Máte rádi Prometheus a Grafana pro váš Kubernetes? Jak na to všechno v plně managed formě v Azure?
Velké množství týmů přicházejících ze světa “tady si už rok hrajeme s Kubernetem” do “tak a teď to pojede produkčně v cloudu” si se sebou nese zkušenosti se sběrem telemetrie přes Prometheus a vizualizace v Grafaně. Když ale mají převzít odpovědnost za správu, vysokou dostupnost a bezpečnost takového řešení v produkci, začnou se obvykle cukat. Znamená to tedy všechno zahodit a jít do zabudovaného řešení v cloudu ala Azure Monitor nebo do placeného řešení typu Datadog? Ukažme si dnes jinou cestu - jak funguje managed Grafana a Prometheus přímo od Azure pro vaší Azure Kubernetes Service případně jiné systémy využívající těchto technologií.
Všechny dnešní ukázky najdete na mém GitHubu: https://github.com/tkubica12/azure-workshops/tree/main/d-managed-prometheus
Osoby a obsazení - hlavní aktéři a jejich srovnání
Pojďme se nejprve podívat co je Azure Monitor, co Prometheus a co Grafana.
Azure Monitor
První si připomeňme nativní monitorovací systém v Azure, který je za mě nádherně integrovaný a splňuje všechna zásadní kritéria na bezpečnost, certifikace, autentizaci, šifrování dat a vysokou dostupnost. Přímo pro věci v kontejnerech má krásnou vazbu na AKS s plně integrovaným GUI včetně dashboardů, workbooků, alertů včetně pokročilých automatizovaných reakcí nebo detekcí anomálií. No a mimochodem (ale ať se vám to pak neplete) - Azure Monitor umí sbírat metriky z vašich aplikací, když je vystavují ve formátu Prometheus. Co do standardizace vystavování telemetrie z aplikací s tím Azure Monitor nativně počítá už pár let.
To zní naprosto ideálně, ne? Určitě je to skvělé, ale nic není černobílé a tady jsou situace, kdy můžete váhat:
- Azure Monitor cenově neodpouští přehnané využití - zvládne cokoli, ale to cokoli musíte zaplatit. Platíte tam kvalitu pekelně chytré analytické platformy a když ji zaplníte velkým množstvím nepotřebných dat, nemusí to být levné.
- Azure Monitor je Azure Monitor, takže něco, co vzniklo v Microsoftu na zpracování masivního množství dat. Má to svůj vlastní jazyk Kusto, ne PromQL, které můžete znát. Na vizualizace má vlastní řešení s workbooky, ne Grafana dashboardy, které můžete znát.
- Je to otázka vkusu a cviku, ale pro většinu lidí je Grafana a PromQL rychlejší na naučení. Nedokážete s tím tolik analytických kouzel, ale na operační monitoring to možná ani nepotřebujete.
Prometheus
Tady se často plete, že jde vlastně o dvě věci - způsob jak může aplikace vystavovat metriky a taky backend na jejich zpracování a uložení. Začněme u aplikace. Pro sběr telemetrie máte v zásadě dva principy na výběr - push a pull.
- Push má určitě výhody, protože aplikace to dokáže natlačit vlastně kamkoli a může běžet doslova kdekoli - stačí konektivita. Může to být SPA aplikace v prohlížeči (tam jste s pull totálně namydlení), kontejner v Kubernetu, virtuálka v legacy prostředí, IoT zařízení typu Raspberry někde v domácnosti, v platebním automatu nebo výdejním boxu - cokoli. Na druhou stranu formát exportu byl obvykle proprietární - dáte si do aplikace SDK Azure Monitoru (App Insights) a funguje to jen s tím. To se v poslední době mění díky standardizaci Open Telemetry. Nicméně buď jak buď musím aplikaci doručit nějakou konfiguraci a tajnosti - kam to posílat, jak se ověřit a udělat to bezpečně dá trochu práce. Ale ještě jedna výhoda - když bude příjemce po nějakou dobu nefunkční, můžu si to držet u sebe a pak to doposlat. Pro scénáře s častým odpojováním (třeba systém ve vlaku) je to lepší.
