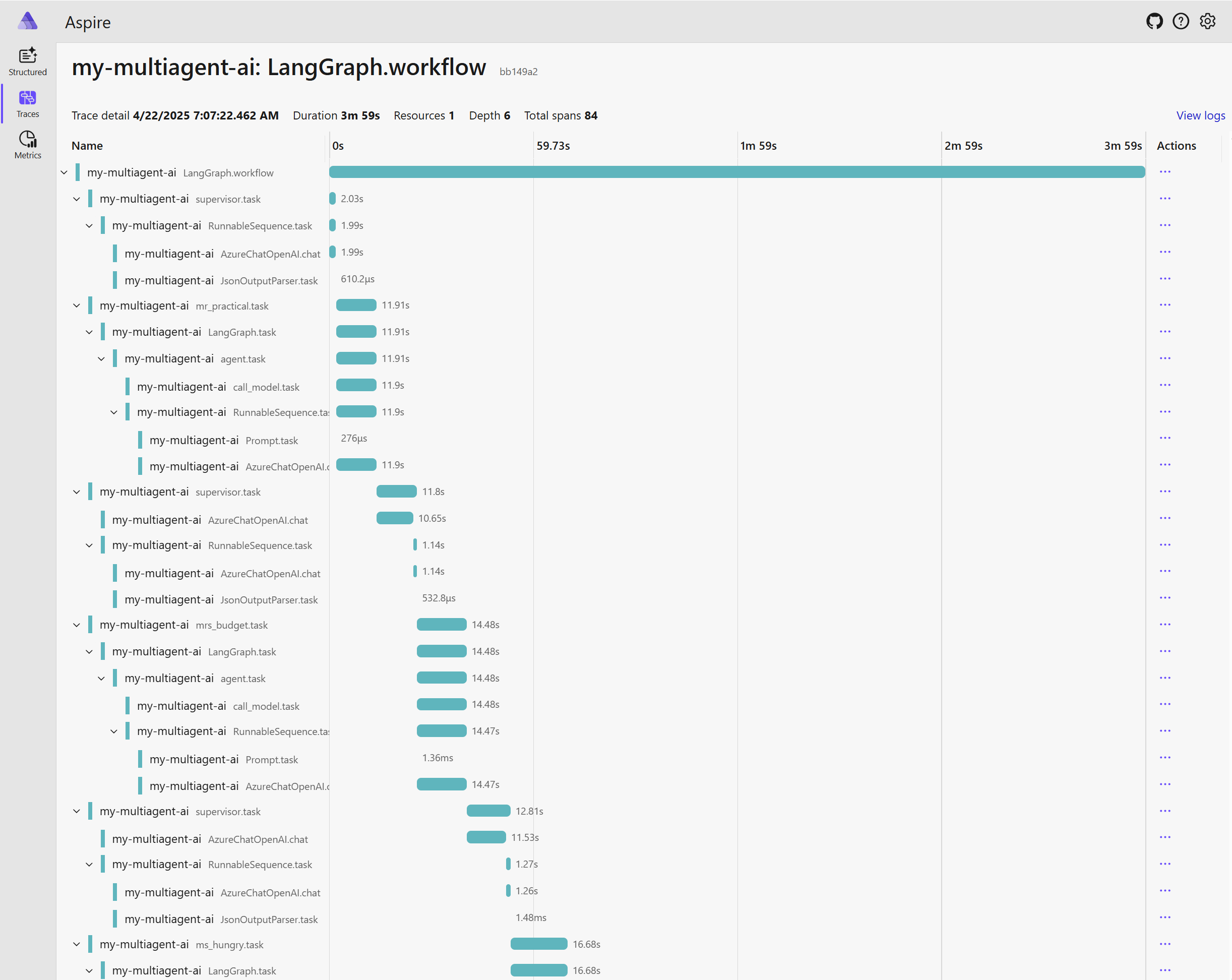
A co trasování? Celý můj multi-agent běh připravující odpověď na otázku trval 4 minuty a zahrnuje 84 podrobných spanů.

Dostáváme klasický graficky pěkně provedený rozpad jednotlivých kroků v čase.
