Aplikační architektura škálovatelného AI chatu - observabilita
Ve škálovatelné distribuované architektuře jsou určitě větší nároky na observabilitu. Pro účely tohoto článku jsem vybral její za mě zásadní úsek a to jsou:
- Logování
- Trasování requestů pro možnost sledovat flow requestů napříč službami nebo identifikaci slabých míst
- Metriky pro sledování výkonu a zdraví systému
- Spotřeba zdrojů, zejména LLM tokenů, přes nejrůznější dimenze pro možnost optimalizace nákladů a počítání maržovosti (včetně nákladů per-user, per-session apod.)
Dnes se tedy nebudu zaměřovat na alerting a automatizované reakce na incidenty ani na komplexní KPI/SLO/SLA metriky provázané s byznys ukazateli (například korelace na pokles času, který uživatel tráví se službou).
Veškerý kód najdete na mém GitHubu
Technologický základ - Open Telemetry pro všechno
Celé řešení observability mám postaveno na standardu Open Telemetry, který je dnes vhodný jak na trasování, tak logování a sběr telemetrie. Implementuji standardní Open Telemetry SDK pro Python a přidávám auto-instrumentaci od Azure (zajistí trasování Azure služeb, v mém případě volání do Service Bus nebo CosmosDB), instrumentaci FastAPI a OpenAI SDK (trasování LLM volání včetně spotřeby tokenů a podle nastavení i obsahu zpráv). Podobným způsobem bych mohl přidat Redis a cokoli dalšího bych v kódu používal. To všechno je potřeba posílat do nějakého backendu, který data bude zpracovávat a umožní jejich sběr, prohledávání a vizualizace. V mém případě to jsou Application Insights, součást Azure Monitoru a k tomu jsem do kódu přidal Azure Monitor exportér, který standardní Open Telemetry odešle do Azure jeho formátem. Mohl bych také použít kolektor v Azure Container Apps a aplikace nechat odesílat přes OLTP do kolektor, kde se teprve data přepošlou do Azure Monitor nebo dalších podporovaných systémů typu Datadog a mnohé další. Zvolil jsem exportér do kódu, abych mohl kontejnery běžet i u sebe na notebooku a měl jednoduchou a unifikovanou cestu pro monitoring ať už do Application Insights nebo třeba pro rychlý lokální test do Aspire dashboardu.
V aplikacích jsem přidal do spanů své vlastní dimenze, abych mohl na backendu mít další důležité pohledy. Konkrétně mi šlo hlavně o jméno uživatele, session ID (v mém případě to je myšleno jako ID konverzace), message ID (konkrétní zpráva a odpověď), ale jsou tam i některé další. Aby to bylo konzistentní, zvolil jsem cestu vlastního span procesoru, který se napojí do instrumentace jako první (před Azure a OpenAI SDK) a do každého span přidá tyto dimenze jsou-li známy.
Pro demo účely trasuji úplně všechno, takže to nese nezanedbatelné náklady - v praxi bych například určitě použil sampling na cestu LLM worker chunk do fronty, SSE služba chunk z fronty a stream na klienta, kde chodí hodně spanů a stačí samplovat na jedno procento a tak podobně.
Vizualizace v AI Foundry pro LLM-based pohled na trasování
Azure AI Foundry nabízí samozřejmě monitoring nasazených modelů, ale to jsou jen velmi hrubé informace. Můžete ho ale jednoduše namířit na váš Application Insights a využít jeho vizualizaci, která je specificky zaměřena na práci s LLM. Na rozdíl od přímo Application Insights, které se zaměřují na monitoring aplikací a systémů, je Foundry pohled velmi přívětivý pro neprogramátory.
Takhle vidíme všechny spany s nenulovými tokeny (tzn. nechci do tohoto pohledu například Service Bus zprávy nebo requesty na aplikační API).
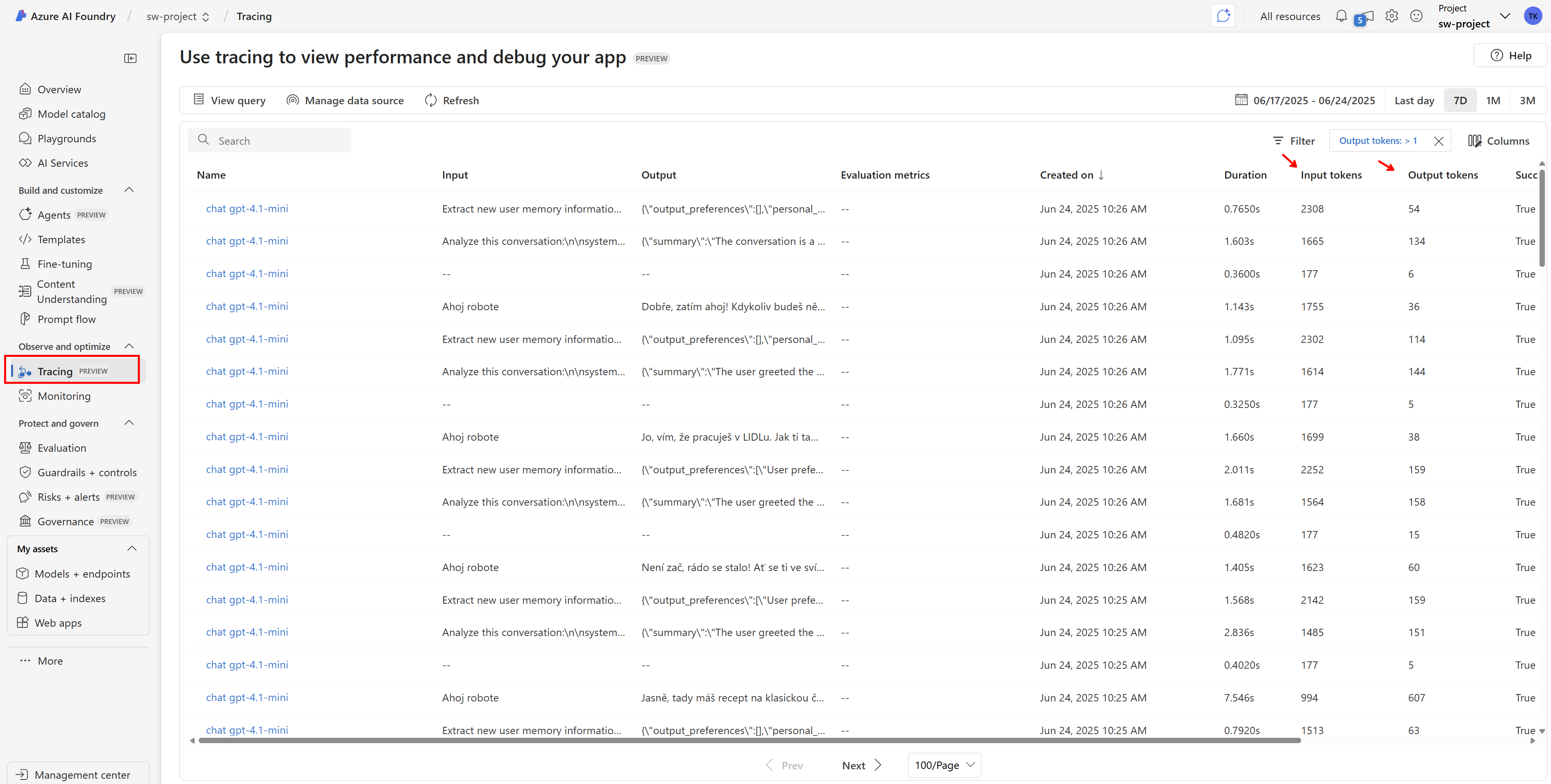
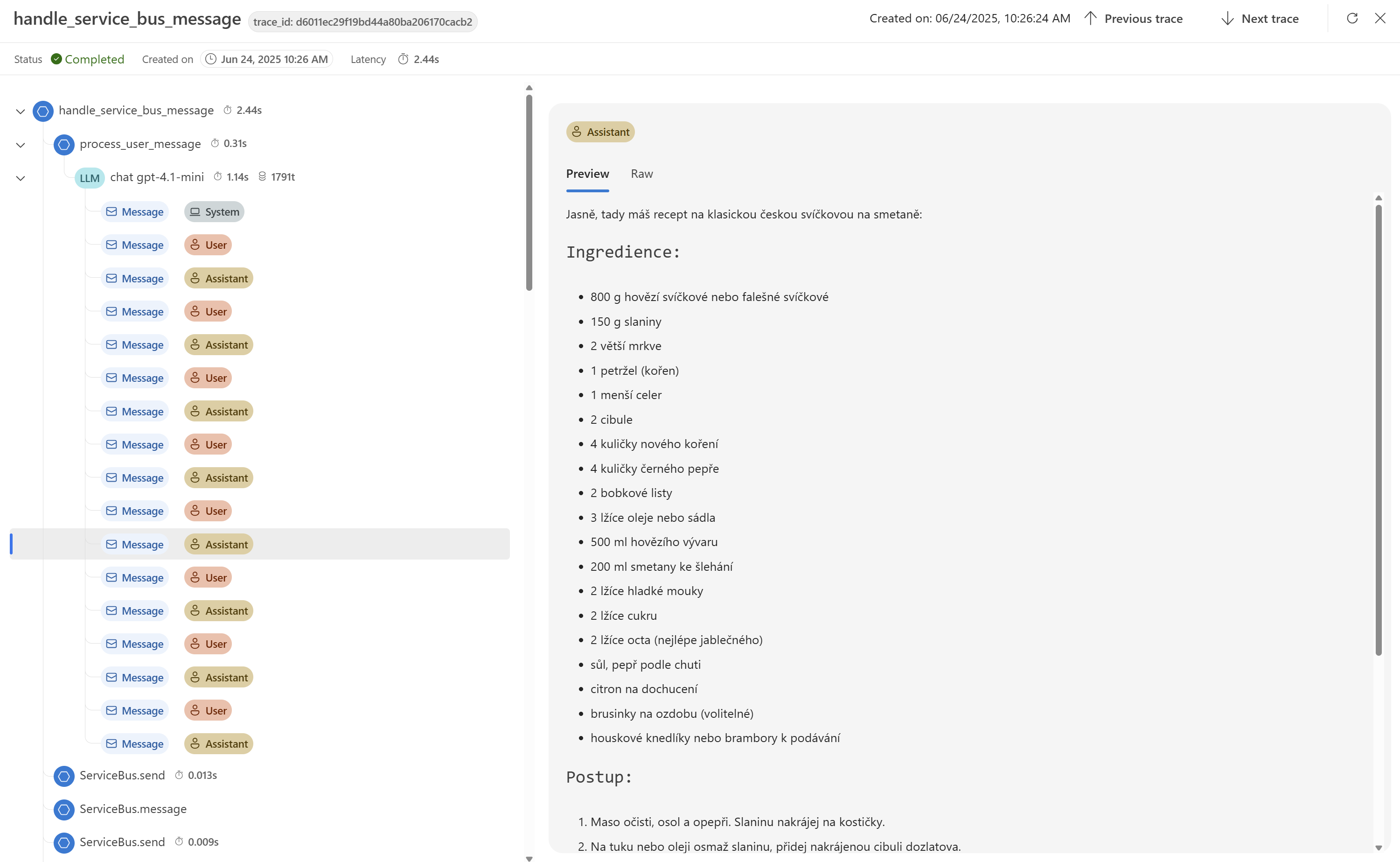
Po rozkliknutí dostávám pěkně i obsah konverzace (to samozřejmě není nutné, někdy to nechcete nebo nesmíte, ale jindy se to zase hodí).
