Chytré optimalizace a řízení přístupu k Azure OpenAI s použitím GenAI gateway v Azure API Management
Jak se AI stává součástí vašich aplikací nebo se dokonce vaše mikroslužby mění na AI agenty, začne se řešit kolik co vlastně stojí, jak efektivně využívat rezervovanou kapacitu (PTU), jak mít přehled, řídit přístupy jednotlivých agentů a aplikačních komponent a zajistit nějakou centrální governance. Azure AI Foundry v sobě hodně z toho obsahuje díky členění na huby a projekty nebo vizualizaci OpenTelemetry trasovaní, ale pokud potřebujete větší flexibilitu, schopnost přidávat věci jako cache, rate limiting, bezpečnost, developerský portál s řízením přístupů nebo možnost využívat OpenAI, serverless open source modely ve Foundry, ale třeba i nějaké endpointy zcela mimo Azure nabídku, pak koukněte na GenAI gateway v Azure API Managementu. Já jsem to udělal a pojďme na to spolu mrknout.
Jako obvykle všechny zdrojáky, tedy Terraform na nahození celého dema a testovací aplikaci, najdete u mě na GitHubu
Základní struktura použití GenAPI přes APIM
Terraform nahodí Azure API Management a přes OpenAPI specifikace vygeneruje příslušné API, takže z pohledu aplikace není potřeba dělat žádné zásadní změny (k tomu se ještě vrátíme). APIM následně podporuje vytváření politik, které v rámci zpracování požadavků mohou vstupovat do procesování a to jak na vstupu tak na výstupu. V mém případě půjde o tyto funkce:
- Rate limiting na vstupu pro jednotlivé zaregistrované aplikace (mikroslužby, agenty apod.), abych mohl řídit rozumný a férový přístup ke službě.
- Přetékání z PTU (předplacené kapacity) do PAYG (pay as you go) - když je kapacita PTU vyčerpána, dokončí se dotaz na PAYG endpointu aniž by o tom aplikace potřebovala vědět. Tady samozřejmě mohu uvažovat o dalších složitějších scénářích jako je balancování po planetě či dokonce odklánění na jiný model.
- Sémantický caching, abych nezatěžoval AI častými dotazy a díky tomu narychlil odpověď uživatelům a šetřil na placených tokenech.
Abych jednotlivé scénáře odlišil, dal jsem politiku odklánění (defacto balancování AI endpointů s prioritizací) do základního nastavení samotného API, takže je stejná pro všechny. Ostatní řeším na úrovni “Produktu”, což je to, k čemu se může vývojář aplikace zapsat. Používám Gold, kde nejsou žádné další politiky, ale také mám produkt Silver, ve kterém dochází k rate limit. Třetí produkt je Caching, tedy ten, kde je zapnuté sémantické cachování. Je samozřejmě zcela na vás kde a jaké politiky implementujete, řešení je velmi flexibilní.
Podstatné pro mě také je, že tohle není něco co bych dělal jen kvůli LLM API. Tyto koncepty správy by měly v organizaci platit obecně pro všechna API, protože podporují dobrou hygienu, governance, bezpečnost, monitoring i produktivitu. GenAI do toho zaklapne jako další API - to považuji za klíčovou výhodu ve světě, kde se LLM stává běžnou součástí mikroslužeb a je to API volání jako každé jiné.
Přetékání aneb chytré řízení AI endpointů
Tahle politika vypadá poměrně složitě, ale nemusel jsem ji psát já - je v dokumentaci a stačilo ji zkopírovat. Jak funguje? Politika si udržuje přehled o všech nastavených AI endpointech a to včetně jejich prioritizace. Pokud přijde požadavek, tak ho rozhodí náhodně na nějaký z endpointů priority jedna (v mém případě tam mám jen jeden endpoint představující moje PTU - ale pro demo používám PAYG). Pokud to přeťápnu, endpoint začne vracet chybu 429 (už nestíhám) a s ní v hlavičce za jak dlouho se mám vrátit zpět, aby bylo zase “nabito”. Normálně bychom tohle vrátili aplikaci a ta musí udělat retry a tím pádem uživatel čeká. APIM ale v tento okamžik vyřadí tento endpoint z koloběhu a to na dobu uvedenou právě v Retry-After hlavičce a obrátí se na nějaký jiný endpoint ideálně stejné priority a pokud už tam žádný není, jde na další prioritu (to je můj případ). Vůči aplikaci je to transparentní, ta dostane až hotový výsledek a abych to mohl monitorovat, tak jí v hlavičce vrátím ještě informaci, který endpoint jsem použil. Celé je to postaveno na custom kódu a využívání perzistentní cache pro APIM (v mém případě je použit externí Azure Managed Redis, což pak stejně potřebuji pro sémantický caching).