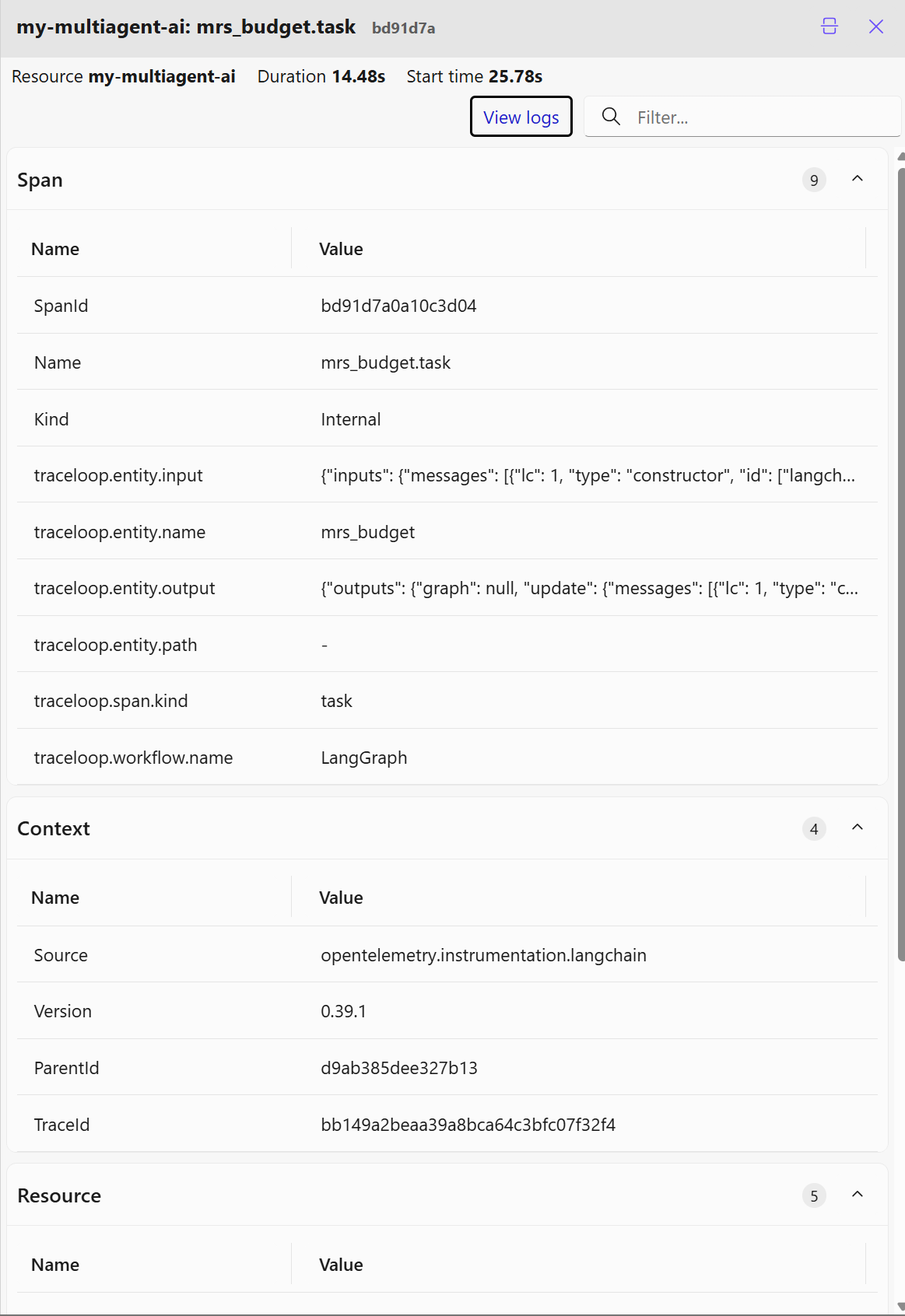
Doklikáme se samozřejmě k dalším detailům a to včetně obsahu posílaných dotazů a odpovědí.
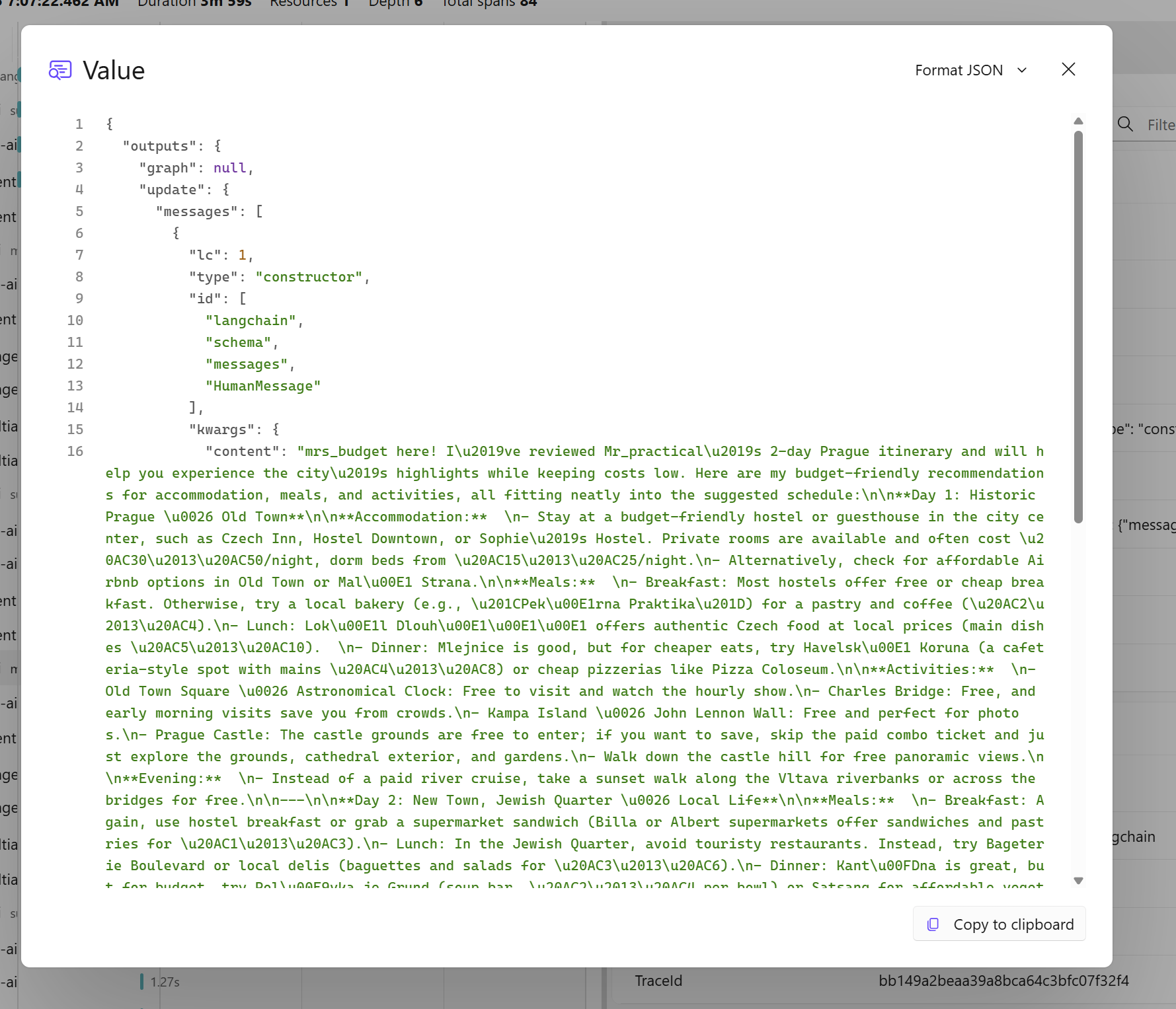
Azure Monitor s kolektorem v Azure Container Apps
Aplikace nejraději provozuji v Azure Container Apps. Je to platforma vyšší abstrakce, takže se nemusím babrat s překomplikovaným a nízkoúrovňovým Kubernetes, ale zase mi to neříká jak mám aplikace buildovat, navrhovat a nenutí mě nasazovat “ze zdrojáku”, když to ne vždy chci. Zabalím klasicky kontejner a nemusím přemýšlet o specialitách nějakého serverless frameworku. Pro mě ideální. Pro monitoring tato platforma nabízí v preview spravovaný OpenTelemetry Collector, takže o ten se nemusím starat, upgradovat ho a dokonce mi i zařídí vstříknutí potřebných environmentálních proměnných do kontejneru.