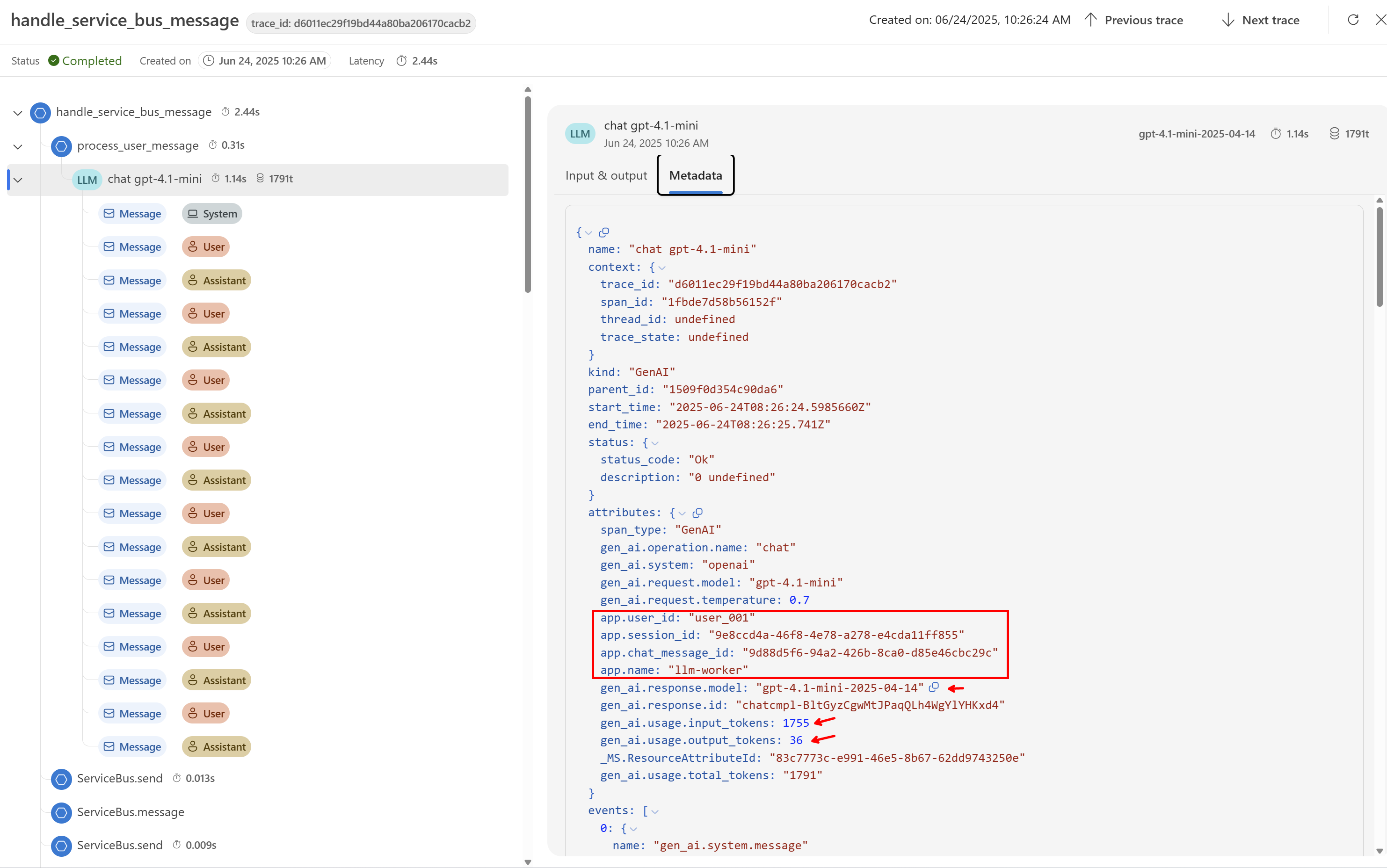
Když se podívám na metadata, jsou tam jasně vidět námi přidané dimenze jako je přihlášený uživatel aplikace. To je skvělé, ale Foundry není dělané na to, abychom toho mohli dál využít - to uděláme jinde.
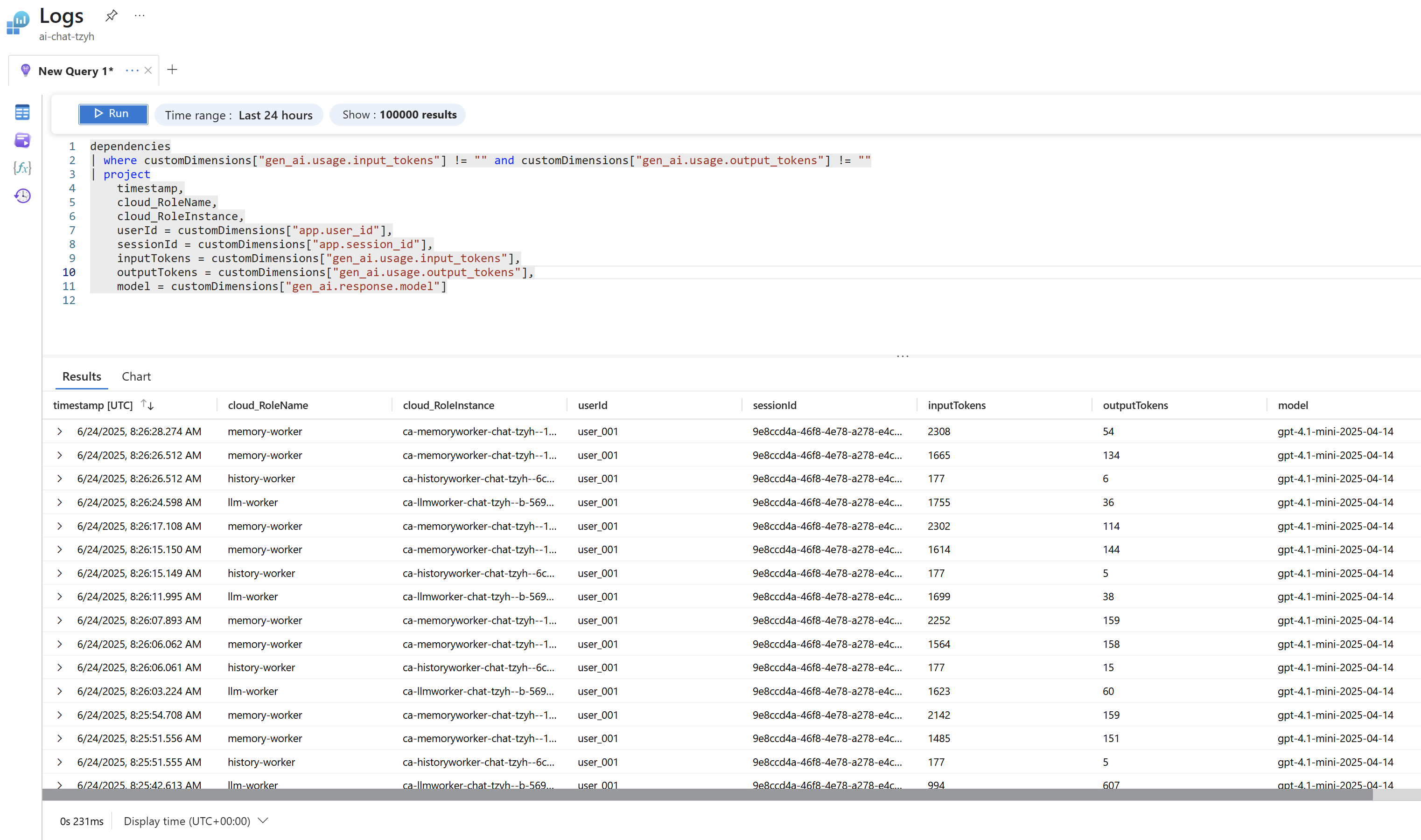
Surové query nad sesbíranými daty a agregáty
Než si ukážeme zabudované možnosti Application Insights, rád bych zmínil, že veškerá data jsou uložena v systému Log Analytics, což je analytická append-only databáze, která umožňuje vytvářet jednoduché i sofistikované dotazy v jazyce KQL (Kusto Query Language). Takhle si třeba můžu zobrazit LLM volání.
