Vlastní data (RAG) pro vašeho AI agenta část první - krok za krokem s Python a PostgreSQL
Když se vás zeptám na nějaké faktické informace, třeba na něco z firemních směrnic, dám vám otázku z testu na Azure nebo jaký film doporučíte někomu, kdo viděl Matrix a chtěl by něco podobného, tak se můžete pokusit to udělat z hlavy. Budete mít možná problém si vzpomenout úplně přesně, možná uděláte i nějakou chybu, něco trochu popletete a když budu chtít, abyste citovali potřebné zdroje (na které stránce jakého dokumentu se o tom píše), tak často nebudete vědět, kde jste ke své znalosti přišli.
Srovnejte to ale s tím, když vám řeknu, že si klidně můžete před odpovědí pohledat po Internetu, prolistovat poznámky, prolétnout vytištěné směrnice nebo si zaklikat v Azure dokumentaci. Předpokládám, že tím se jednak výrazně zlepší přesnost vašich odpovědí a také mi řeknete, kde se o tom píše, ocitujete zdroje. Výborná věc. Jenže co když místo dobrého zacílení na určitou část dokumentace nebo směrnici vám nabídnu stránky z celé knihovny, ale bez přebalů a jakéhokoli řazení nebo indexování titulů? Pomůže to? Asi ano, ale bude vám to trvat mnohem déle, spotřebujete daleko víc energie a může se stát, že pokud naprostá většina stránek není pro odpověď důležitá, tak ztratíte pozornost a správné odpovědi si tam někde uprostřed nevšimnete.
To co jsem právě popsal funguje ve velkých jazykových modelech (LLM) taky a říká se tomu Retrieval Augmented Generation (RAG). Ideální je, když se model dostane k co nejlépe zacíleným dokumentům, ve kterých se skrývá odpověď a on tak může dávat naprosto přesné, rychlé a levné výstupy. Když se netrefíme a dáme mu dokumenty, které moc relevantní nejsou, odpovědi se zhorší. Když budeme mít model s velkým kontextem (podporou velkého množství vstupních tokenů) a nahrneme mu celou knihovnu, bude to drahé, pomalé a výsledky stejně nebudou tak dobré, jako v případě dobře zvolených referenčních dokumentů.
Dnes se chci zaměřit na problematiku hledání těch správných podkladů pro vaše LLM. Nebudeme tentokrát řešit přípravu dokumentů a jejich krájení ani složitější znalostní báze postavené na grafu provázaností a sumarizací. O tom jindy. Pracovat budeme s PostgreSQL, protože se tam můžu naučit, co se všechno děje. Pro svoje projekty ale určitě zvažte i Azure AI Search, který tohle všechno rovnou jednoduše umí a kromě toho řeší i problematiku krájení a nabírání.
V dnešním díle projdeme základní techniky jako je full-text search, embeddingy a vektorové vyhledávání, query rewriting, hybridní vyhledávání a re-ranking. Všechny techniky si ukážeme na jednoduchém příkladu s filmy a jejich popisky. Příště se pak pustíme do složitějších technik vyžadujících hlubší zpracování dat, hierarchické a grafové přístupy a sumarizace.
RAG s Python a PostgreSQL
Otevřete si prosím Jupyter Notebook na mém GitHubu. Najdete tam konkrétní výsledky a výstupy, doporučuji si vzít při čtení k ruce.
