Vaše vlastní AI chatbot aréna včetně monitoringu s OpenTelemetry, AI Foundry, Gradio a Azure Container Apps nahozená přes Terraform
Potřeboval jsem pro svoje účely vyrobit jednoduché demo, kde bych ukázal nasazení jednoduché aplikace sloužící pro rychlé interaktivní porovnání dvou modelů mezi sebou, například z rodiny Phi open source modelů s high-end řešeními od OpenAI a zajistit monitoring a logování. Řešení mělo splňovat následující požadavky:
- Kompletně automatizované nasazení infrastruktury a aplikace přes Terraform do Azure (AI služby, modely, aplikační platforma, monitoring).
- Využití nového AI Foundry API a SDK, které přináší jednotnější způsob práce s jazykovými modely v Azure na serverless endpointech včetně OpenAI nebo open source modelů.
- Vyzkoušet standardizovaný monitoring a tracing volání modelů (logování chatů, spotřeba tokenů apod.) přes OpenTelemetry s backendem v Azure Application Insights případě vizualizací v AI Foundry.
- Demonstrovat nasazení kontejnerizované aplikace do serverless řešení v Azure Container Apps.
- Trochu si vyzkoušet Gradio pro tvorbu AI prototypů tentokrát s něčím o chlup složitejším, než jen chat v jediném okně a použít dvě okna, každé s jiným modelem a streamované odpovědi.
To by mělo jednak ukázat tohle všechno ale hlavně umožnit si pěkně pohrát s modely. Pro jakou práci je Phi použitelné, která varianta je lepší a jak moc je srovnatelná s OpenAI? Vystačí na můj scénář gpt-4o-mini (mnohem levnější a rychlejší) nebo potřebuji gpt-4o? A když chci třeba dělat jednoduché sumarizace textu v češtině, kde asi stačí gpt-4o-mini, nedalo by se nahradit open source modelem jako je Phi?
Celé řešení najdete samozřejmě na mém GitHubu
Výsledek - chatovací aréna
Takhle vypadá výsledek. Pro levou a pravou stranu si vyberu nějaký z mnou nasazených modelů (já použil Phi 3.5 mini a větší MoE a dále OpenAI gpt-3.5-turbo, gpt-4o a gpt-4o-mini) a pak už můžu chatovat s oběma současně a porovnat výsledky a rychlost.
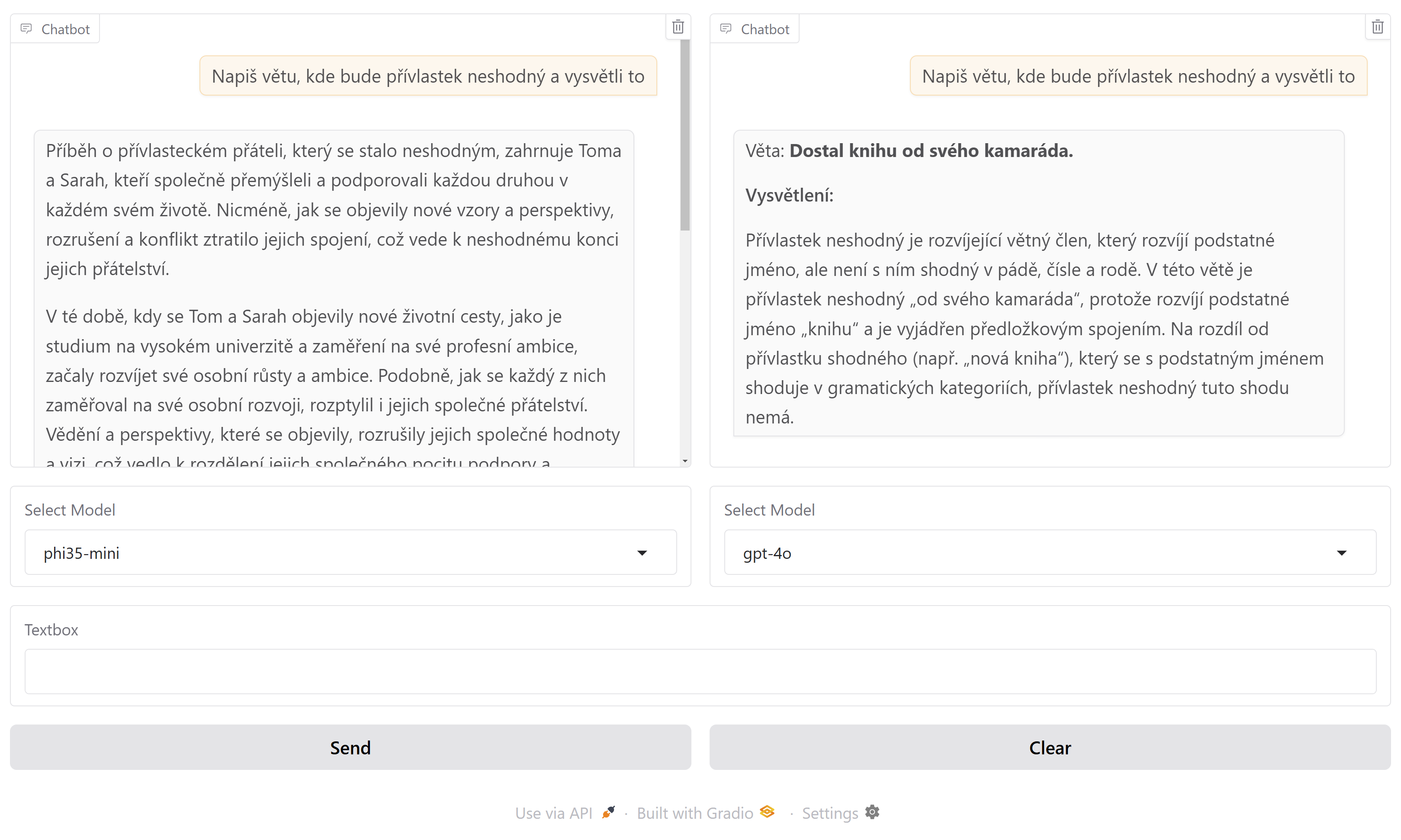
Gradio má i tmavý režim a možnosti grafického doladění nejsou vůbec špatné - na takovéhle prototypování jsem s tím velmi spokojen.