Kolik tokenů spotřebovala každá moje mikroslužba? To je myslím velmi zajímavý pohled a vězte, že není problém to rozpadnout dál třeba na instance (jednotlivé běžící kontejnery) nebo třeba přidat dimenzi prostředí.
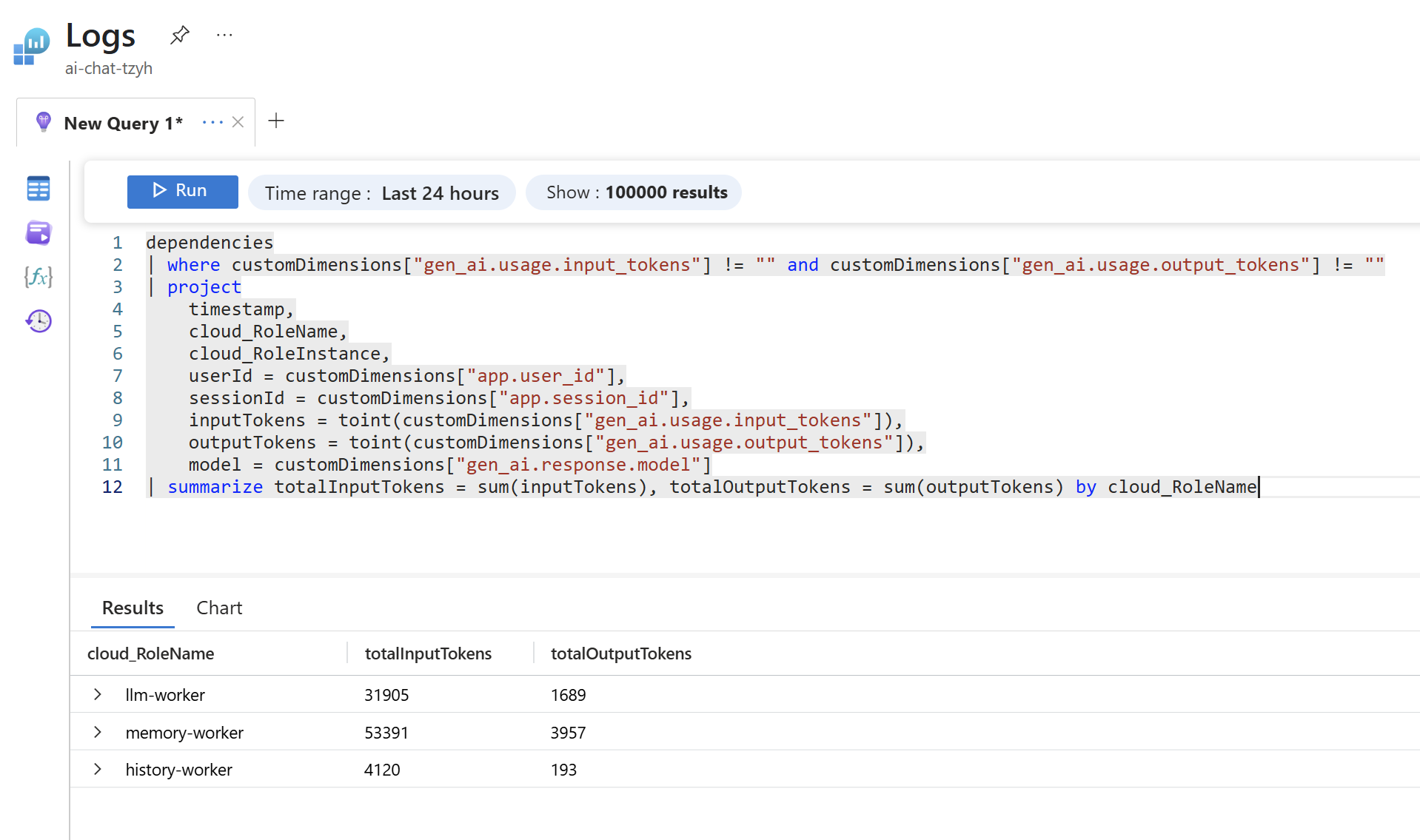
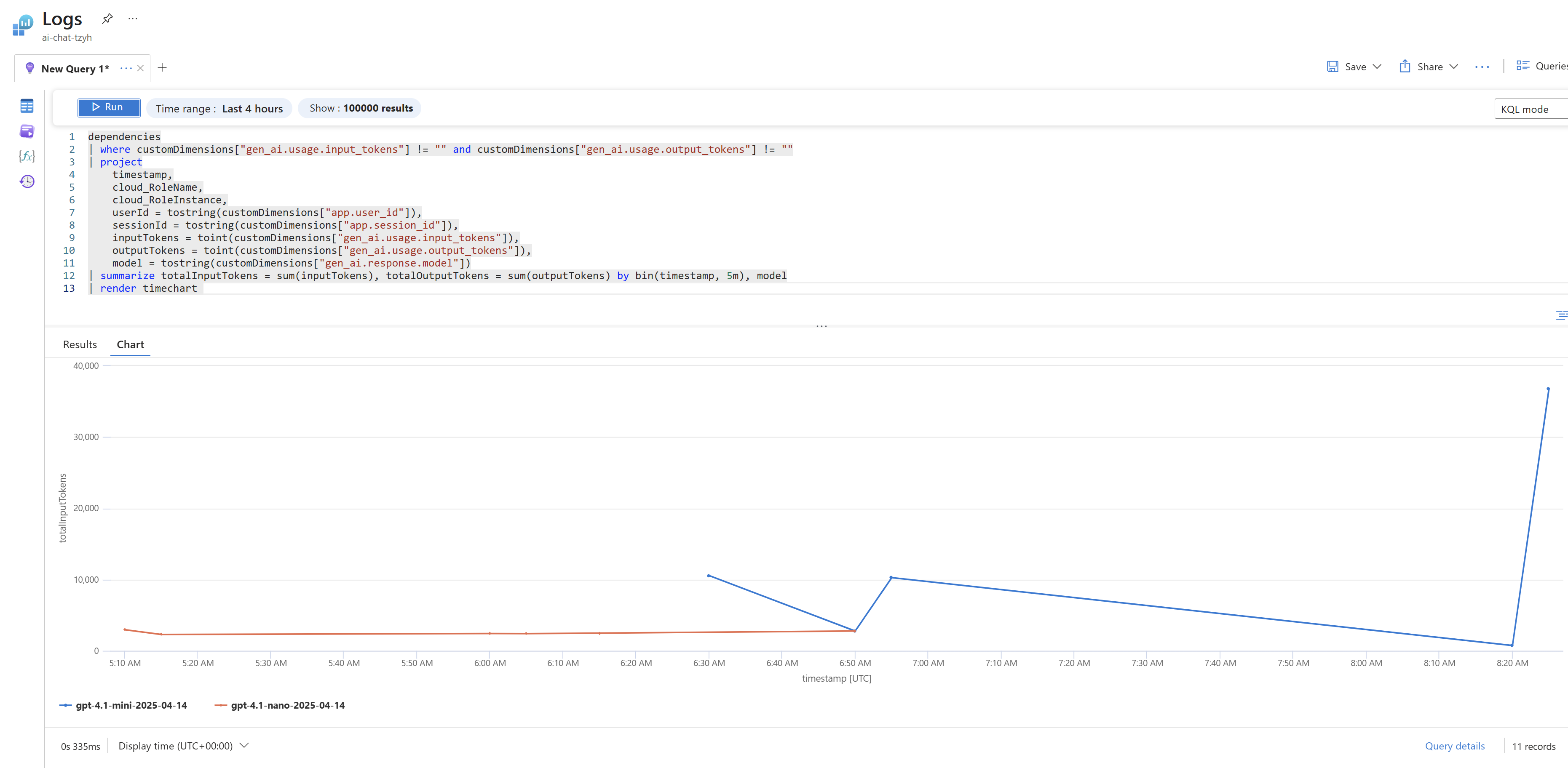
A co třeba spotřeba za jednotlivé modely v čase?