Kolektor aktuálně podporuje export do Application Insights (zatím ale bez metrik), do Datadog ale také přes OLTP do jiného OpenTelemetry endpointu (například New Relic nebo Honeycomb podporují OLTP přímo u sebe).
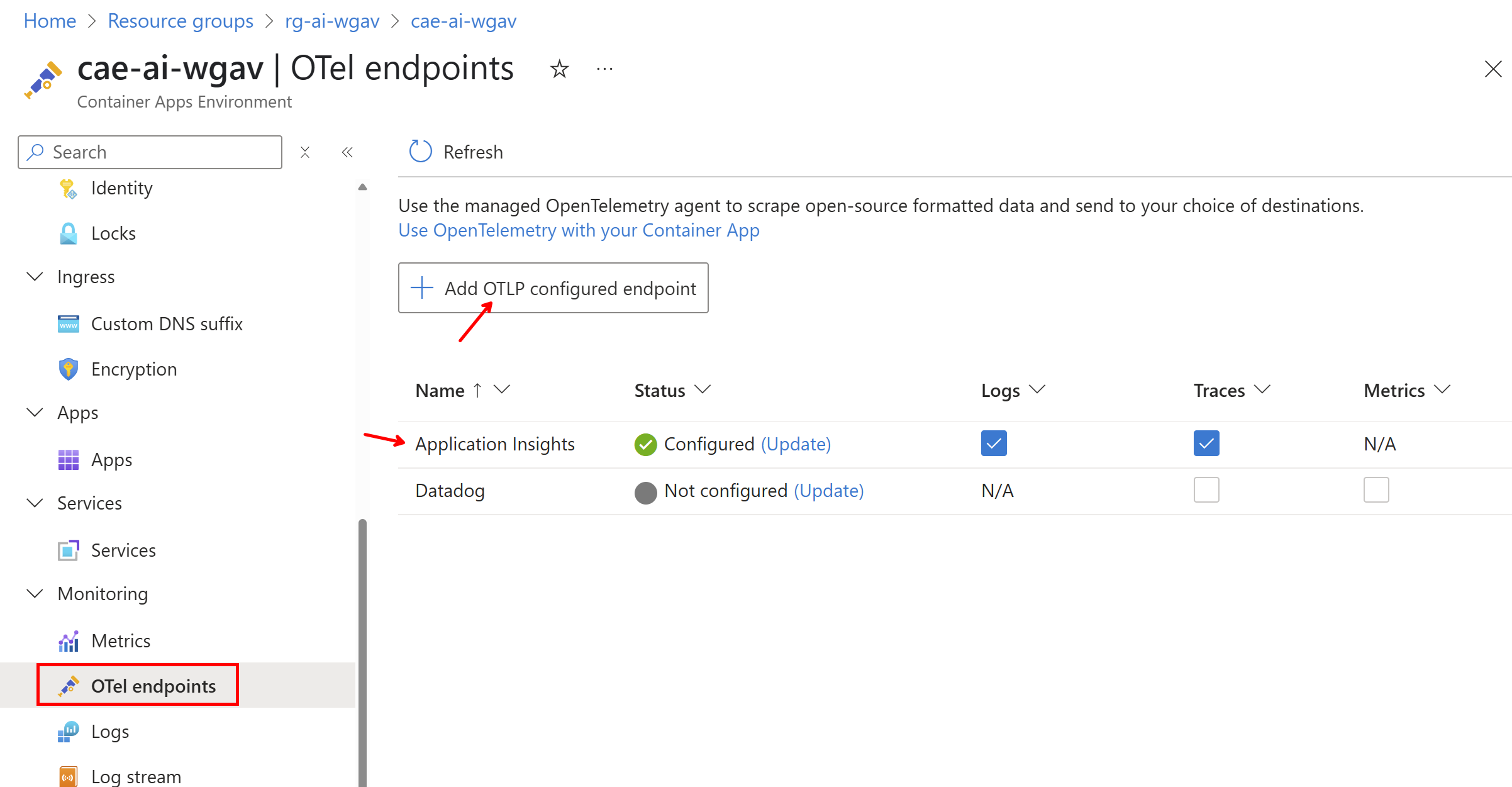
V Application Insights se můžeme podívat na mapu (u mě velmi jednoduchá - víc si ukážeme v budoucím článku o AI Hub) a přímo tam najdeme základní ukazatele jako je nejpomalejší call, selhání a co mají společného.