- Pull model je zajímavý tím, že to aplikace v podstatě vystaví jako webovou stránku a o nic jiného se nezajímá. Nepotřebuje mít konfiguraci typu kam to mám posílat, jak se proti tomu autentizovat a tak podobně. Tím je to strašně jednoduché a něco jiného mě bude očuchávat a číst si data. Klidně si to může číst víc sběračů najednou a já v aplikaci nemusím nic řešit. Nevýhody to ale logicky taky má. Spoléhám na svoje okolí, že to čte (předpoklad celkem rozumný někde v Kubernetu, ale už méně v IoT, mašině ve výrobě nebo v legacy DC). Když si to nikdo číst nebude, tak smůla - o telemetrii přijdu (proto se to pull metody obvykle snaží dělat přírůstkově - jsou to nekonečné čitače, takže když si to čtu méně často, pořád jsem schopen s nějakou přesností rate ukazatele vypočítat - tím se problém občasného výpadku snižuje, nicméně určitě přicházím o přesnost, což u doposlaného push nenastává).
Prometheus má knihovny do různých jazyků, takže instrumentace aplikace (zajištění vystavení metrik) je snadná. Na mém GitHubu je ukázka a kód v Python je triviální - definuje svoje vlastní měřáky a když v kódu potřebuji (uzavřená objednávka apod.), zvýším (v mém případě pro ukázku jen náhodně).
1
2
3
4
5
6
7
8
9
10
from prometheus_client import start_http_server, Counter
import random
import time
if __name__ == '__main__':
c = Counter('my_failures', 'Description of counter')
start_http_server(8000)
while True:
c.inc(random.randrange(1,20,1))
time.sleep(random.randrange(1,5,1))
Je tu ale ještě ta serverová strana a tam Prometheus přichází s celým systémem pro sběr, uložení a dotazování dat. Jazyk PromQL je jednoduchý a velmi vhodný na klasické pull countery, tedy ty trvale rostoucí. Ať to později je zřejmé - jedna věc je implementační detail (způsob uložení a tak podobně) a jiná dotazovací jazyk PromQL.
Grafana
Králem vizualizací pro obchodní data je určitě PowerBI nebo Tableau umožňující velmi sofistikované reporty pro pochopení dat. V IT světě ale často chceme obyčejný čárový graf s počtem requestů s možností to zoomovat nebo filtrovat a to je pro většinu situací všechno. Grafana se stala velmi oblíbeným nástrojem pro vizualizaci takových metrik - vypadá skvěle, UI je svižné a intuitivní, vytváření dashboardů rychlé a snadné (Azure Monitor workbook je určitě mocnější co do provázanosti komponent pro analytickou práci, ale je to občas moc složité na běžné úkony).
Podobně jako u Promethea nabízí firma Grafana Labs i nějaké vlastní open source backend implementace, ale jsou od produktu oddělené - konkrétně Graphite (time-series databáze na metriky), Mimir (dlouhodobé úložiště pro Prometheus) nebo Loki (na logy - ale o tom jindy).
Managed řešení v Azure pro Grafanu a Prometheus
Začněme s Grafanou - to je služba v Azure Managed Grafana, která je vytvářena přímo ve spolupráci s Grafana Labs, tedy hlavní firmou stojící za projektem. Máte tedy instanci Grafany (ale ne Graphite, Mimir nebo Loki) přímo od těch nejpovolanějších na Grafanu samotnou a provozovanou těmi nejpovolanějšími na Azure (tedy přímo Azure lidmi). Tohle je skvělý model spolupráce, který najdete třeba i u Redisu, Databricks, NetApp a dalších. Je to plnohodnotná Grafana s enterprise funkcemi typu Azure Active Directory login, certifikace, bezpečnost, šifrování, automatické aktualizace, vysoké SLA a tak podobně. Nicméně tím, že za to má Microsoft odpovědnost, nemůžete si do prostředí nainstalovat libovolné pluginy, ale jen určitý výčet (na roadmapě je zpřístupnění širšího katalogu Grafana Labs). To je logické - plugin = cizí kód. Těžko garantovat bezpečnost a dostupnost služby, ve které neběží jen kód, který máte nějak pod kontrolou.
Azure Monitor for Prometheus má podezřele jiný název a je to schválně - na rozdíl od Grafana tam nějaký single-tenant Prometheus neběží. Jde o nativní Azure službu, konkrétně nový Azure Monitor workspace (nové řešení pro metriky, pozor, není to Log Analytics workspace, který už znáte), která ale podporuje Prometheus těmito způsoby:
- Jsou k dispozici agenti schopní sbírat metriky v Prometheus formátu. Něco podobného už bylo pro Azure Monitor k dispozici dříve, ale tam to posílalo data do Log Analytics (což není na metriky ani levné ani pohodlné), ale tady se posílají do Azure Monitor workspace.