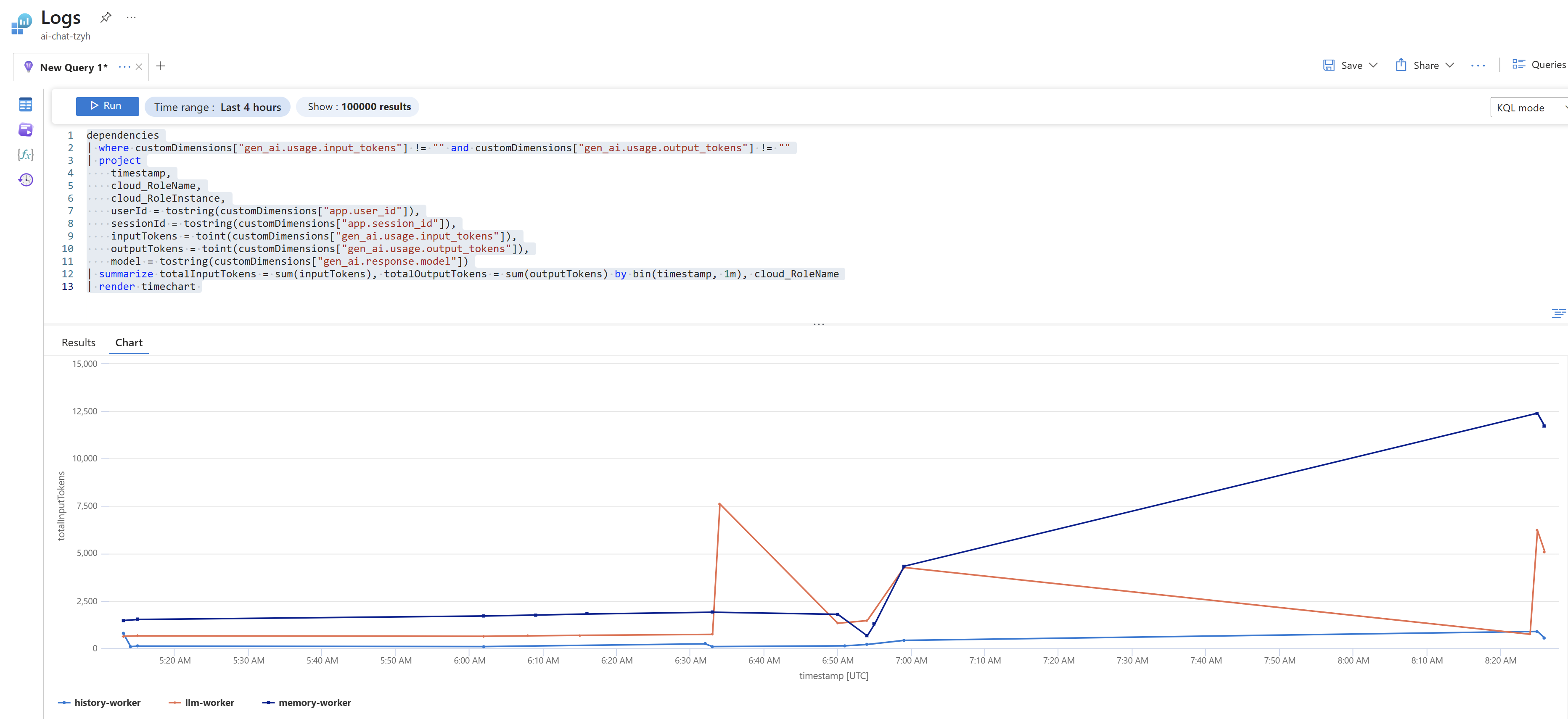
Nebo totéž za aplikační komponenty.
Nebo součet vstupních a výstupních tokenů za aplikační komponentu.
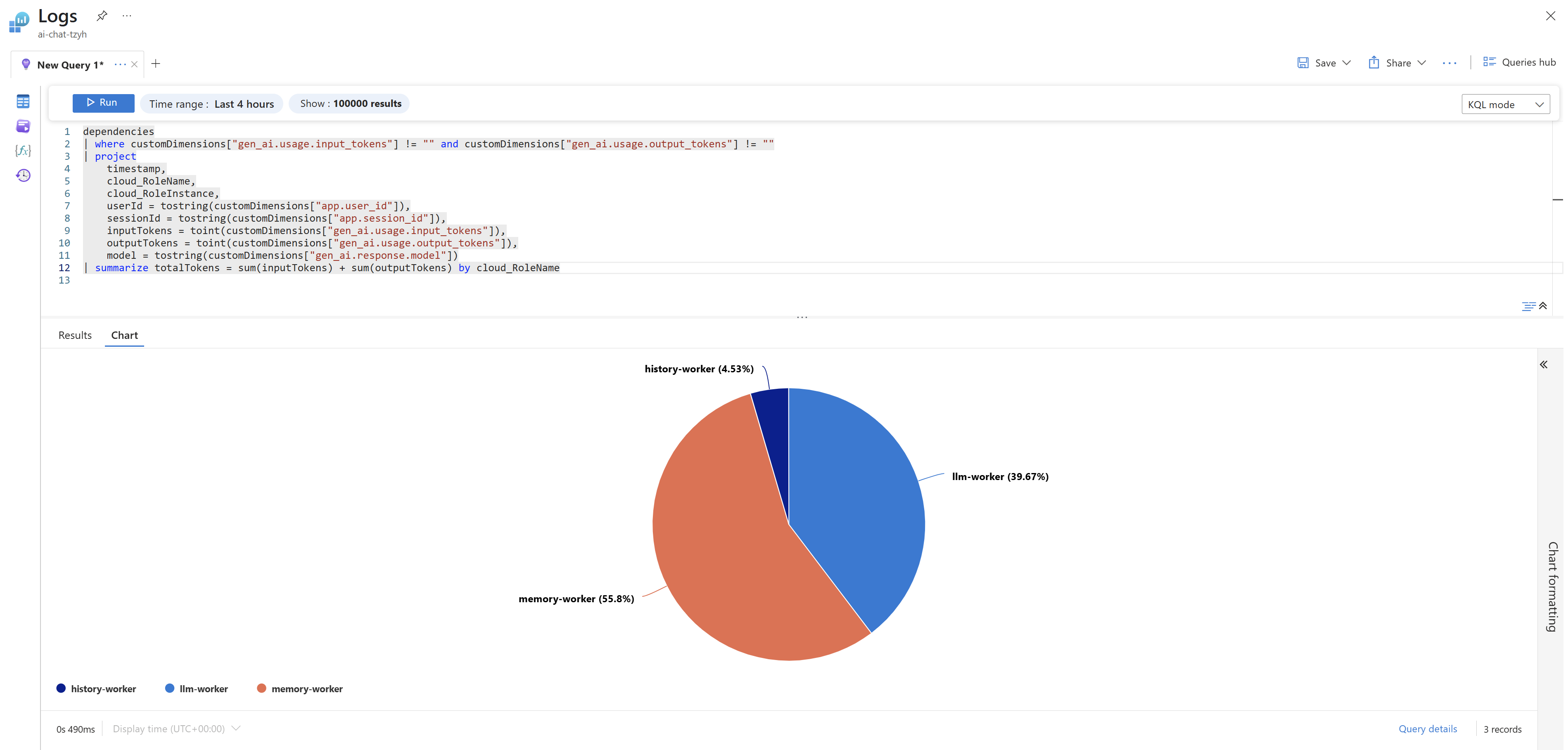
Vizualizaci v rámci query okna jsou samozřejmě jen základní a slouží pro ilustraci. Podstatné je, že se správným KQL dotazem můžete vizualizaci udělat třeba v Azure Workbooks nebo v Grafana.
KQL je velmi mocný jazyk, který obsahuje i složitější funkce a korelace. Lze tak například řešit detekci anomálií nebo predikci v časové řadě a dívat se tak nejen na aktuální stav, ale i trendy, vývoj, sezónnost apod. Joiny umožňují korelace s čímkoli dalším, tak například můžete mít tabulku, která udržuje mapování uživatelského jména na zaplacený tier (zdarma, Plus, Pro, Diamant atd.). Pokud tedy takovou informaci nedáte přímo do spanů, lze ji získat až při analýze dat právě přes join. Stejně tak jde z query vytvářet alerty, takže lze dělat komplexní pravidla a spouštět Logic App, která pak může reagovat jakkoli - poslat email, Teams zprávu, začít komunikovat s dotčeným uživatelem a tak podobně.
Aplikační a systémový pohled na trasování
Pro aplikační a systémový pohled je nejlepší použít Application Insights, který je součástí Azure Monitoru. Takhle třeba vypadá živá mapa aplikace.