Celý příběh začíná tím, že vezmeme dokumenty, kterými budou popisky filmů, a vložíme je do PostgreSQL s tím, že vytvoříme kombinovaný sloupeček s názvem a popisem (ať se mi dobře dělají vektory). Potřebnou infrastrukturu jako jsou Azure OpenAI modely a Azure PostgreSQL Flexible Server a vše si můžete nahodit z mého Terraformu v příslušném adresáři. Než udělám samotný import je potřeba přidat některá rozšíření, která budeme používat, konkrétně:
- azure_ai extension, díky které můžu přímo z PSQL provolávat Azure OpenAI pro získání embeddingů (vektorů), ale i volat do kognitivních služeb Azure (extrakce entit, PII identifikace a tak podobně) nebo modelů nasazených v Azure Machine Learning
- pgvector extension, který nám umožní ukládat embeddingy přímo do PostgreSQL a provádět nad nimi vyhledávání
- pg_diskann extension, který nám umožní provádět vyhledávání v embeddingových vektorech rychleji a efektivněji
Založím tabulku, přidám sloupeček embedding s 2000 dimenzemi, přidám další sloupeček full_test_search pro tsvector (statistika pro full text, víceméně kořeny použitých slov a jejich výskyty) a přidám diskann index. Pak vložím data a následně k nim přidám embeddings s využitím SQL příkazu UPDATE společně s funkcí z azure_ai, takže databáze si do Azure OpenAI služby bude volat sama a zařídí si to.
Co je embedding a vector search?
Ve strojovém učení je časté, že chceme svět s jeho velkou variabilitou a složitostí zjednodušit na menší počet vlastností, defacto ho zkomprimovat do menšího a to ztrátovým způsobem (nejde tedy o zip, ale spíš si představte něco jako MP3). Představme si třeba, že pro text připravíme score v několika dimenzích, například “míra veršovanosti”, “míra humoru” a tak podobně. Pokud takových vlastností použijeme stovky, tak budou mít dobrou vypovídací schopnost, dobře budou reprezentovat původní text. Ve strojovém učení ale nebudeme AI diktovat, co to má být za dimenze a vlastnosti, to necháme na něm. Tyto techniky jakési extrakce najzásadnějších vlastností s co největší vypovídací schopností, tyto vektory (vyjmenovaná čísla, score za jednotlivé vlastnosti, dimenze), embeddingy, se pak používají pro reprezentaci původního vstupu a významovou extrakci jak u textů (to je náš případ), extrakci vlastností z obrázku (například pro interpretaci výsledků klasifikací, čili pes/kočka), tak třeba u difúzních modelů (generování obrázků a videa).
Strojové učení našlo pravidla, jak extrahovat score v jednotlivých dimenzích tak, aby byl text co nejvíce zachován a díky masivní kompresi se soustředí na význam. Je jedno jak to řeknu, ale podstatný je význam - ten je tedy to nejdůležitější a je proto vhodným embeddingem v omezeném prostoru. Tyto dimenze skutečně představují nějaký n-rozměrný prostor, říkáme mu typicky latentní prostor, a každý text je tak zasazen do nějakého bodu tohoto prostoru. Z různých textů umístěných v prostoru pak můžeme usuzovat na míru jejich příbuznosti a významové podobnosti. Mohli bychom například změřit euklidovskou vzdálenost mezi těmito body, udělat skalární součin nebo úhel mezi přímkou z počátku do jednoho bodu a do druhého (cosinus - to použijeme my, protože najde podobnost i při rozdílné škále).
Jak v tom tedy hledat? Nejprve ke všem popiskům filmů nechám model vytvořit embedding, ten si uložíme a až pak dostaneme dotaz, tak i ten zasadíme do latentního prostoru a koukneme, které body jsou dotazu nejpodobnější.
Full-text řešení a vylepšení dotazu
Nejprve ale nasaďme full-text, kdy PostgreSQL prošel jednotlivé popisky, identifikoval kořeny slov, spočítal si je a statistiky si u každého filmu uložil. Vzneseme dotaz, proženeme full-textem a necháme si prvních 10 nejbližších odpovědí a s těmi budeme pracovat. Jednotlivé otázky a odpovědi najdete v mém odkazovaném Jupyter notebooku a následně je předhodíme LLM pro formulaci odpovědi.
První pokus nic moc. Otázka na Abby vede jen na jeden film (což je málo) a ostatní také nejsou moc dobré. Potíž je, že full-text search není ChatGPT, takže otázka “What movies are about Abby?” je značně nevhodná, protože tím hledáme všechna tato slova z nichž kromě Abby vlastně žádné není důležité a nepotřebujeme ho v textu vůbec mít.