- Azure Monitor workspace má Prometheus endpoint pro vzdálené posílání telemetrie - tedy remote-write funkcionalitu. Díky tomu můžete mít svůj vlastní Prometheus server, tím lokálně něco sbírat a výsledky přeposílat do Azure Monitor for Prometheus. To je příjemná novinka.
- Ale to nejlepší na konec - funguje to i z druhé strany, tedy Azure Monitor má Prometheus endpoint na aplikaci PromQL jazyka. To je za mě nejzásadnější novinka umožňující použít Azure Monitor workspace jako vysoce dostupný bezpečný backend, ale nad tím jet PromQL jak jsem zvyklí a konzumovat to třeba s Grafany nebo čehokoli takového.
Z toho je patrné, že tyhle dvě věci půjdou skvěle dohromady.
- Použiji Grafanu a v ní mohu vizualizovat celou telemetrii z Azure platformních služeb, AKS clusterů a vlastních aplikací.
- Použiji připravené agenty na sběr přímo v Kubernetes clusteru, takže nepotřebuji vůbec žádný Prometheus server - plně ho nahradím Azure Monitor for Prometheus.
- Možná chci z nějakého důvodu držet svůj vlastní Prometheus v kontejneru uvnitř clusteru (třeba pro lokální sběr vysoce granulární telemetrie pro autoškálování nebo jednotnost napříč dev a prod clustery), ale pro produkci potřebuji telemetrii mít vyřešenou co do trvalosti, SLA, bezpečnosti a hlavně mimo cluster (nechci při problémech clusteru nemít monitoring). Použiji vlastní Prometheus, ale nastavím remote-write na Azure Monitor for Prometheus a mám to oboje současně.
Vyzkoušejme
Na mém už zmíněném GitHubu najdete Terraform šablonu, která vám to všechno nasadí. Některé funkce jsou samozřejmě v preview a proto je azurerm nepodporuje, takže tam budou některé zdroje vytvářené přes AzApi. Takhle tam mám Grafanu a Azure Monitor workspace.

Workspace a Grafana jsou prolinkované, takže se rovnou pěkně a bezpečně vidí.

Udělal jsem dva clustery - jeden, který využije plně managed variantu, tedy bude mít agenty co Prometheus metriky sbírají přímo do Azure Monitor for Prometheus. Druhý bude mít vlastního Promethea s remote-write do Azure Monitor for Prometheus.
Managed řešení pro Prometheus
Po integrace se do clusteru natlačil potřebný agent se sběračem z nodů a z metrik.

V managed Grafana jsou rovnou připraveny některé dashboardy jak pro platformní služby Azure tak pro Kubernetes.

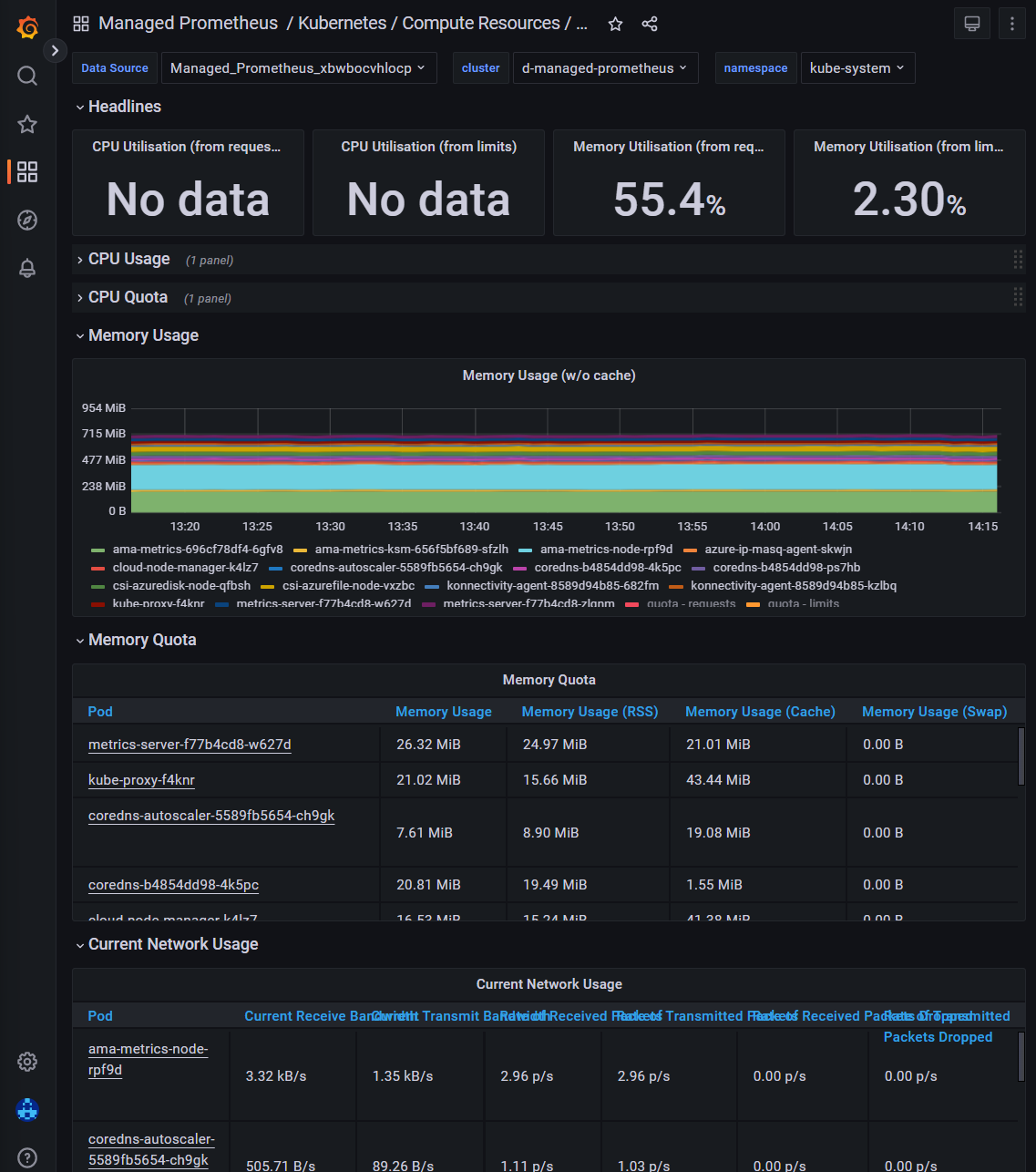