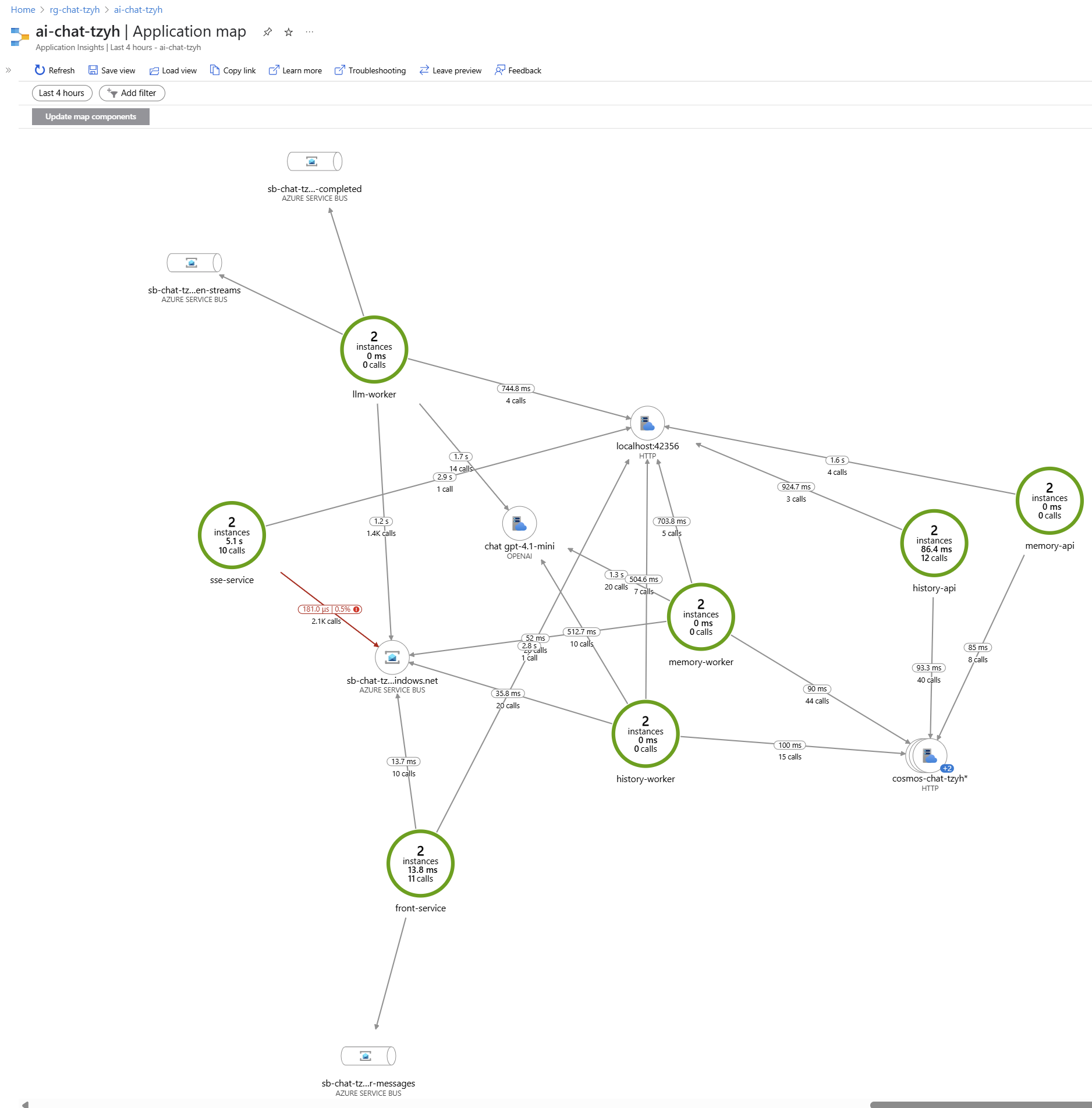
Můžu třeba kliknout na nějakou linku a zjistit, jaká byla nejpomalejší volání apod.
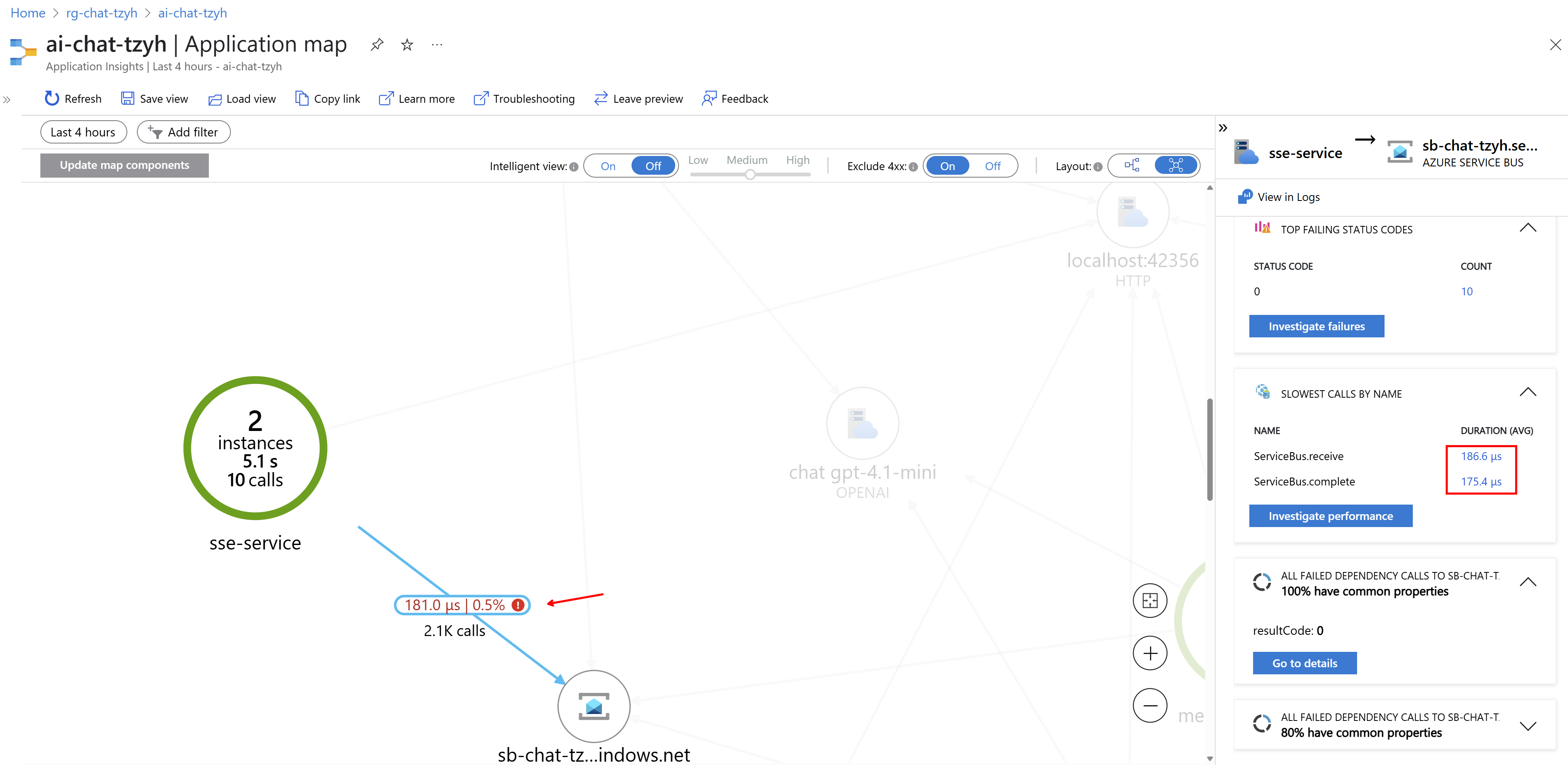
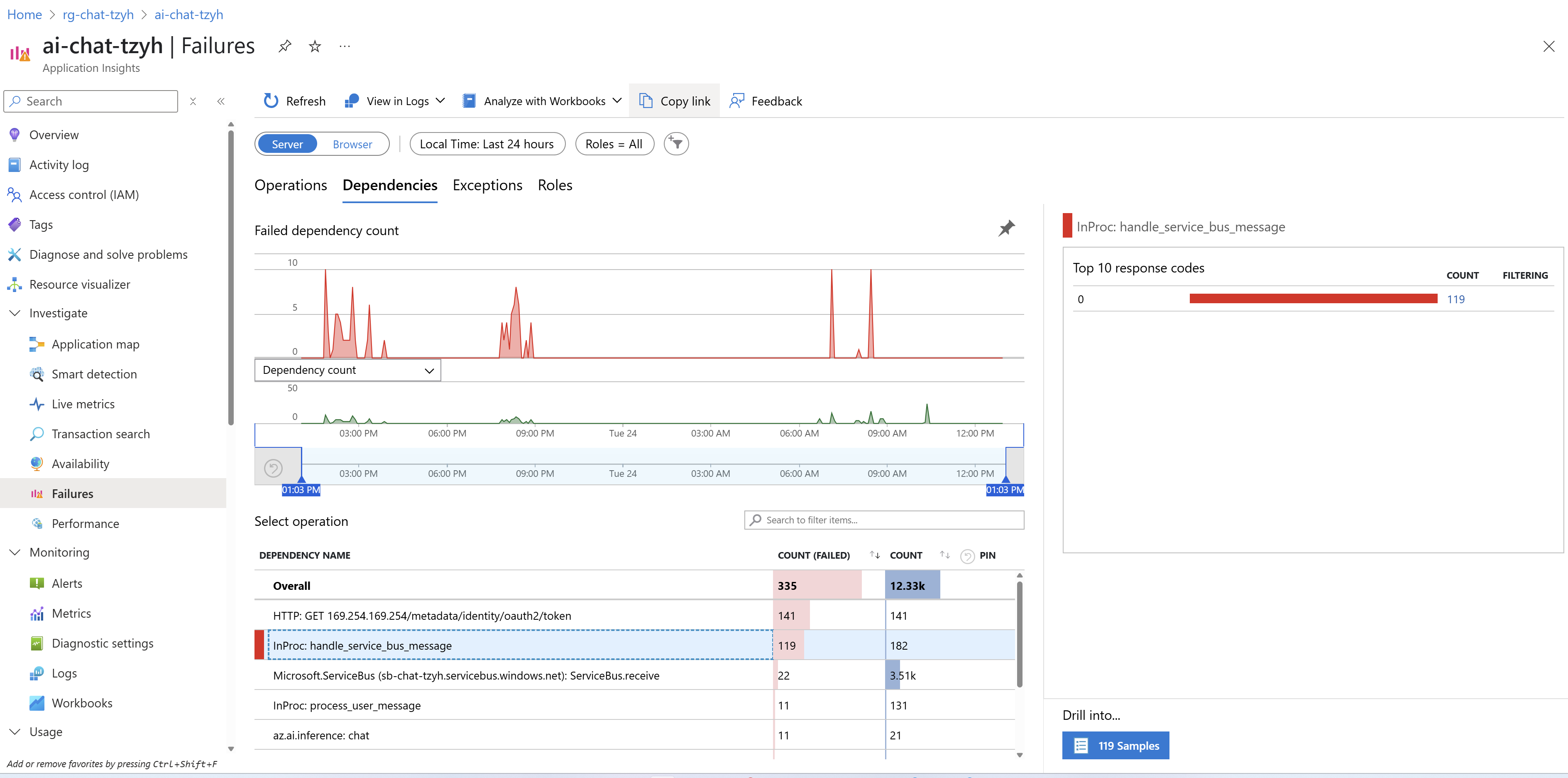
Existuje i pohled zaměřený na chyby, například selhávající volání.