Pojďme provést tzv. question rewriting, tedy necháme menší jazykový model (já použiji gpt-4o-mini) dotaz přeformulovat a optimalizovat pro full text. V notebooku vidíte tento scénář ve výstupech včetně přeformulovaného dotazu a na Abby máme tentokrát výsledky mnohem lepší (4 filmy). Nicméně druhé dva dotazy jsou stále špatné - hledáme filmy jako Star Wars, ale ne Star Wars, což ale full-text samozřejmě nemá jak pochopit, takže nám právě najde všechny Star Wars a to nechceme - ty už tazatel všechny viděl. Asi to bude chtít hledat spíše význam.
Sémantické vyhledávání a vylepšení dotazu
Třetí varianta v notebooku je sémantický search, tedy vektorové hledání podobností z embeddingů. Nicméně na první otázce, tedy filmy kde je postava Abby, nám to selhává. Tímto příkladem jsem chtěl demonstrovat, že vektory jsou povětšinou skvělé, ale v okamžiku, kdy vlastně potřebujeme hledat konkrétní krátkou faktickou informaci typu číslo faktury, tak to moc nedávají. Nicméně druhé dvě otázky jsou teď určitě lepší, byť Star Wars jsou stále problém. Přestože tentokrát už máme ve výsledcích i podobné sci-fi filmy, tak přímo těch Star Wars co nepotřebujeme je tam pořád dost. Je to něco, s čím v jednoduchých scénářích nic moc neuděláme - na embedding je to moc komplikovaná konstrukce. V praxi bychom asi museli dávat do kontextu filmů víc a LLM si to v seznamu najde. Embeddingy tam ve finále ty správné věci mají, i když trochu zastřené těmi Star Wars a LLM to v tomhle počtu v klidu dá.