Je to vždy otázka vkusu, ale já mám Grafanu moc rád.
Chtěl jsem, aby agenti posbírali i moje vlastní metriky z mé aplikace. Jsem zvyklí to řešit tak, že si přímo na podu anotacemi říkám, jestli z něj chci telemetrii sbírat a na kterém portu a URL se dají metriky najít. Takové nastavení jsem potřeboval zapnout a to se dělá přes ConfigMap - můžete tedy svoje řešení velmi přesně upravovat a řídit co a jak se má sbírat, o jaká data to obohacovat (chci například u každé metriky z podu i všechny jeho labely nebo ne?) a tak podobně.
Já jsem nic moc nevymýšlel, tohle je copy and paste z dokumentace.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
kind: ConfigMap
apiVersion: v1
data:
prometheus-config: |-
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
# Scrape only pods with the annotation: prometheus.io/scrape = true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
# If prometheus.io/path is specified, scrape this path instead of /metrics
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
# If prometheus.io/port is specified, scrape this port instead of the default
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
# If prometheus.io/scheme is specified, scrape with this scheme instead of http
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scheme]
action: replace
regex: (http|https)
target_label: __scheme__
# Include the pod namespace as a label for each metric
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
# Include the pod name as a label for each metric
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
# [Optional] Include all pod labels as labels for each metric
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
metadata:
name: ama-metrics-prometheus-config
namespace: kube-system
Svůj Pod jsem nahodil takhle.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-counter
namespace: default
spec:
selector:
matchLabels:
app: prometheus-counter
template:
metadata:
labels:
app: prometheus-counter
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "8000"
prometheus.io/scheme: http
prometheus.io/path: /
spec:
containers:
- name: prometheus-counter
image: ghcr.io/tkubica12/prometheus-counter:latest
ports:
- containerPort: 8000
No a to je celé. Moje vlastní metrika my_failures se posbírala a krásně si ji v Grafaně zobrazím včetně přepočtu na rate.