Aplikace - AI Foundry SDK a Gradio pro jednoduché webové rozhraní
Azure AI Foundry postupně sjednocuje způsob využívání jazykového modelu z aplikace a přestože to ještě není plně hotové, je to za mě krok správným směrem. Modely totiž mohou být od OpenAI (ty mají specifické SDK a API a různé režimy nasazení od platby za tokeny v jednom DC přes platbu za tokeny globálně až po provisionovaný výkon), mohou to být stovky či tisíce open source modelů nasazených v managed compute (Azure pro vás vytočí virtuálku s GPU a spravuje ji, takže máte super výkon a rychlou odezvu, ale trvalou relativně vysokou spotřebu) nebo tzv. serverless API, kde platíte za tokeny a funguje třeba pro Phi, Llama nebo Mistral. V AI Foundry to pak vypadá nějak takhle:
Tady je relevantní část kódu s AI Foundry SDK. Já si vytvářím několik klientů na základě konfiguračního souboru, protože budeme mít možnost používat různé modely. Každopádně stačí udělat instanci ChatCompletionsClient a předat mu endpoint a klíč, případně použít Managed Identity. Pak už jen klasicky naládovat historii zpráv do pole s rolí a obsahem, v rámci payloadu přidat další parametry jako je třeba teplota a zavolat. Klient podporuje streaming, což mám zapnuté, takže SDK servíruje nové tokeny postupně tak jak mu z API přicházejí, takže přes yield můžu postupně posílat text zpět do Gradia na vykreslování. Tenhle kód je díky AI Foundry SDK stejný pro OpenAI i Phi a další modely dostupné tímto způsobem.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
clients = {}
for model_name, model_attrs in config.get("models", {}).items():
api_endpoint = model_attrs.get("endpoint")
api_key = model_attrs.get("key")
if api_endpoint and api_key:
clients[model_name] = ChatCompletionsClient(
endpoint=api_endpoint,
credential=AzureKeyCredential(api_key)
)
system_message = SystemMessage(content="You are a helpful assistant.")
def bot_l(history, model_name):
print(f"Model: {model_name}, History: {history}")
messages = [system_message]
for msg in history:
if msg["role"] == "user":
messages.append(UserMessage(content=msg["content"]))
elif msg["role"] == "assistant":
messages.append(AssistantMessage(content=msg["content"]))
payload = {
"messages": messages,
"max_tokens": 2048,
"temperature": 0.8,
"top_p": 0.1,
"presence_penalty": 0,
"frequency_penalty": 0
}
client = clients.get(model_name)
if not client:
raise Exception(f"Client for model {model_name} not found")
response = client.complete(stream=True, **payload)
assistant_message = {"role": "assistant", "content": ""}
for update in response:
assistant_message["content"] += update.choices[0].delta.content or ""
yield history + [assistant_message]
Grafické webové rozhraní pro mě zajišťuje Gradio. Lidé volí často buď to nebo Streamlit. Já používám podle situace oboje - Streamlit má větší možnosti vizualizace klasických dat do různých grafů, takže prototypování aplikací co zobrazují něco takového preferuji v něm. Ale pro chat s AI nebo podobné interaktivní scénáře přestože Streamlit zvládne taky, tak Gradio je ještě jednodušší a mám ho na to raději.
Na základní aplikaci vystačí vlastně jeden řádek s tím, že bude volat mou funkci zmíněnou výše. Nicméně já jsem to potřeboval jinak - mít vybíračku modelů, dvě okna, ale společná tlačítka odesílající do obojího a mít streamování odpovědí “zaživa” do obou oken. Ve finále se to ukázalo jako velmi jednoduché!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
with gr.Blocks() as demo:
# Main layout with two columns for left and right chat windows.
with gr.Row():
with gr.Column():
chatbot_l = gr.Chatbot(type="messages")
model_selector_l = gr.Dropdown(choices=model_names, label="Select Model")
with gr.Column():
chatbot_r = gr.Chatbot(type="messages")
model_selector_r = gr.Dropdown(choices=model_names, label="Select Model")
msg = gr.Textbox()
# The textbox where users type their message.
with gr.Row():
send = gr.Button("Send")
clear = gr.ClearButton([msg, chatbot_l, chatbot_r])