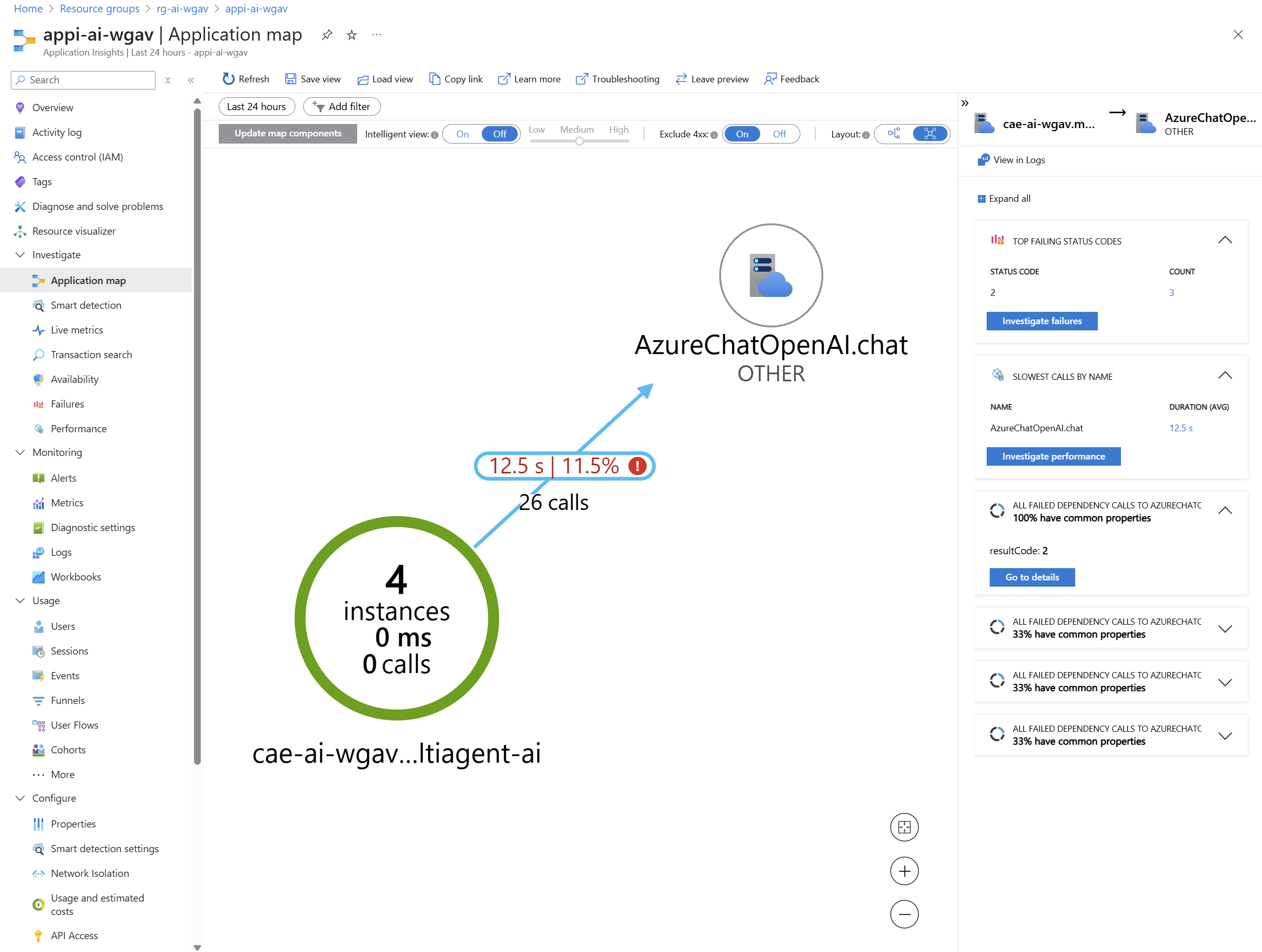
Můžeme se podívat ne Failures a Performance.