Remote write
Vyzkoušel jsem i druhou variantu - malý skutečný Prometheus uvnitř clusteru a jeho napojení na centrální “profi” backend pro produkční sběr. Představte si například, že máte celé svoje aplikační řešení zabalené do šablon, takže dokážete kdykoli rozjet tohle celé včetně monitoringu (a to zahrnuje i monitoring nutný při provozu, třeba pro autoškálování workloadu s KEDA) na jakémkoli clusteru - v cloudu i na pecku v pobočce nebo na svém notebooku, v devu, testu i produkci. Jako tým se nechcete integrovat na jinou instanci - i kdyby to byla Grafana a Prometheus vašich kolegů z platformního týmu. Řešením může být udělat oboje - nahoďte si co potřebujete jak jste zvyklí, ale pro produkční věci se ještě k tomu napojte na Azure Monitor for Prometheus. Možná tam nepotřebujete úplně všechno nebo třeba v menší granularitě, ale získáte enterprise-grade plně spravovaný systém a všichni jsou spokojeni - jak vývojáři co mají svobodu si u sebe upravit cokoli pro řešení aktuálních problémů, tak lidé odpovědní za dohled a provoz ucelených systémů a ekosystémů.
V jiném clusteru jsem tedy nahodil Prometheus a přes Helm values file mu předal pár věcí navíc.
1
2
3
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm upgrade -i -f values.yaml prometheus prometheus-community/kube-prometheus-stack
Takhle vypadá YAML file. Všimněte si zejména, že tam přidáváme další kontejner do Podu - sidecar, která bude Prometheu zprostředkovávat remote-write. Musel jsem tam vyplnit client id (běží to v Azure, takže použiji managed identitu - já jsem pro jednoduchost zvolil tu Kubeletu, takže jsem jí v Azure dal práva Monitoring Metrics Publisher na příslušnou Data Collection Rule - viz Terraform kód). Pokud cluster není v Azure, nevadí, použijete AAD login. Další důležitá věc je externalLabels.cluster kde specifikuji jméno clusteru (label). Jinak mi to nevyplňovalo a výchozí dashboardy pak nefungovaly.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
prometheus:
prometheusSpec:
externalLabels:
cluster: d-prometheus-remotewrite
## https://prometheus.io/docs/prometheus/latest/configuration/configuration/#remote_write
remoteWrite:
- url: 'http://localhost:8081/api/v1/write'
containers:
- name: prom-remotewrite
image: mcr.microsoft.com/azuremonitor/prometheus/promdev/prom-remotewrite:prom-remotewrite-20221102.1
imagePullPolicy: Always
ports:
- name: rw-port
containerPort: 8081
livenessProbe:
httpGet:
path: /health
port: rw-port
# initialDelaySeconds: 10
# timeoutSeconds: 10
readinessProbe:
httpGet:
path: /ready
port: rw-port
# initialDelaySeconds: 10
# timeoutSeconds: 10
env:
- name: INGESTION_URL
value: https://xbwbocvhlocp-yjk4.westeurope-1.metrics.ingest.monitor.azure.com/dataCollectionRules/dcr-2f72a4ca18854a9a82efd75fe9ac663d/streams/Microsoft-PrometheusMetrics/api/v1/write?api-version=2021-11-01-preview # Get this value from your Azure Metrics workspace
- name: LISTENING_PORT
value: '8081'
- name: IDENTITY_TYPE
value: userAssigned
- name: AZURE_CLIENT_ID
value: 03492ae1-5dc3-4497-b760-01dd06eee7cb # Client ID, Kubelet identity in my case
- name: CLUSTER
value: d-prometheus-remotewrite
grafana:
enabled: false
No a to je všechno - podívám se do své Azure Managed Grafana a vidím další cluster.

Vyzkoušejte si sami - všechno mám na https://github.com/tkubica12/azure-workshops/tree/main/d-managed-prometheus
Tolik tedy k použití Grafana a Prometheus tak, že se vám o ně stará přímo Azure pěkně enterprise-grade způsobem a vy se na tyto služby napojíte z AKS nebo jiného Kubernetes clusteru nebo ve finále čehokoli (ani jedno není čistě pro kontejnery - můžete tam dát svoje aplikace ve VM nebo sledovat metriky z platformních služeb Azure). Azure Monitor a jeho řešení pro kontejnery je nativní a velmi mocné a já ho doporučuji zapnout (Container Insights). Jestli ale máte rádi kombinaci Prometheus a Grafana a chcete si přinést všechny svoje dosavadní znalosti, query a dashboardy, určitě do toho pojďme. Oboje je skvělé.