Tohle je testovací aplikace:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
import os
import time # added import
import math # added import
from openai import AzureOpenAI
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
from dotenv import load_dotenv
from azure.monitor.opentelemetry import configure_azure_monitor
from azure.core.settings import settings
from opentelemetry.sdk.resources import Resource, SERVICE_NAME
from opentelemetry.instrumentation.openai_v2 import OpenAIInstrumentor
# Load environment variables
load_dotenv()
endpoint = os.getenv("ENDPOINT_URL")
deployment = os.getenv("DEPLOYMENT_NAME")
subscription_key = os.getenv("SUBSCRIPTION_KEY")
# appinsights_connection_string = os.getenv("APPLICATIONINSIGHTS_CONNECTION_STRING")
# # Configure Azure Monitor - does not currently work as OpenAI SDK implements this only in newer version, not legacy one. But legacy is used in this demo to access to raw headers which is not yet available in newer version of OpenAI SDK.
# resource = Resource.create({SERVICE_NAME: "AI Worker Service"})
# configure_azure_monitor(connection_string=appinsights_connection_string, resource=resource)
# settings.tracing_implementation = "opentelemetry"
# OpenAIInstrumentor().instrument()
# Initialize Azure OpenAI Service client with Entra ID authentication
token_provider = get_bearer_token_provider(
DefaultAzureCredential(),
"https://cognitiveservices.azure.com/.default"
)
client = AzureOpenAI(
azure_endpoint=endpoint,
azure_ad_token_provider=token_provider,
api_version="2024-05-01-preview",
max_retries=20,
default_headers = {"Ocp-Apim-Subscription-Key": subscription_key}
)
# Initialize counters for tokens calculation
total_token_usage = 0
backend_tokens = {}
# Start timing
start_time = time.time() # added start time
# Function to print running statistics
def print_running_stats(total_token_usage, backend_tokens, start_time, request_start_time):
elapsed_seconds_running = time.time() - start_time
elapsed_minutes_running = math.ceil(elapsed_seconds_running / 60)
request_elapsed_seconds = time.time() - request_start_time
tokens_per_minute_running = total_token_usage / elapsed_minutes_running
print(f"Running total tokens: {total_token_usage}")
print(f"Running tokens per minute: {int(tokens_per_minute_running)}")
print(f"Request time: {request_elapsed_seconds:.2f} seconds")
print("Tokens per backend so far:")
for url, tokens in backend_tokens.items():
print(f" {url}: {tokens}")
test_messages = [
"Hello!",
"How can I open Word document in Windows 11?",
"What is data quality management good for in context of IT?",
"Give me advantages of using data quality management.",
"What are reasons for using data quality management?",
"Write long text about life, universe and everything.",
"Write long text about life, universe and everything.",
"Write long text about life, universe and everything, please.",
"Write text about life, universe and everything.",
"Write long text about life, universe, and everything.",
]
for message in test_messages:
messages = [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": message
}
]
request_start_time = time.time()
response = client.chat.completions.with_raw_response.create(
model=deployment,
messages=messages,
max_tokens=1000,
temperature=0.7,
top_p=0.95,
frequency_penalty=0,
presence_penalty=0,
stop=None,
stream=False
)
response_parsed = response.parse()
current_tokens = response_parsed.usage.total_tokens
total_token_usage += current_tokens
backend_url = response.headers.get('x-openai-backendurl')
if backend_url in backend_tokens:
backend_tokens[backend_url] += current_tokens
else:
backend_tokens[backend_url] = current_tokens
response_text_shortened = response_parsed.choices[0].message.content[:80].replace("\n", " ") + "..."
print(f"\nResponse {current_tokens} tokens: {response_text_shortened}")
print(f"x-openai-backendurl: {backend_url}")
print_running_stats(total_token_usage, backend_tokens, start_time, request_start_time)
# Print final statistics
print("\n-----------------------------------")
print("Final stats:")
print_running_stats(total_token_usage, backend_tokens, start_time, start_time)
Pro aplikaci (mikroslužba, agent) vytvořím subskripci a tím získám unikátní kód. Není to jediná varianta, ale tahle je jednoduchá - stačí tento kód přidat do headeru v komunikaci. Tím je jednoduše možné řídit jednotlivé aplikace a mít přehled v tom co a kolik která mikroslužba používá.