Stejně jako v předchozím případě může dávat smysl dotaz přeformulovat, než podle něj budeme hledat. V mém případě jsem použil opět menší LLM (gpt-4o-mini) s cílem otázku učinit jasnou, dobře formulovanou a bez překlepů a gramatických chyb. Zejména u vstupu od skutečného uživatele tohle pomůže k lepšímu vyhledávání. U mě rozdíl není zásadní, ale je viditelný třeba u filmů podobných Star Wars. Existuje i pár dalších technik z nichž asi nejznámější je HyDE (Hypothetical Document Embedding). Tam necháte LLM na základě otázky vysnit si fiktivní dokument, který by byl ideálním podkladem pro odpověď na takovou otázku a podle něj pak provedete vektorové hledání. To někdy výborně funguje, protože dokumenty samozřejmě nejsou formulované jako otázky a takhle využijete kreativních schopností LLM si vymýšlet dokumenty, které by odpovídaly a pak podle nich najít dokumenty skutečné.
Hybridní řešení a re-ranking výsledků
Je zřejmé, že na některé otázky je vhodné sémantické hledání, ale jinde je úspěšnější klasický full-text. Pojďme tedy používat oboje a nasadit hybridní hledání. SQL dotaz trochu naboptnal, ale nic hrozivého. Nejprve provedu full-text search a vrátím si 15 výsledků, následně uděláme sémantický search a dostanu také 15 výsledků. Do obou tabulek jsem si přidal pořadové číslo (index), prioritu, aby se mi to pak dobře slévalo a taky sloupeček s použitou metodou. Následně