# Clicking Clear resets all chat windows and the message box.
# 'user' function appends the user's message to the chat history.
def user(user_message, history):
# Return the new empty message box and updated history containing the user message.
return "", history + [{"role": "user", "content": user_message}]
# 'bot_l' function streams responses for the left chat interface.
def bot_l(history, model_name):
print(f"Model: {model_name}, History: {history}")
messages = [system_message]
for msg in history:
if msg["role"] == "user":
messages.append(UserMessage(content=msg["content"]))
elif msg["role"] == "assistant":
messages.append(AssistantMessage(content=msg["content"]))
payload = {
"messages": messages,
"max_tokens": 2048,
"temperature": 0.8,
"top_p": 0.1,
"presence_penalty": 0,
"frequency_penalty": 0
}
client = clients.get(model_name)
if not client:
raise Exception(f"Client for model {model_name} not found")
response = client.complete(stream=True, **payload)
assistant_message = {"role": "assistant", "content": ""}
for update in response:
assistant_message["content"] += update.choices[0].delta.content or ""
yield history + [assistant_message]
# 'bot_r' function streams responses for the right chat interface.
def bot_r(history, model_name):
print(f"Model: {model_name}, History: {history}")
messages = [system_message]
for msg in history:
if msg["role"] == "user":
messages.append(UserMessage(content=msg["content"]))
elif msg["role"] == "assistant":
messages.append(AssistantMessage(content=msg["content"]))
payload = {
"messages": messages,
"max_tokens": 2048,
"temperature": 0.8,
"top_p": 0.1,
"presence_penalty": 0,
"frequency_penalty": 0
}
client = clients.get(model_name)
if not client:
raise Exception(f"Client for model {model_name} not found")
response = client.complete(stream=True, **payload)
assistant_message = {"role": "assistant", "content": ""}
for update in response:
assistant_message["content"] += update.choices[0].delta.content or ""
yield history + [assistant_message]
# The Gradio workflow:
# 1. User enters message -> triggers 'user' -> updates chat history
# 2. Then calls 'bot_l' or 'bot_r' to generate model responses
msg.submit(user, [msg, chatbot_l], [msg, chatbot_l], queue=False).then(
bot_l, [chatbot_l, model_selector_l], [chatbot_l]
)
msg.submit(user, [msg, chatbot_r], [msg, chatbot_r], queue=False).then(
bot_r, [chatbot_r, model_selector_r], [chatbot_r]
)
send.click(user, [msg, chatbot_l], [msg, chatbot_l], queue=False).then(
bot_l, [chatbot_l, model_selector_l], [chatbot_l]
)
send.click(user, [msg, chatbot_r], [msg, chatbot_r], queue=False).then(
bot_r, [chatbot_r, model_selector_r], [chatbot_r]
)
clear.click(lambda: [None, None], None, [chatbot_l, chatbot_r], queue=False)
demo.launch(server_name='0.0.0.0', ssr_mode=True) # ssr accelerates page load time, but requires Node to be installed on server - you can disable for local development
Jasně - funkce volající AI má pár řádek duplicitního kódu, ale potřebuji mít ty funkce dvě, aby streaming běžel paralelně z obou. Měl bych ideálně udělat třídu a k ní dvě instance, ale kvůli pár řádkům se mi nechtělo snížit čitelnost kódu, ostatně smyslem není mít krásný Python, ale něco, co bude snadno pochopitelné.
Standardizovaný monitoring generativního AI s OpenTelemetry
Aplikační monitoring čítá tři základní disciplíny - metriky (nejčastěji Prometheus a Grafana), logy (Elastic, Loki, Azure Monitor) a traces (dnes OpenTelemetry například do Application Insights) a skvělé je, že OpenTelemetry už dlouho pracuje na možnosti všechno sjednotit do jediného standardu. Pokud tedy chceme monitorovat volání do jazykových modelů, co od toho chtít? Tracing, tedy možnost vidět časový rozpad kdy co začalo a kdy skončilo v kontextu třeba od kliknutí uživatele v aplikaci až po doručení výsledků, logování (v terminologii OpenTelemetry je to “events”) jako jsou kdo co do AI poslal a co z něj vypadlo (pro případné reklamace, vyšetřování či ladění chyb) a metriky, tedy například spotřebované tokeny modelu. A víte co? Tohle už je v OpenTelemetry (zatím experimentálně) definováno: čtěte standard OpenTelemetry pro AI.