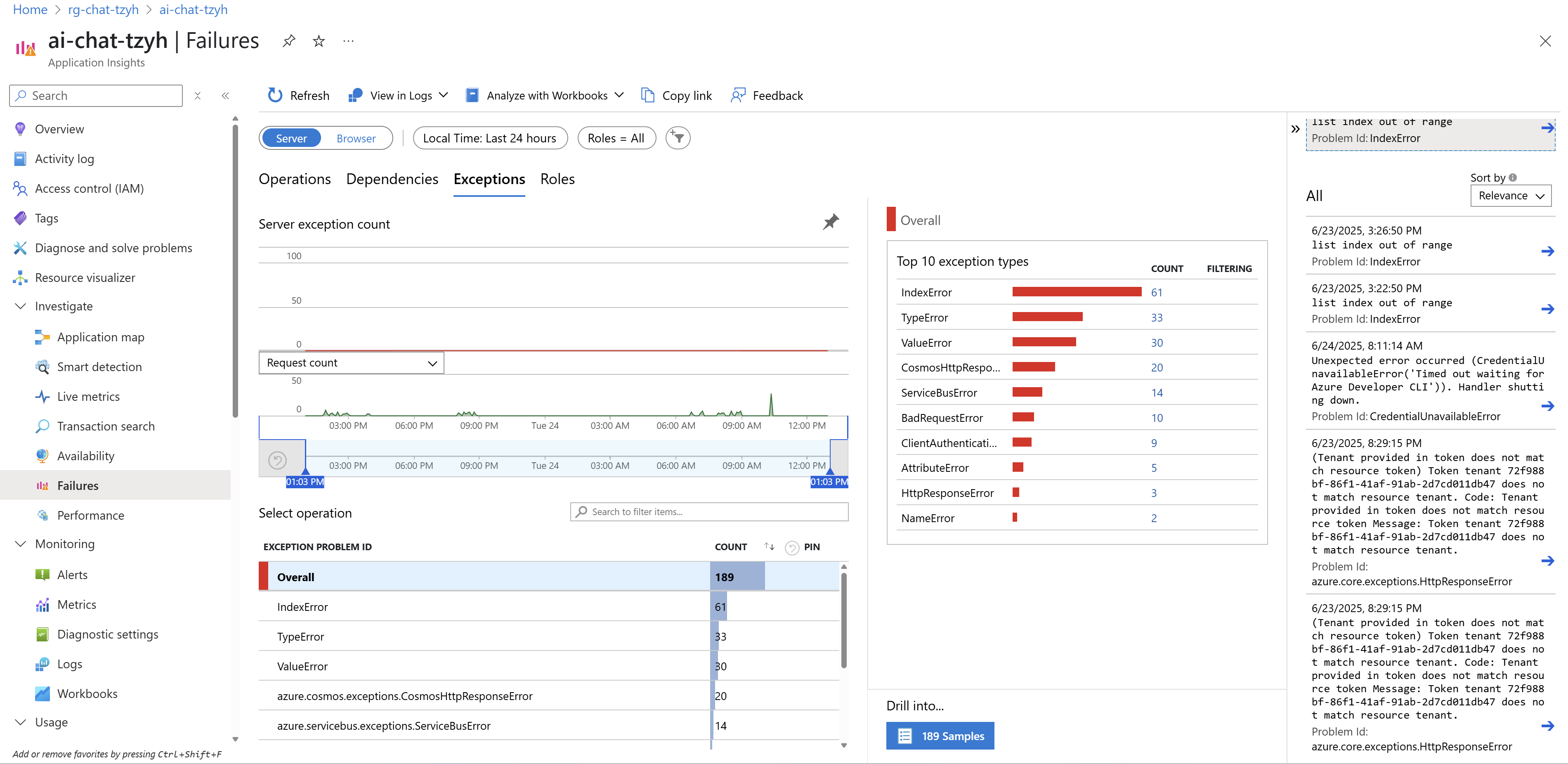
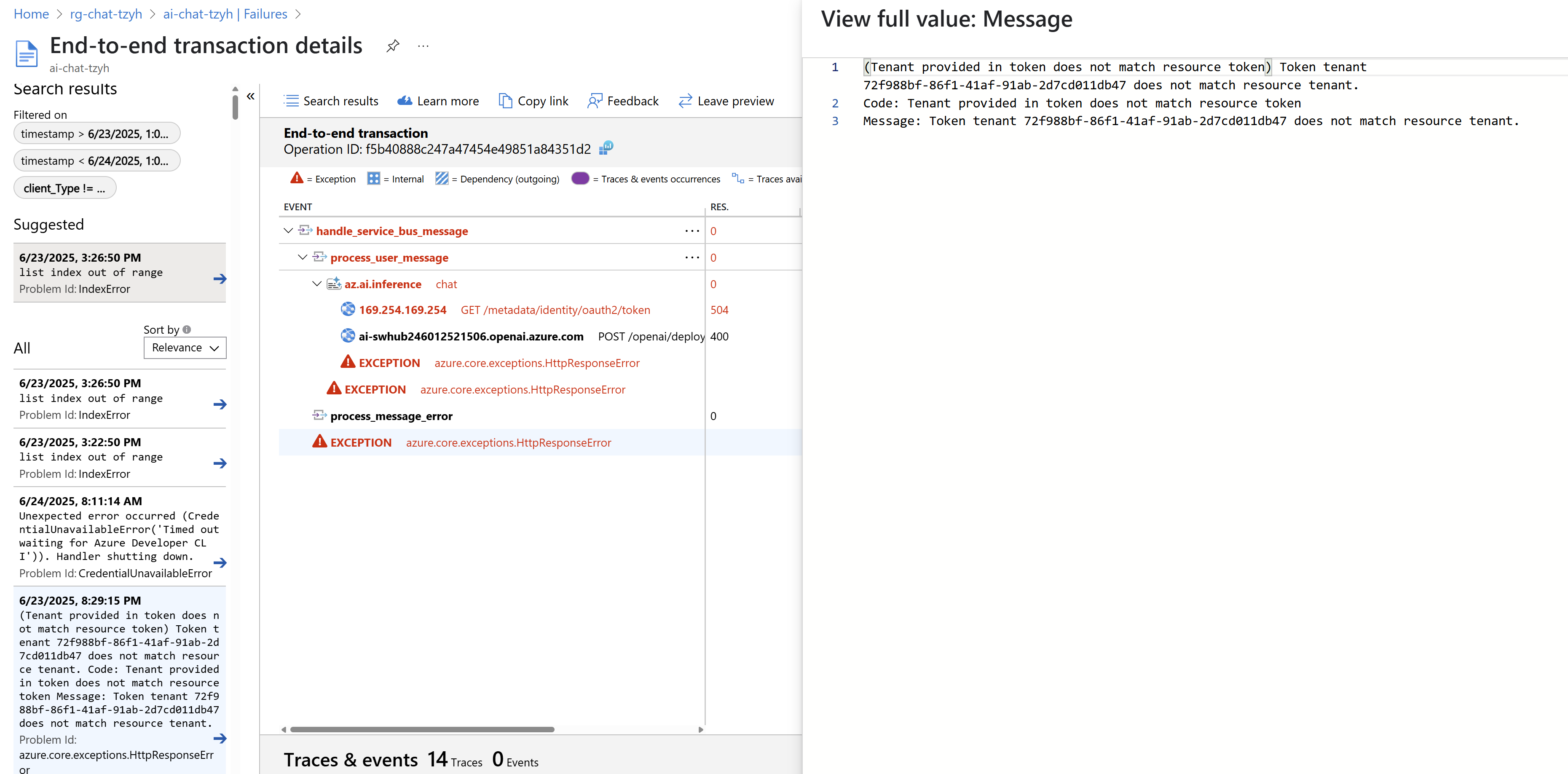
Takhle pak vypadají aplikační výjimky a to včetně detailů co jim předcházelo.