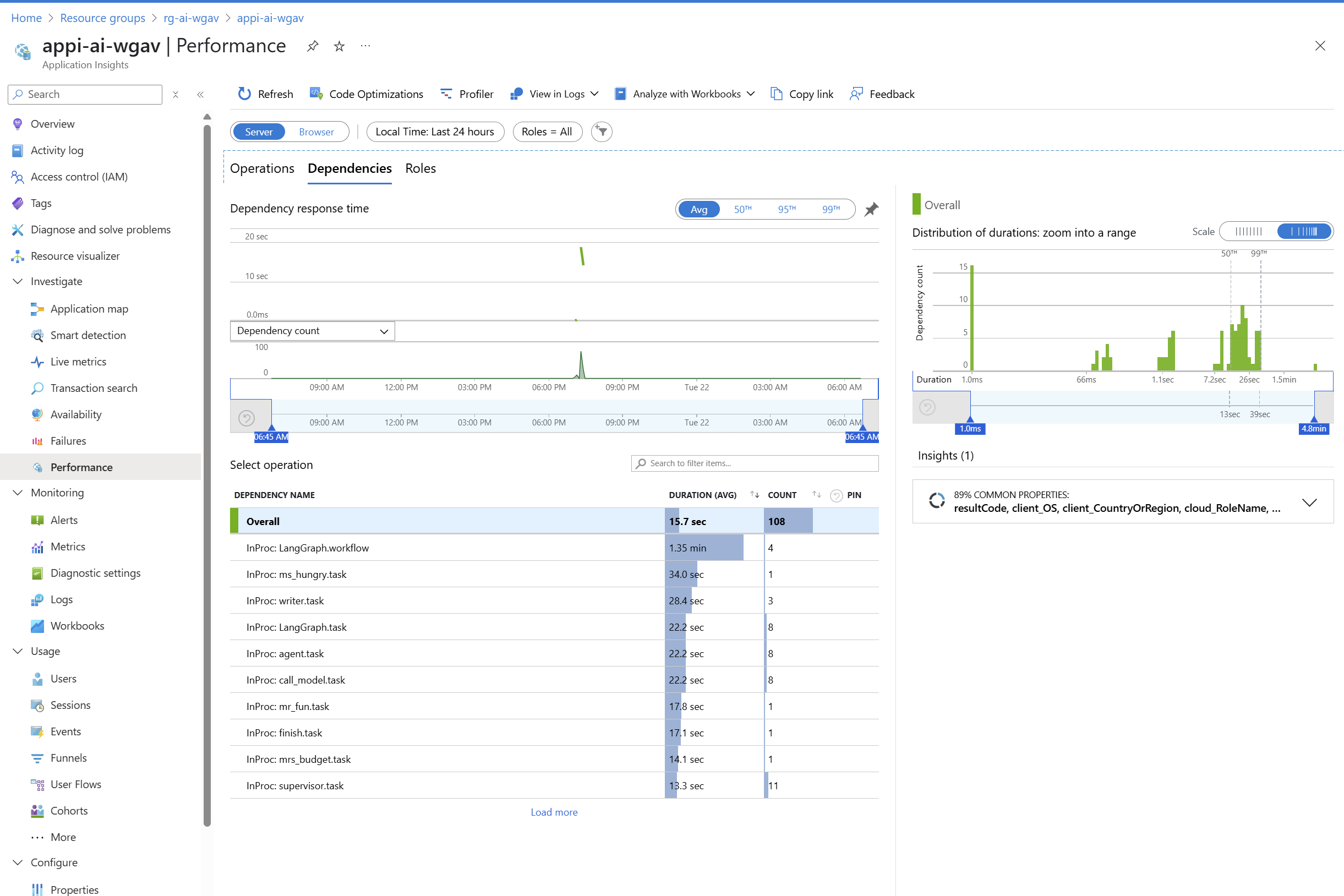
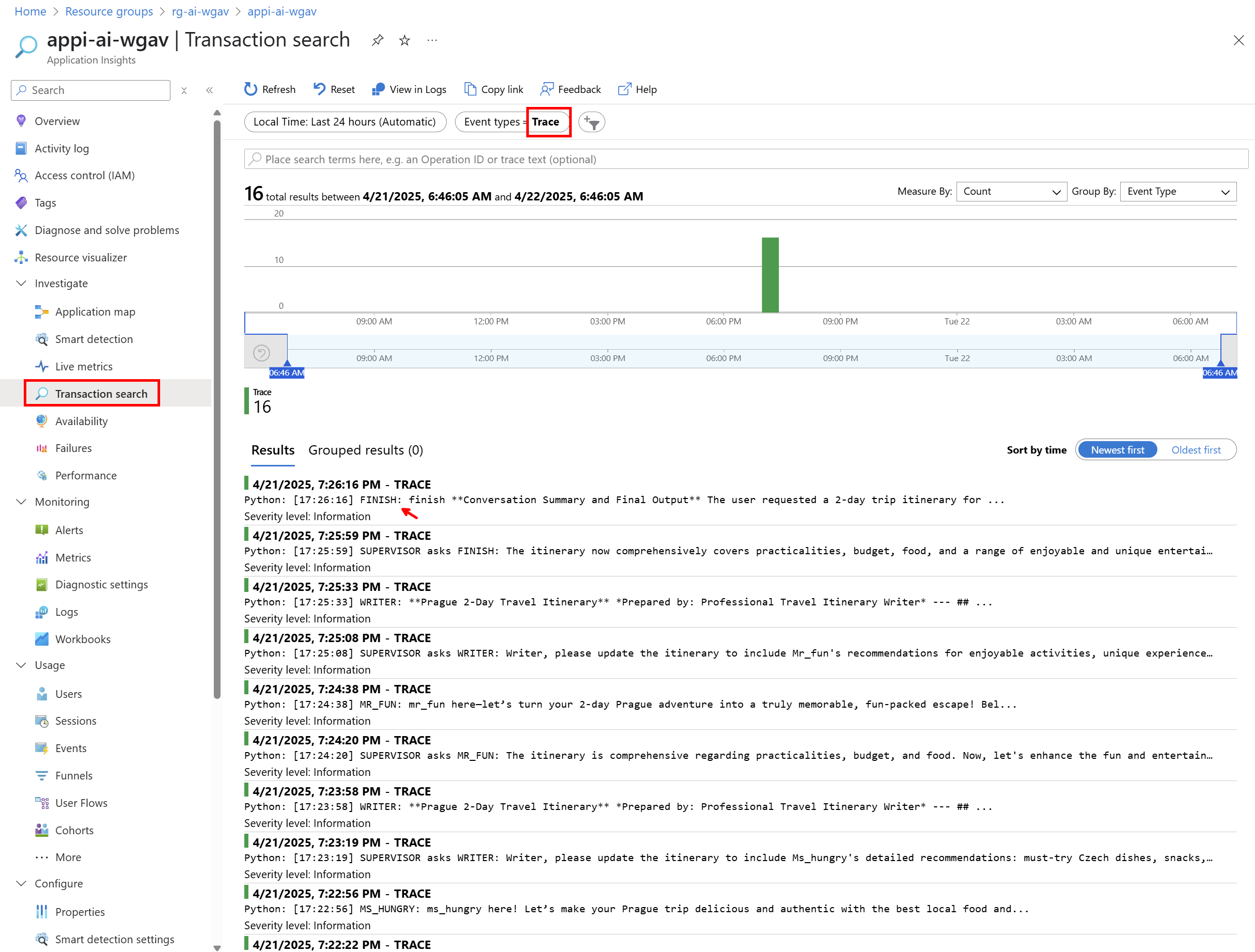
Podívejme se na aplikační logy, které jsou v terminologii Application Insights nazývány “traces”.