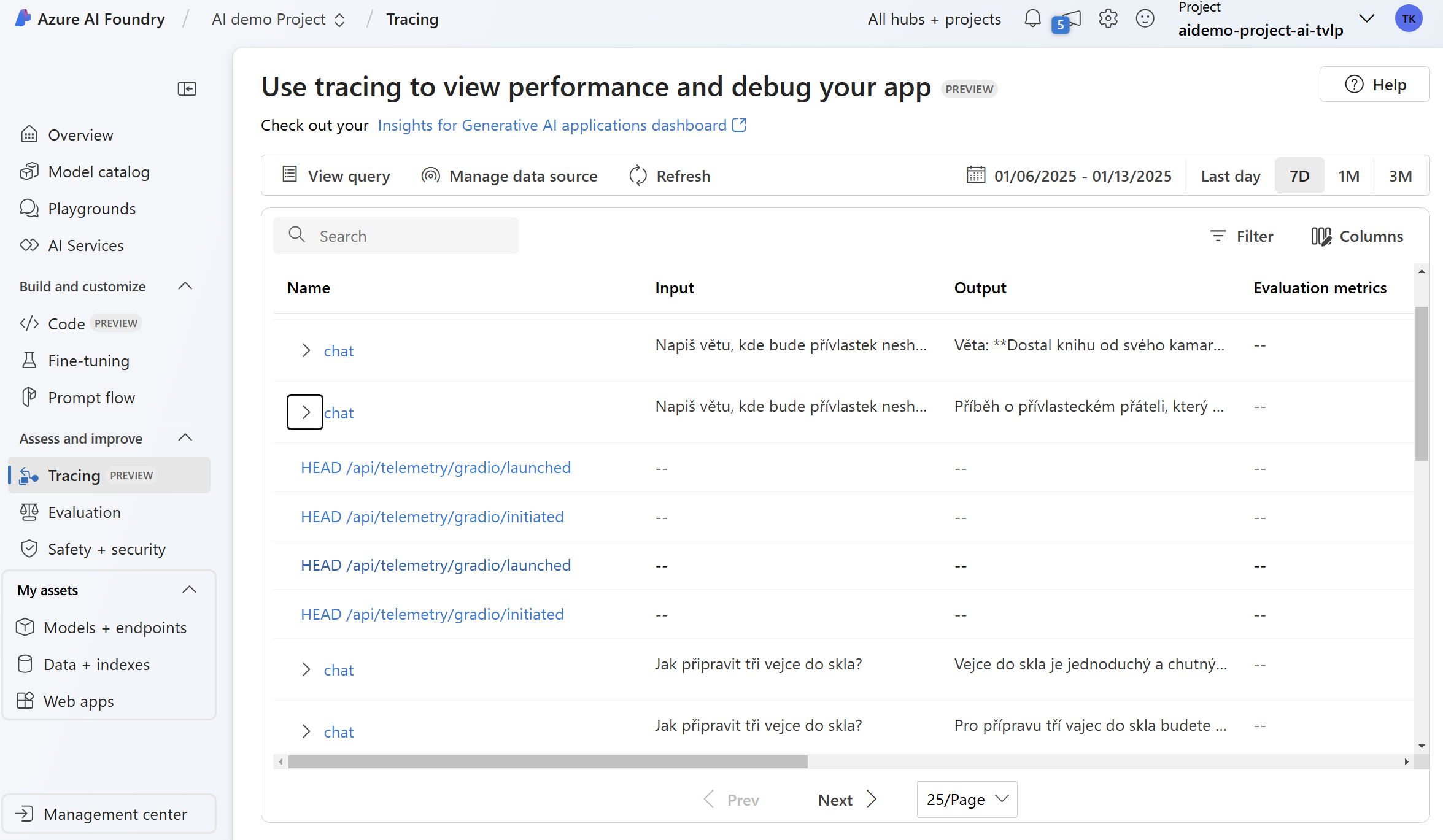
Právě to je implementované v Azure AI Foundry SDK a stačí to doslova zapnout a v mém případě namířit na Applications Insights. Výsledek vypadá takhle:
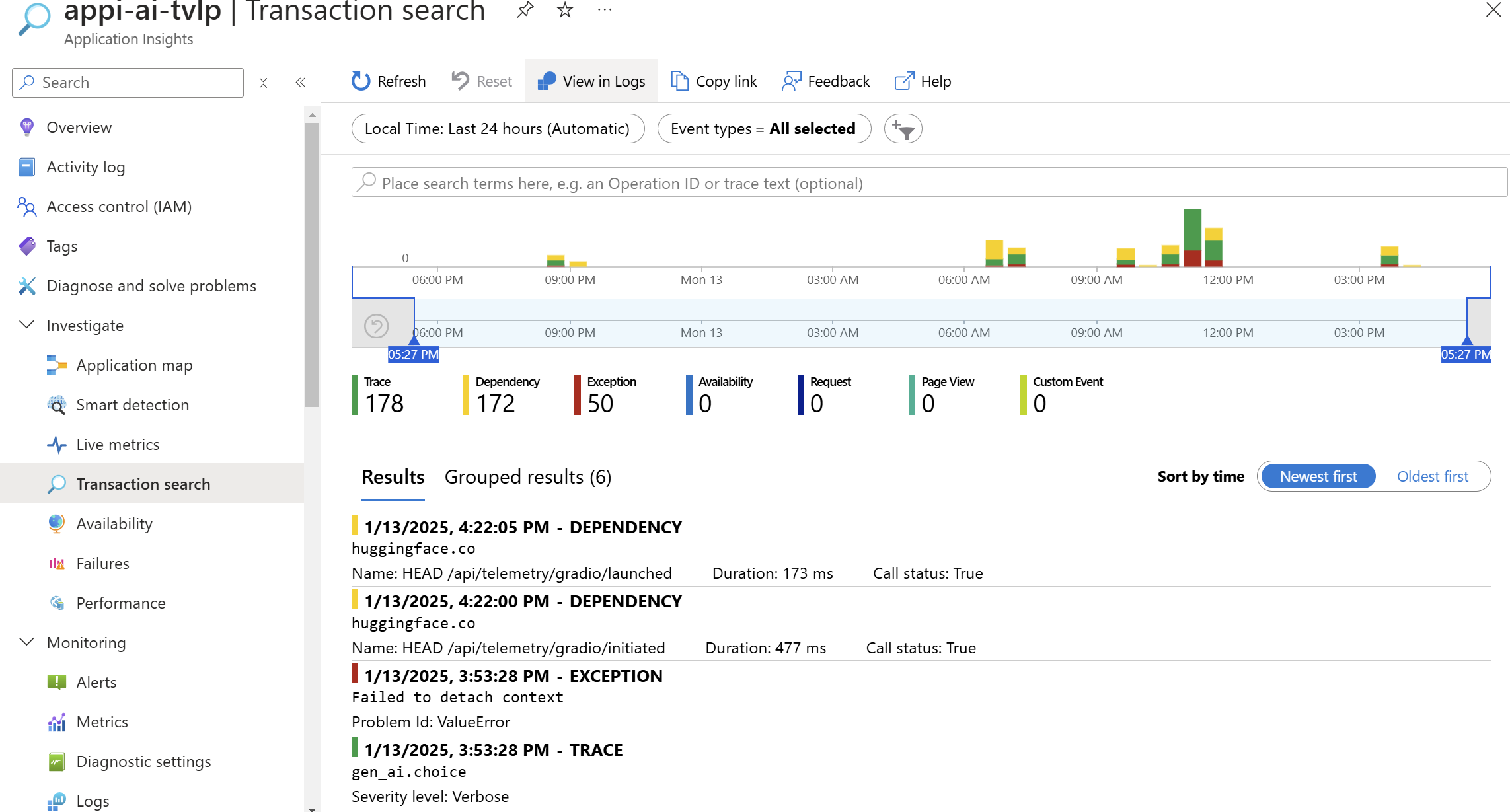
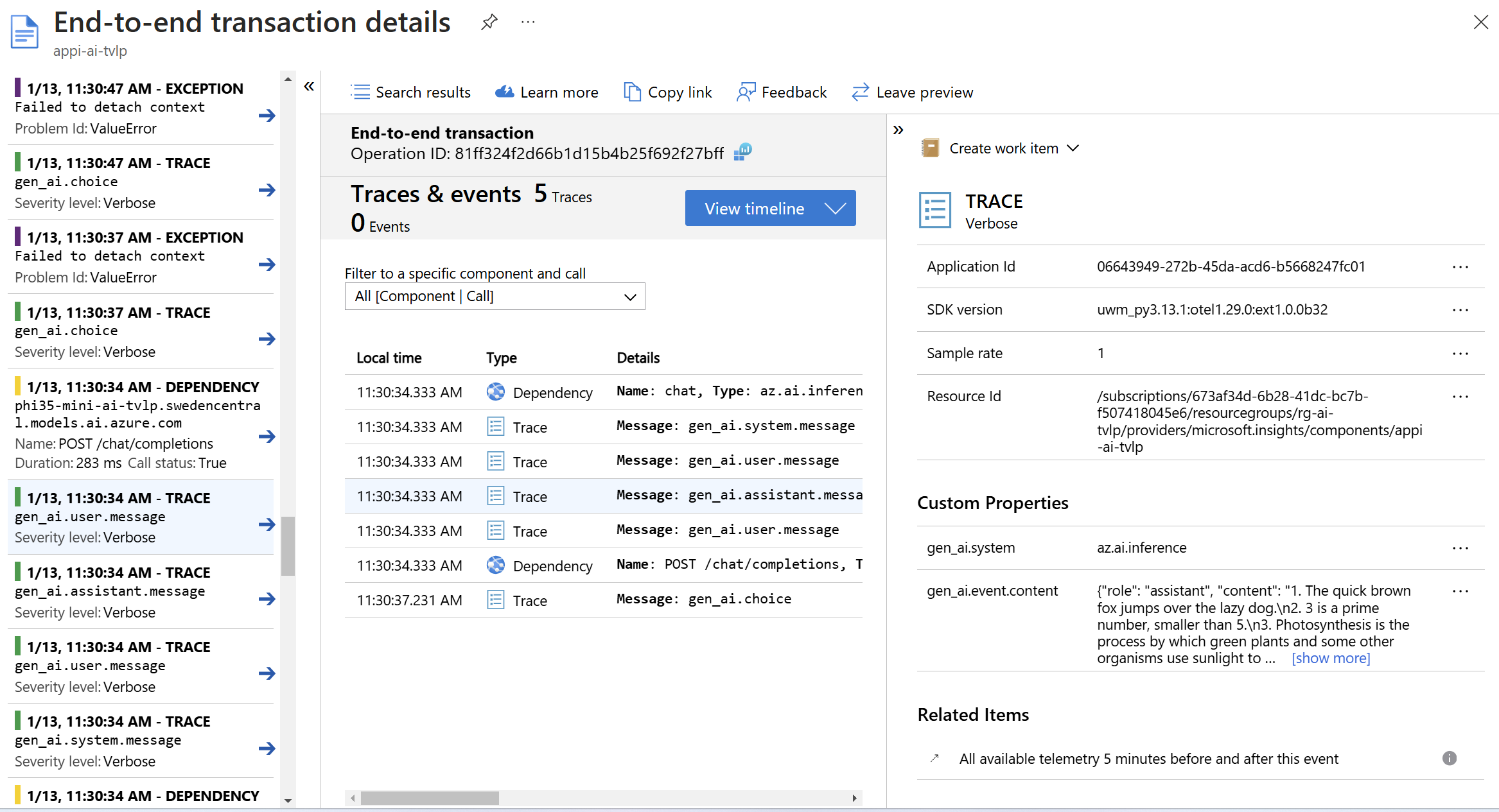