udělám union obou tabulek a proženu to dalším dotazem, kde provedu dedupikaci podle ID filmu (často se totiž stane, že obě metody uvedou stejný film a ve výsledcích mi stačí jen jednou). V závěru pak takto odfiltrované výsledky vezmu a seřadím je podle priority (indexu) a oříznu po 10 řádcích.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
WITH fulltext AS (
SELECT
id,
title,
overview,
combined_text,
ts_rank(full_text_search, plainto_tsquery('english', %s)) AS score,
'fulltext' AS method,
ROW_NUMBER() OVER (ORDER BY ts_rank(full_text_search, plainto_tsquery('english', %s)) DESC) AS index
FROM movies
ORDER BY score DESC
LIMIT 15
),
semantic AS (
SELECT
id,
title,
overview,
combined_text,
(embedding <=> azure_openai.create_embeddings('text-embedding-3-large', %s, 2000, max_attempts => 5, retry_delay_ms => 500)::vector) AS score,
'semantic' AS method,
ROW_NUMBER() OVER (ORDER BY (embedding <=> azure_openai.create_embeddings('text-embedding-3-large', %s, 2000, max_attempts => 5, retry_delay_ms => 500)::vector)) AS index
FROM movies
ORDER BY score
LIMIT 15
),
combined_results AS (
SELECT * FROM fulltext
UNION ALL
SELECT * FROM semantic
),
deduped_results AS (
SELECT DISTINCT ON (id)
id,
title,
overview,
combined_text,
score,
method,
index
FROM combined_results
)
SELECT * FROM deduped_results
ORDER BY index
LIMIT 10;