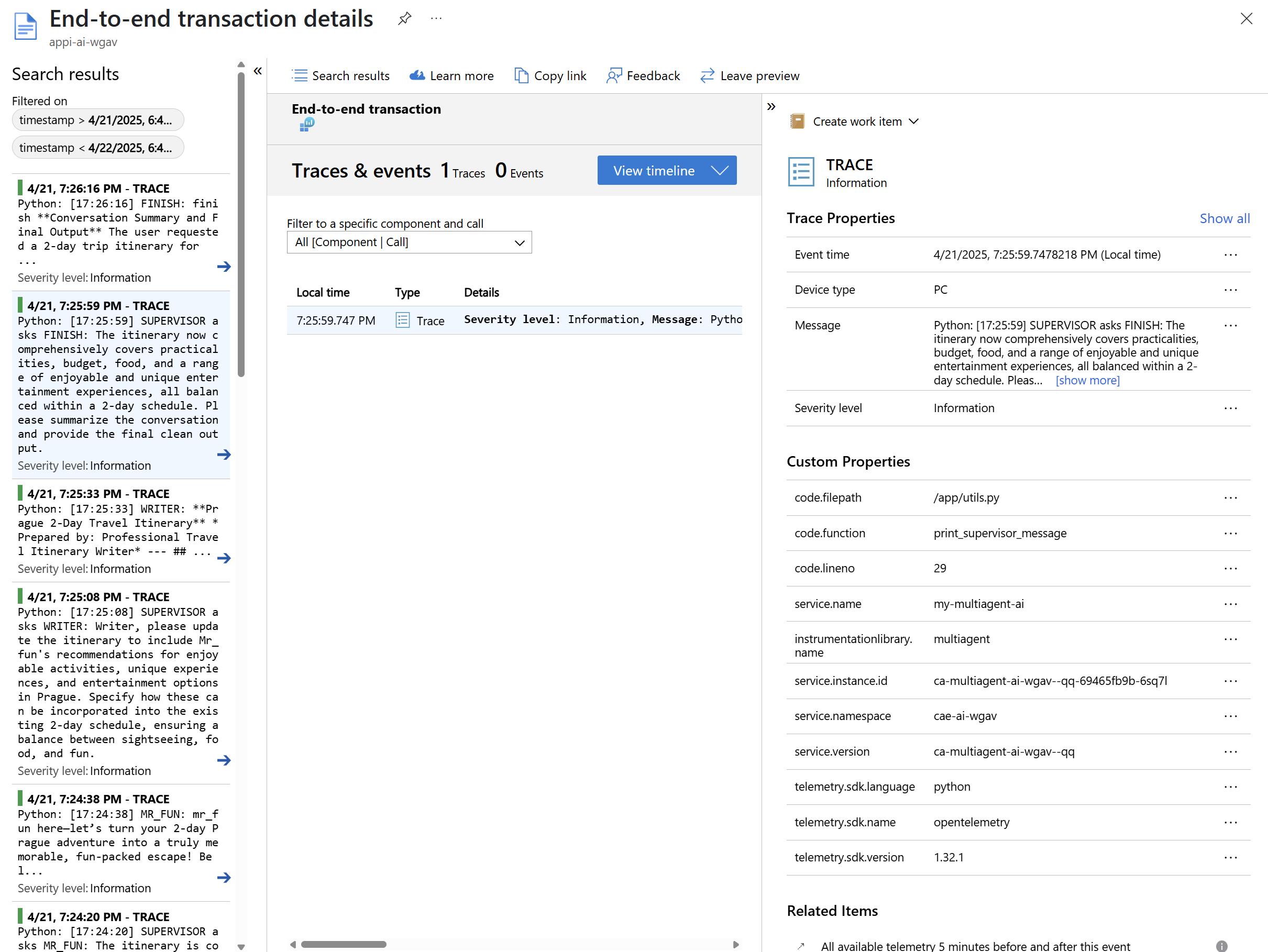
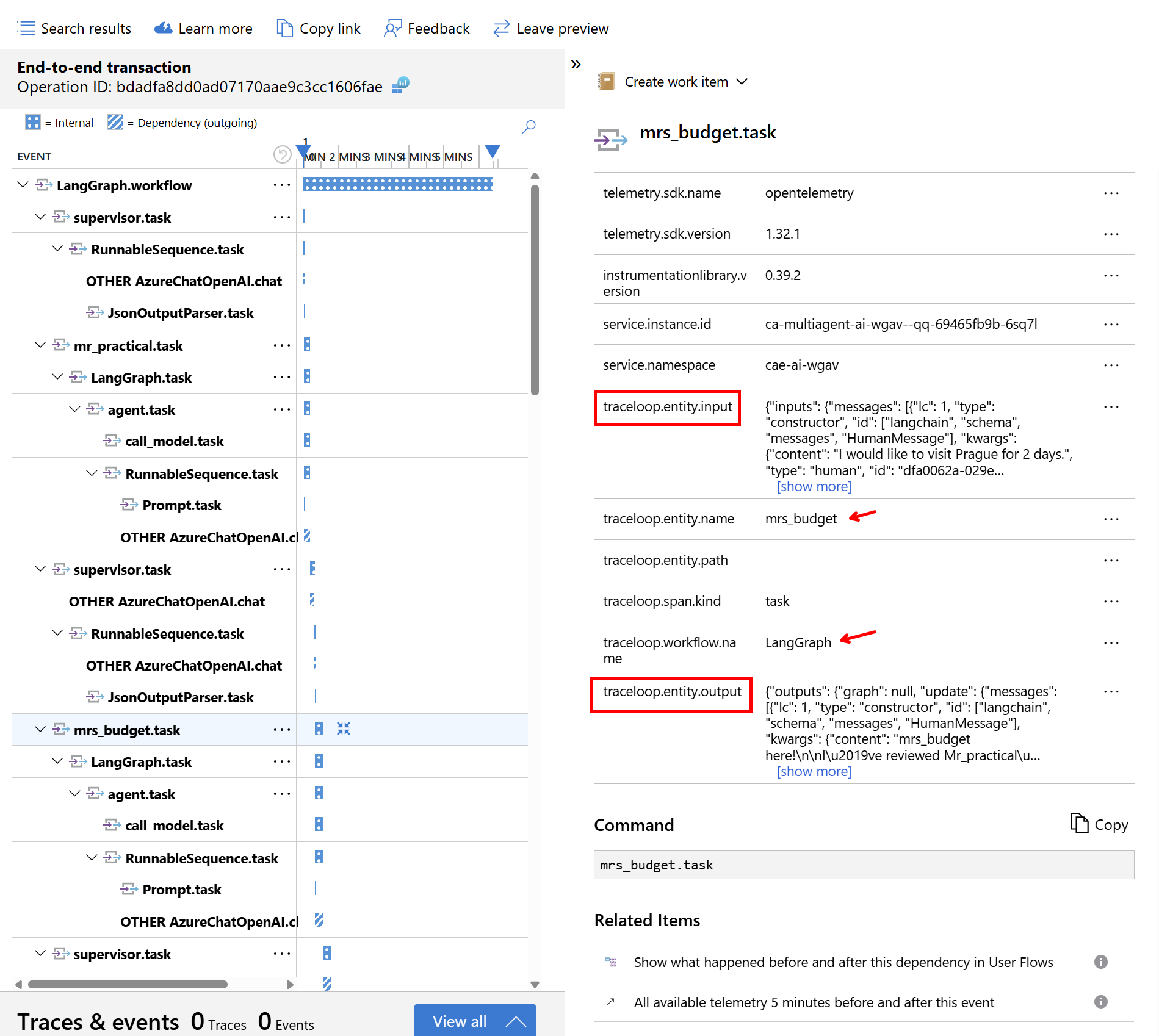
Pokud klikneme na Dependency, dostaneme korelované trasování - konkrétně tady vidím pro jeden dotaz všechny “otáčky” agentů a jejich časování.
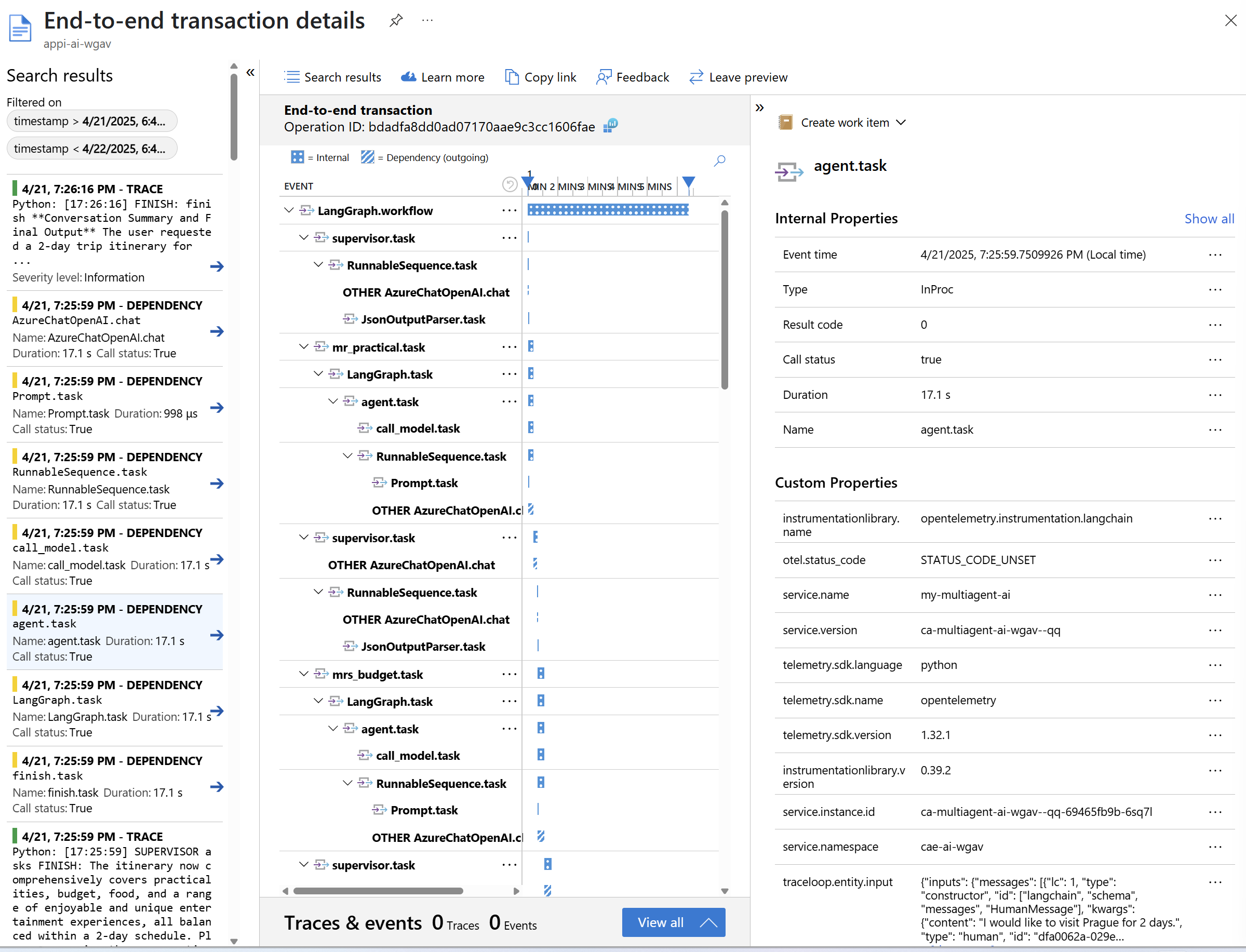
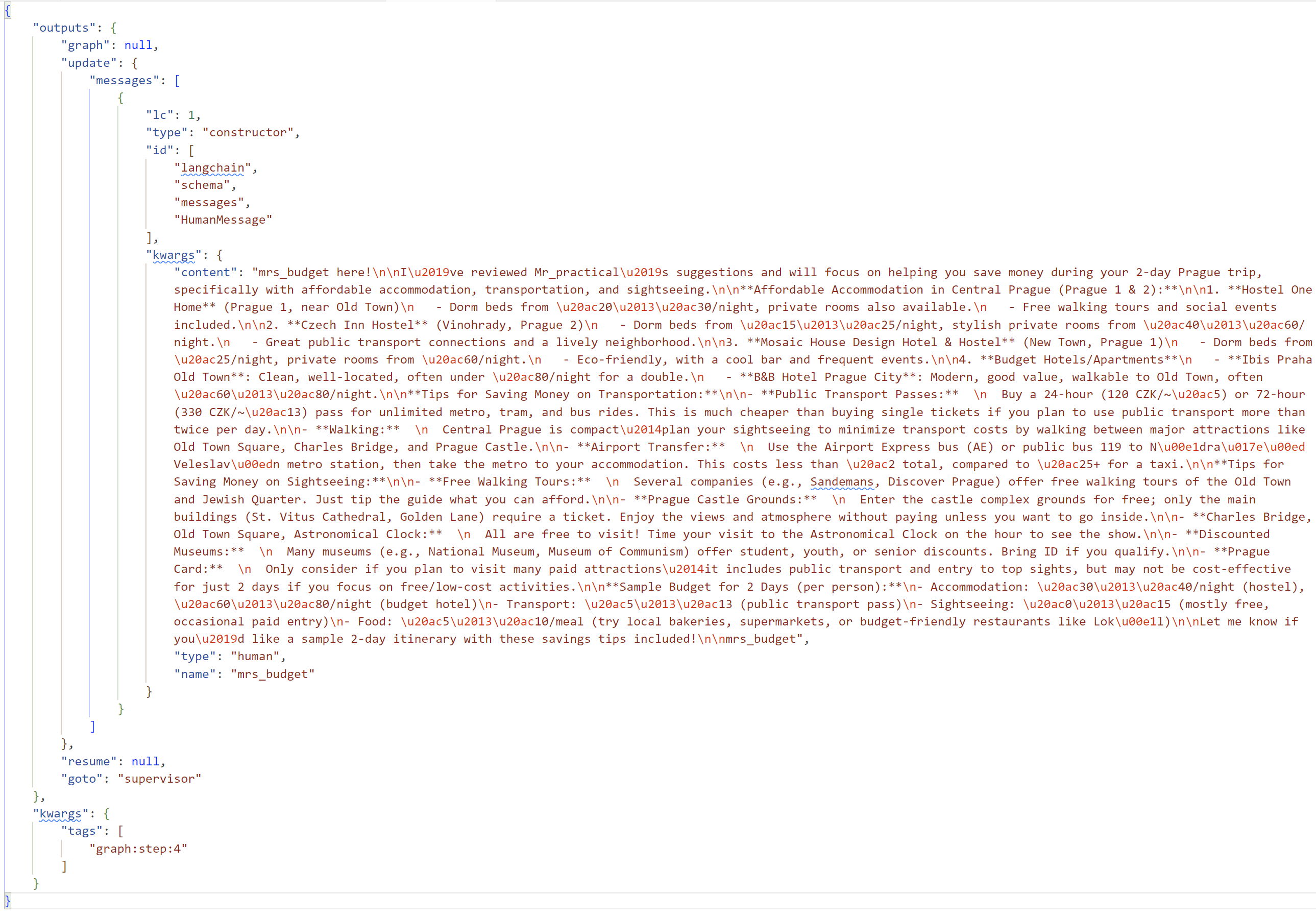
Trasování zahrnuje i detailní vstupy a výstupy do LLM.
Závěr
LangGraph autoinstrumentace v Pythonu funguje skvěle a umožňuje elegantně a snadno používat OpenTelemetry pro monitoring AI aplikací. Napojení na Azure Monitor Application Insights je zejména v Azure Container Apps velmi snadné díky spravovanému kolektoru, ale můžete samozřejmě přidat exportér přímo do aplikace, takže to střílí rovnou tam ať už běží kdekoli. A pro monitoring v lokálním nebo dev prostředí, nějaký rychlý náhled bez složitostí? Aspire dashboard z dílny .NET je na to úžasný.
Možná vás ale napadá jak se dívat na monitoring v enterprise prostředí, kde budou různé týmy a před LLM typicky postavíte API Management pro řízení přístupu k LLM, rozdělení zátěže, chytrý routing a využití PTU vs. PAYG nebo třeba ochrana přetížení či sémantický caching. Na to mrkneme někdy příště v rámci série o AI Hubu.