Vidíte, že jde o standardní vizualizaci, uložení a vyhledávání v OpenTelemetry datech - nic proprietárního pro Azure. Pro AI specialisty by ale možná byl lepší jiný pohled - a ten nabízí AI Foundry. Stačí ho namířit na váš Application Insights a vizualizovat data takhle:
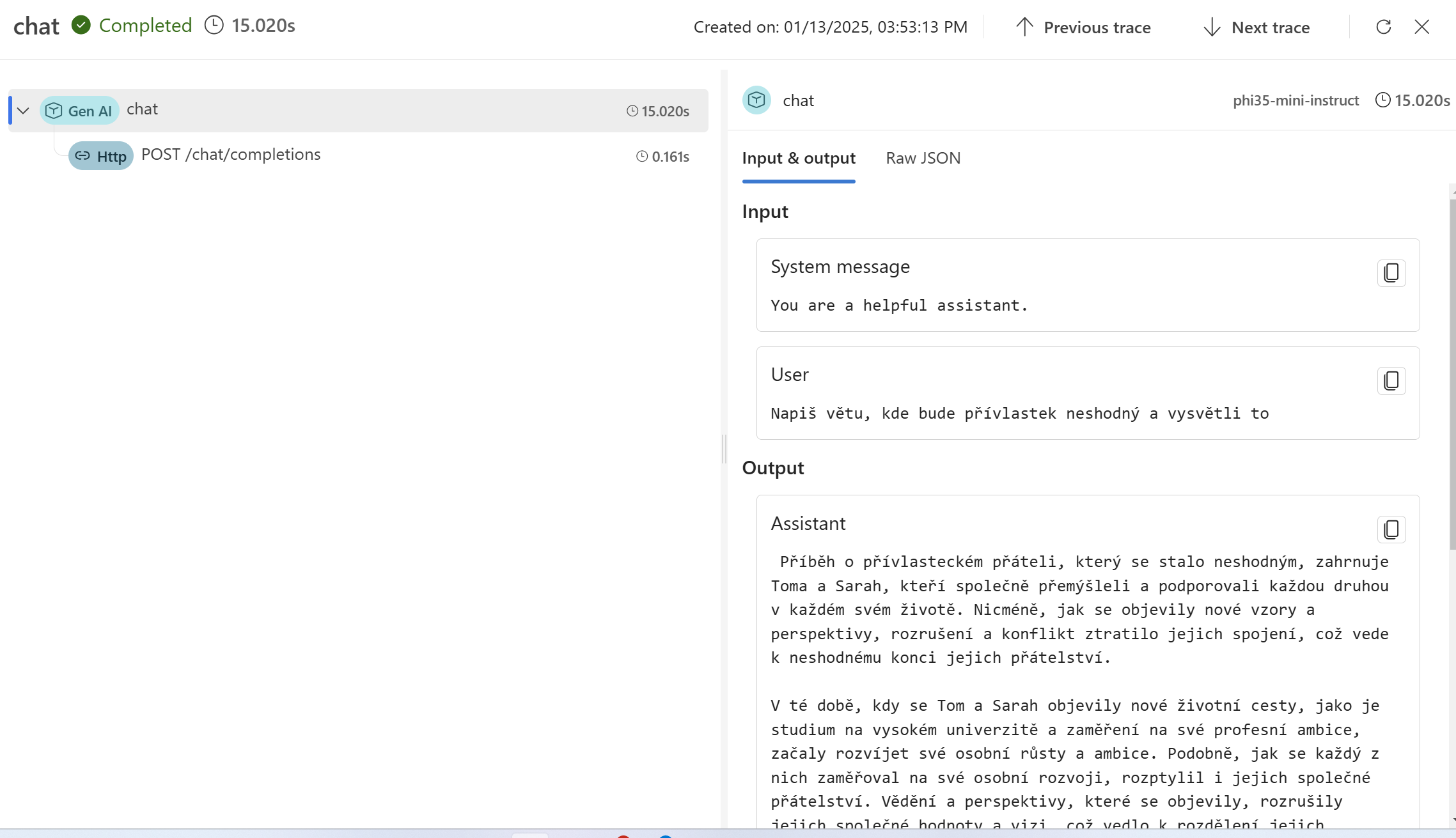
Zabalení a použití v Azure Container Apps
Dobrá tedy, pojďme aplikaci zabalit do kontejneru. K tomu stačí Dockerfile, který najdete na mém GitHubu, kde kromě Python image instaluji navíc ještě Node. Důvod pro to mám ten, že Gradio podporuje server-side rendering (a k němu musí být Node na serveru), což zrychluje načítání pro uživatele.