Výsledky na Abby jsou někde mezi full-textem a sémantikou, což asi logicky celkem odpovídá. To znamená, že jsem odstranil extrémní situace, které jsou špatné - Abby přes sémantiku a Star Wars přes full-text.
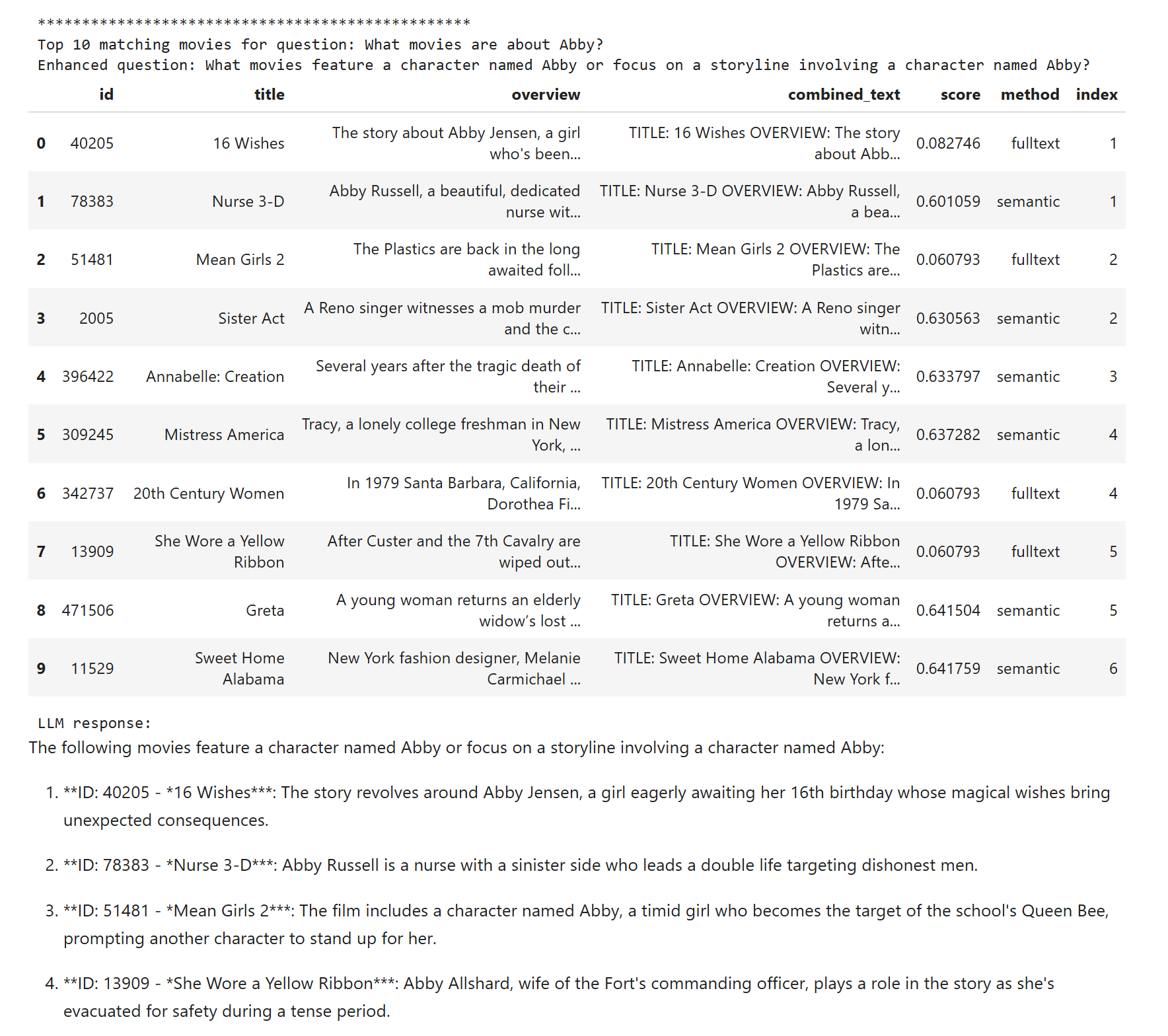
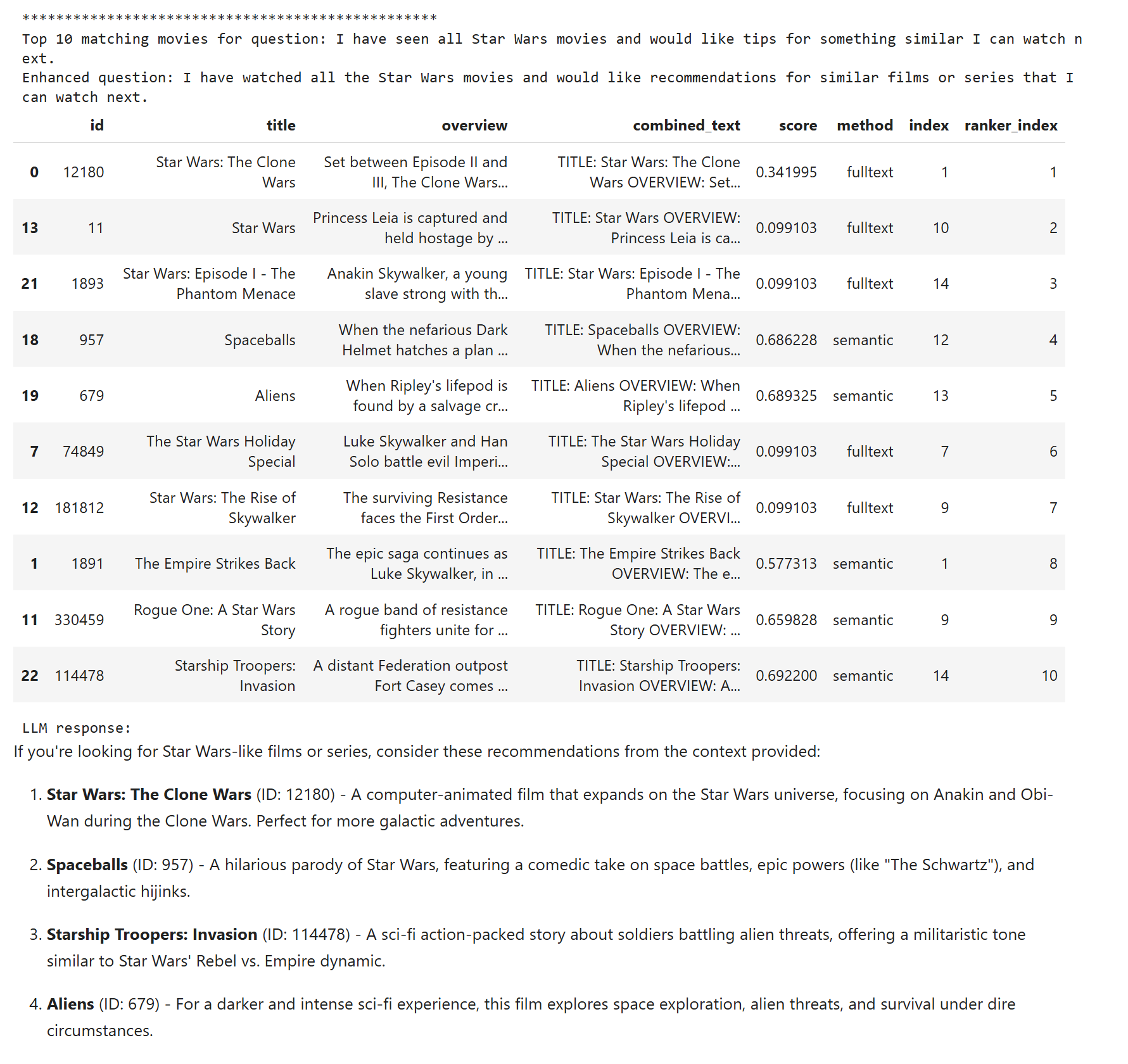
Pojďme do toho ale teď zamontovat další magii - re-ranking. Jde v zásadě o typicky malý jazykový model, který je specificky trénován na schopnost zhodnotit relevanci dokumentu k dané otázce. Je příliš velký na to, abych podle něj dělal hledání o složitosti O(n), ale na druhou stranu dostatečně rychlý na to, abych pár desítek či set předvybraných výsledků podrobil zkoumání. Protože zatím není k dispozici jako extension pro PostgreSQL v Azure Flexible Server, tak to dělám na serverové straně v Pythonu a používám jednoduchý model MultiBERT, který má asi jen 33M parametrů a v pohodě poběží i v CPU. Zatímco běžné LLM jsou stylu decoder, tohle je encoder model (cross-encoder). SQL dotaz je stejný, jen si vezmu všech 30 výsledků, MultiBERTem je seřadím dle relevance a zase vezmu top 10 a pošlu do LLM. Výsledky jsou nejlepší!
Abby je správně.
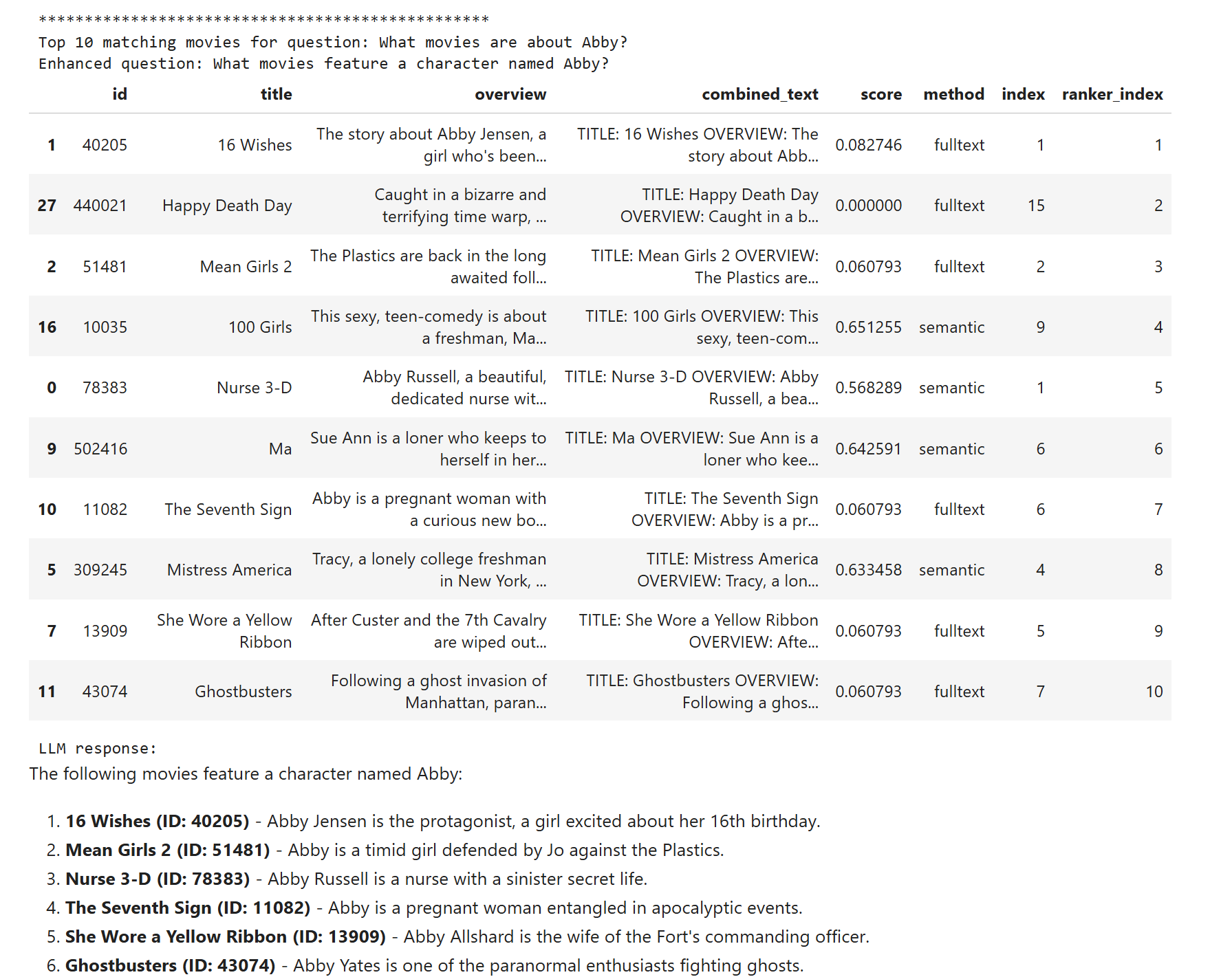
Filmy podobné Star Wars, těžká disciplína, takže výsledek pořád není ideální, ale oproti ostatním řešením je nejlepší.
Kam odtud dál
RAG metody, které jsme si společně vyzkoušeli, nejsou žádná raketová věda, ale je vidět, že použité techniky vedou k značnému zlepšení výsledků. Nicméně zůstává pár problémů. Například agregační dotazy nejsou dobře pokryté (o to