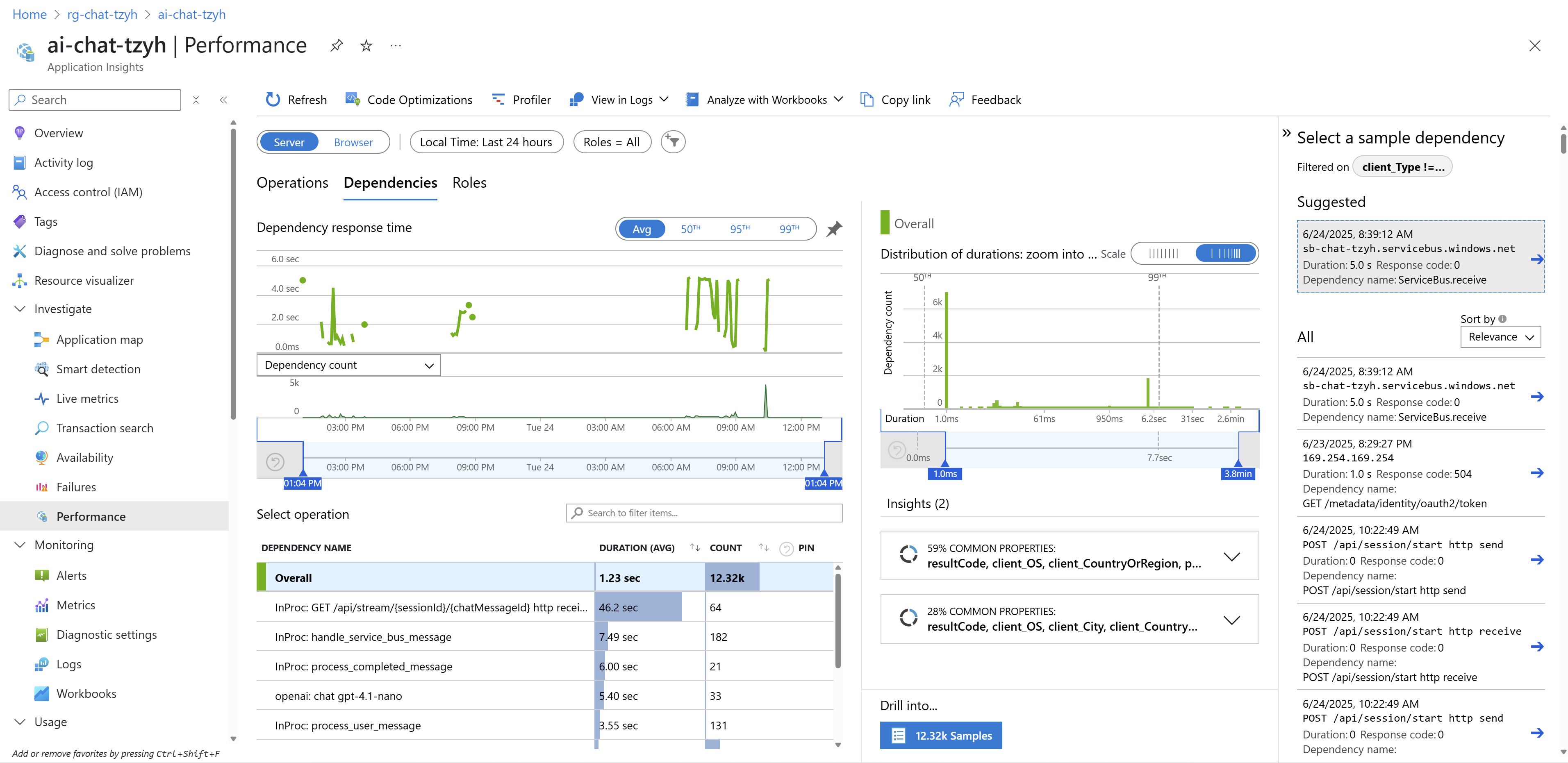
Jiný pohled nabízí přehled o výkonu a zdraví aplikace.
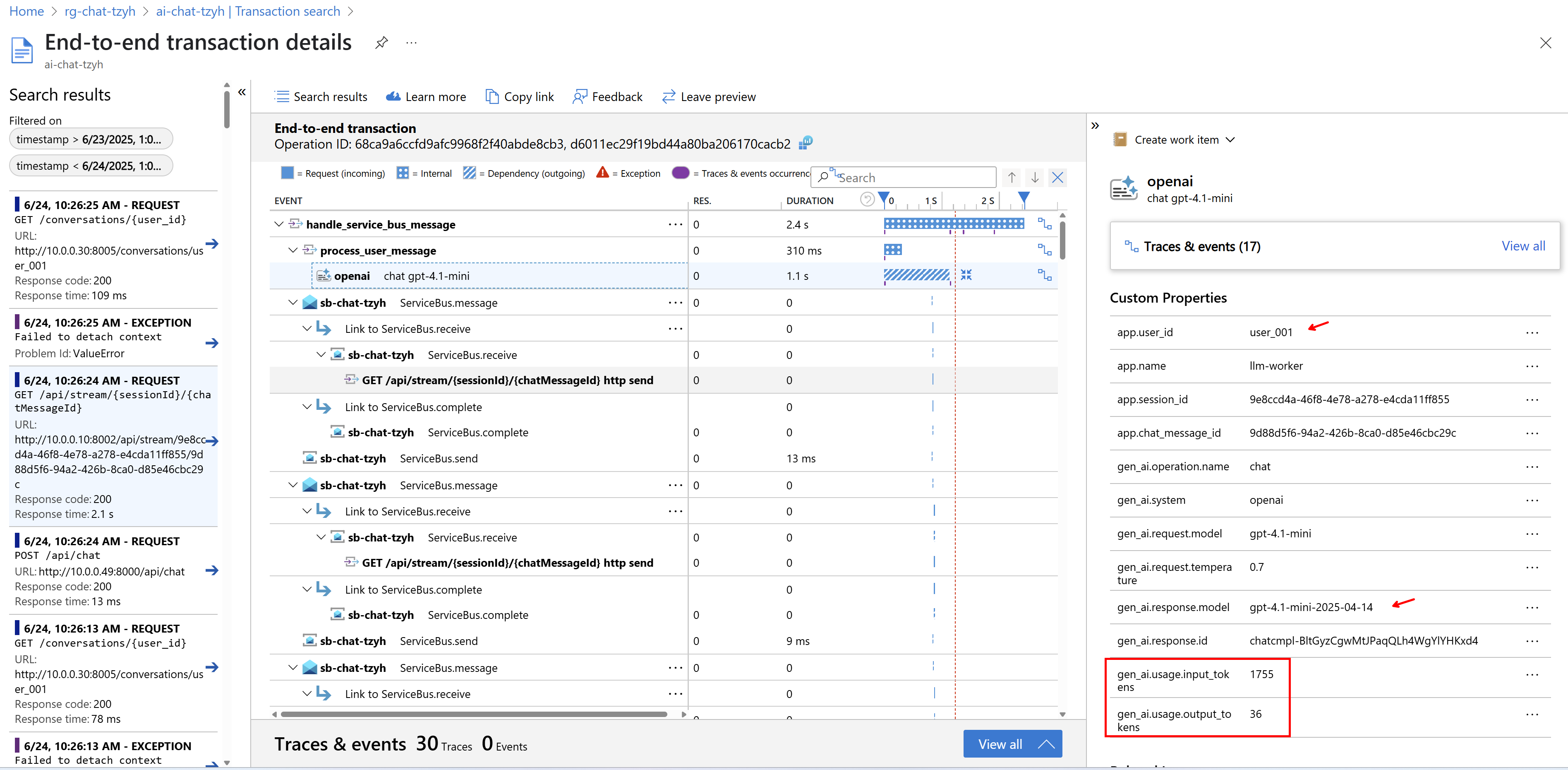
Jednotlivé trasování pak lze zkoumat podrobněji a můžeme si opět všimnout, že námi přidané dimenze tam jsou.