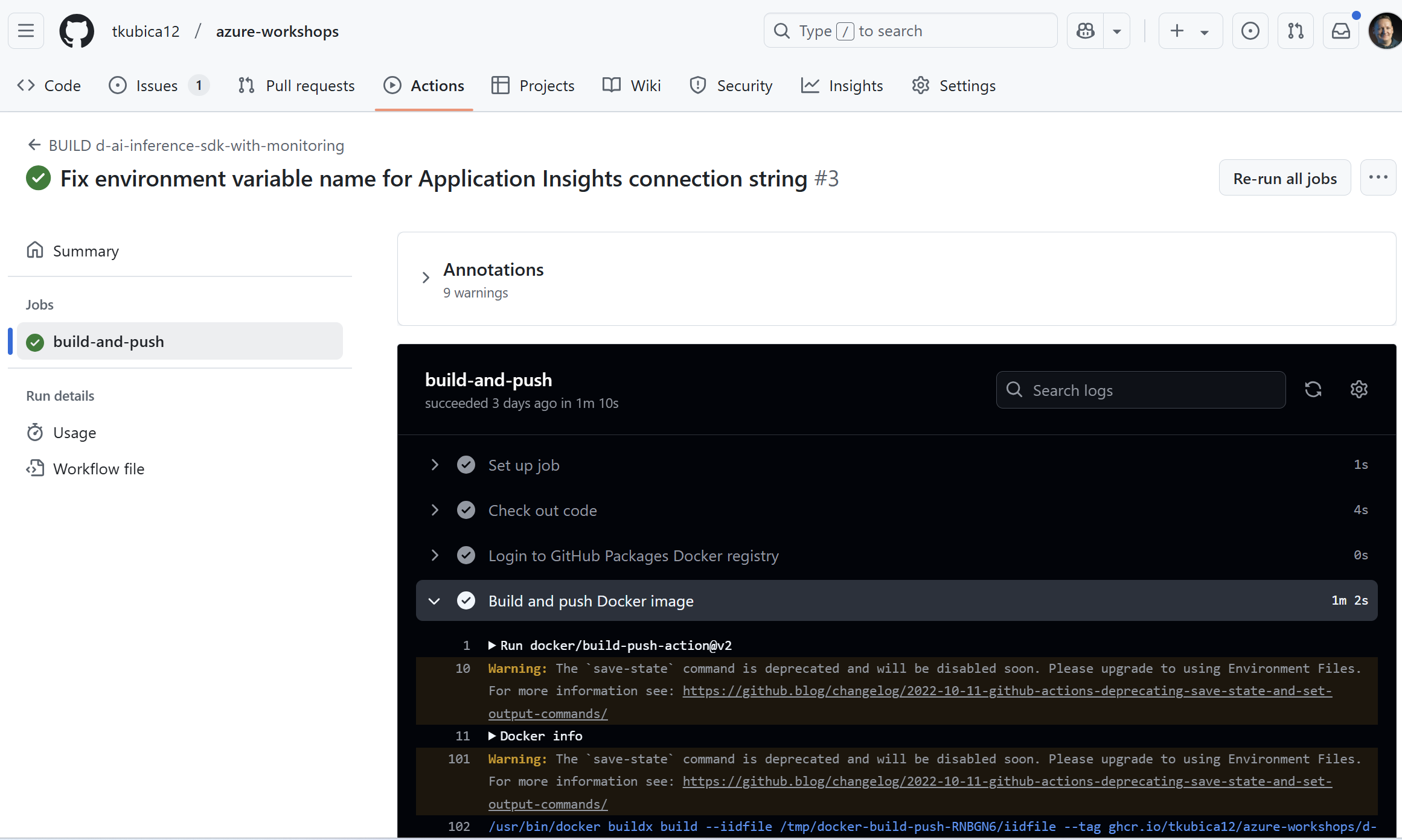
Build kontejneru provádím v GitHub Actions a publikuji do GitHub Packages.