jsem se snažil ve třetí otázce), protože nemáme žádné sumarizované údaje k dispozici. Další co bude problém jsou situace, kdy potřebujeme graf informací - filmy, kde je nějaká konkrétní postava, pokud bychom měli další údaje tak hledání podle herců, režisérů, žánrů a tak podobně. Komplexní práce s takto propojenými daty je mimo možnosti toho, co jsme si ukázali. No a na to se zaměříme někdy příště - zkusíme data vzít, extrahovat z nich klíčové atributy a ty mezi sebou vztahově propojit a ještě přidat sumarizační a agregované pohledy. Tedy si data pěkně předžvíkat a poukládat tak, abychom mohli prohledávat v grafu nebo v agregačních dotazech. To dělá například GraphRAG a na ten se příště zaměřím.
Ještě nutno říct, že jsem použil PostgreSQL, protože mě fascinuje jeho univerzálnost a rozšiřitelnost a je to nejlepší způsob, jak se věci naučit a zjistit co se tam děje. Nicméně objevuji tak trochu kolo a tak pokud jste v cloudu, tak zkuste rovnou použít Azure AI Search, který nejen co jsme dělali, ale i další techniky má rovnou v sobě. Navíc je to nejen řešení pro ukládání a hledání, ale i pro zpracování vstupů ať už jde o indexaci, extrakci, řezání a další součásti RAG, které rozebereme také někdy příště.
LLM není databáze, data uložená ve váhách modelu vedou často na špatné výsledky. Kvalitní data a chytrý přístup k nim nejsou pro lidstvo nový problém - tak jak se hodí lidem, tak se hodí a budou hodit i vašim AI agentům.