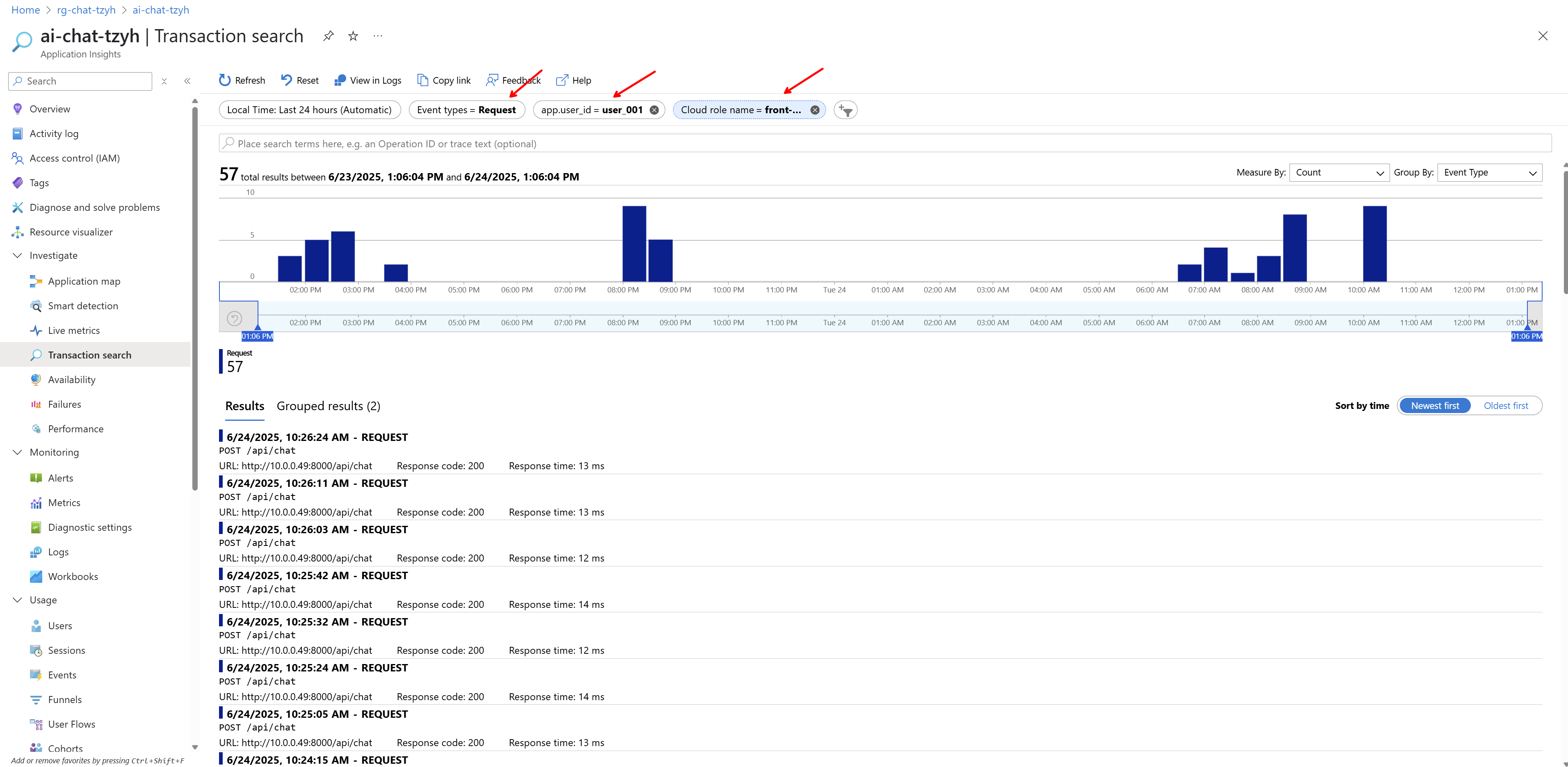
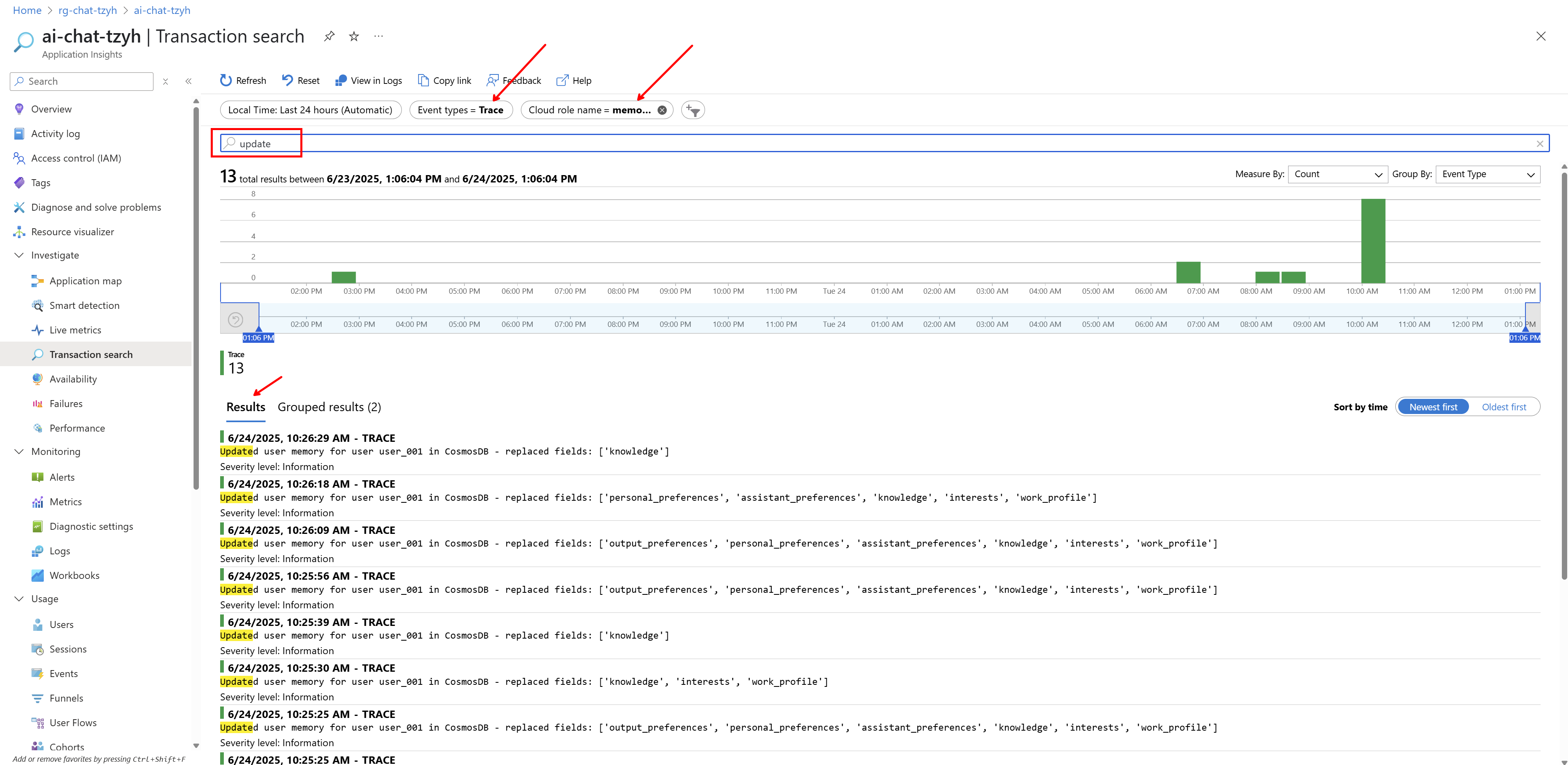
Podle nich můžeme třeba filtrovat, takže takhle si vyjedu API requesty pro konkrétního uživatele na komponentě front-service.
V terminologii Application Insights (možná trochu nešťastně, ale jsou k tomu historické důvody) jsou aplikační logy označované jako trace (Open Telemetry o nich mluví buď jako o Log nebo pokud je to exception v rámci spanu, tak tomu říkají Event). Nastavím filtr na logy, vyberu konkrétní aplikační komponentu a ještě můžu použít full-text search.
Závěr
Na mém GitHubu najdete konkrétní kód pro všechny služby a přes Terraform také kompletní nasazení do Azure včetně právě monitoringu. Technologicky je to postavené na Open Telemetry a sběru v Azure, kde se dá použít AI Foundry na příjemné vizualizace pro lidi od umělé inteligence, vlastní query v Log Analytics pro budování analýz, reportů, Workbooků a Grafa Dashboardů nebo ML analýzy typu předpovídání či detekce anomálií a do třetice Application Insights rozhraní určené pro aplikační a systémový pohled na sesbíraná data.
Co bych chtěl v této sérii řešit?
- Základní architektura s asynchronním zpracováním a streamováním
- Paměť konverzací a dlouhodobá paměť ve jménu uživatele
- Observabilita a monitoring
- Autentizace a autorizace uživatelů
- Popis praktického postupu s GitHub Copilotem (od architektury ke kódu a ne naopak)
- Perf testy
- Chaos engineering
- CI/CD pipeline
- A/B testing a progressive delivery
- Multi-region active/active deployment