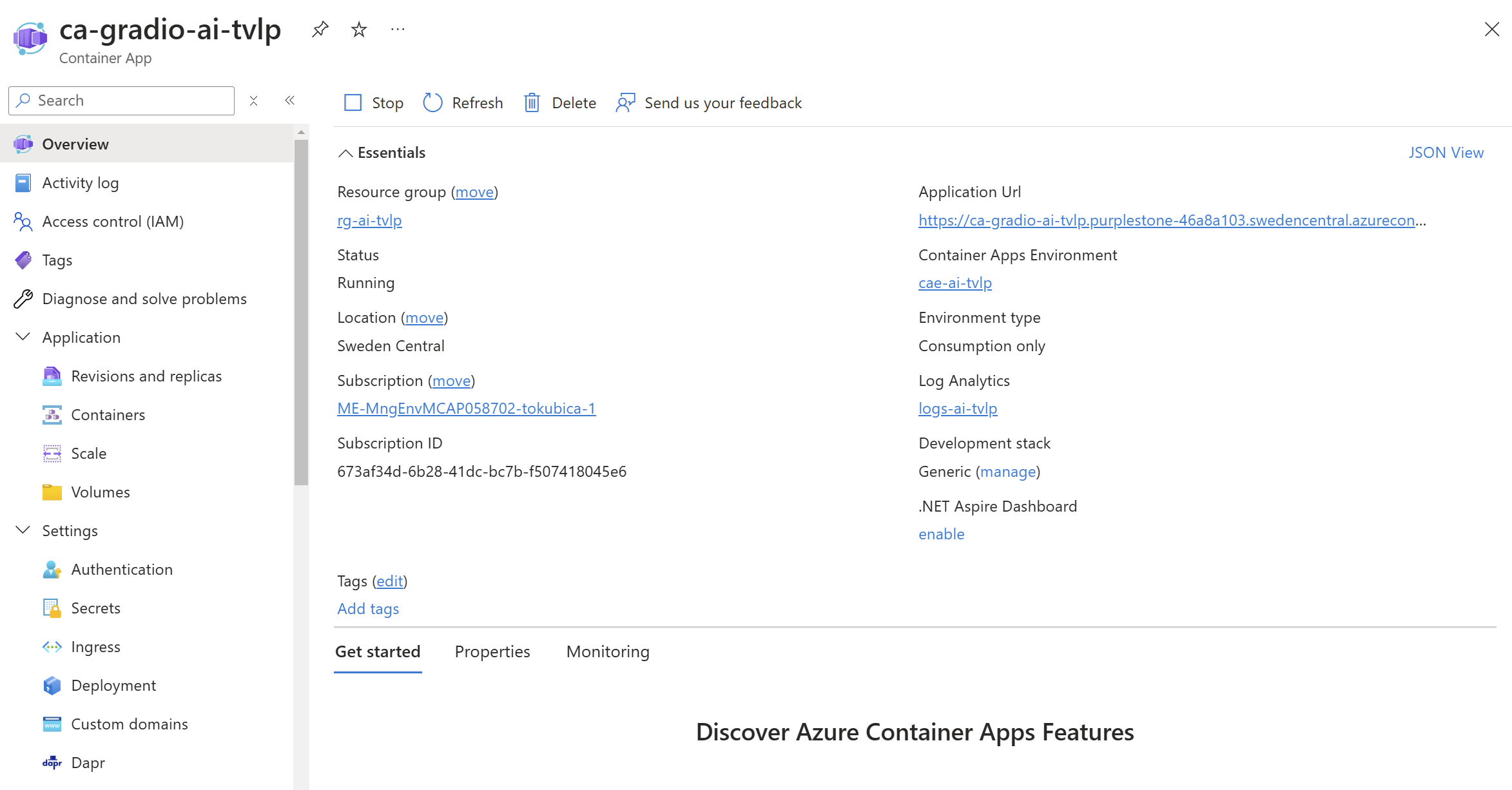
Následně je aplikace společně s konfiguračními údaji (napojení Application Insights, endpointy a klíče pro jednotlivé modely) nasazena do Azure Container Apps, což je serverless kontejnerové řešení. Nemusím mít plný šelmostroj typu Kubernetes, mám URL, certifikát a když se delší dobu nepřipojím, tak se aplikací uspí a přestanu platit.
Terraform pro automatizaci všeho, co na appku v Azure potřebuji
Kompletně celé prostředí, tedy AI Foundry Hub, Project, AI Service a nasazení jednotlivých Phi a OpenAI modelů, Azure Container Apps, monitoring a tak podobně chci automatizovaně nasadit přes Terraform. Dáte terraform apply a za pár minut už svítí URL a testujete si modely v aréně. Všechny zdroje najdete na mém GitHubu, tady zmíním pár věcí, co jsem musel vyřešit:
- AI Foundry nemá podporu v “ručním” provideru
azurerm, takže jsem na několika místech použil nativníazapi. Práce s ním je v pohodě, podporuje všechno, ale ruční modul může být v některých aspektech vychytanější (například při nasazování OpenAI modelů jsem přesazapinarážel na to, že je dělám ve smyčce paralelně a Azure to v tomto případě trápí a hodí chybu, s čímž seazurermevidentně umí na pozadí vypořádat - proto tento model nasazuji přesazurerm, kde už to jde). - Modely chci mít jednoduše rozšiřitelné, takže jsem použil mapu v locals. Pro serverless model a OpenAI model potřebuji trochu jiné informace, tak to řeším jako dvě mapy.
- Aplikace potřebuje mít seznam dostupných modelů a jejich endpointů a klíčů a jejich počet může být proměnlivý. Používám tedy konfigurační JSON soubor, nicméně u Azure Container Apps zatím nelze vstřikovat jednoduše soubor (něco jako ekvivalent ConfigMap v Kubernetes). Dal by se použít Key Vault a Azure App Configuration Service, ale já chtěl udržet jednoduchý lokální debug bez mnoha dependencí. Ve výsledku tedy appka hledá JSON soubor a když ho nenajde, tak si ho může načíst z environmentální proměnné z base64 verze. Aby to bylo snadné, tak JSON montuji přímo v Terraformu (dosadím názvy, endpointy a klíče) a přes funkce jsonencode a base64encode to předám do Azure Container App.
Dejte vědět jestli vám funguje a budu rád, když si s tím budete taky hrát, ukážete to dalším nebo nasdílíte svoje nápady a úpravy.