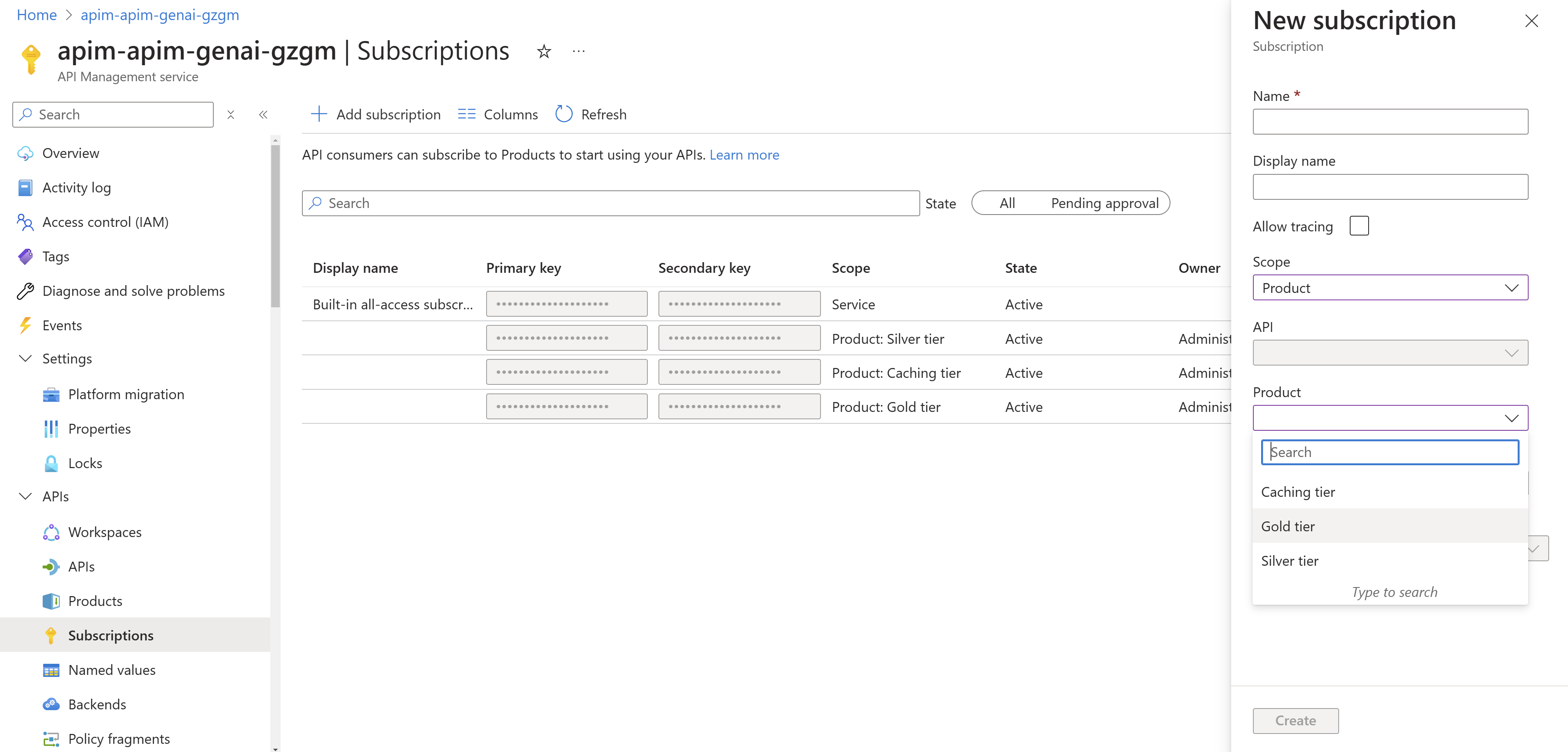
Header zařídíme jednoduše - AzureOpenAI instance klienta podporuje default_headers, takže stačí přidat do konstruktoru.
Aplikace, jak vidíte v kódu, bude posílat několik dotazů za sebou. Tady je výsledek ve variantě Gold, tedy se zapnutým přetékáním. Všimněte si, že po 2000 tokenech už můj primární endpoint začínající na p1 dojde na své limity a transparentně se přepnu na p2.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
Response 28 tokens: Hello! How can I assist you today?...
x-openai-backendurl: https://p1-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 28
Running tokens per minute: 28
Request time: 6.82 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 28
Response 560 tokens: Opening a Word document in Windows 11 can be done in several ways. Here are some...
x-openai-backendurl: https://p1-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 588
Running tokens per minute: 588
Request time: 3.36 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 588
Response 468 tokens: Data quality management (DQM) is essential in the context of IT for several reas...
x-openai-backendurl: https://p1-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 1056
Running tokens per minute: 1056
Request time: 3.25 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 1056
Response 481 tokens: Data Quality Management (DQM) refers to the processes and practices that ensure ...
x-openai-backendurl: https://p1-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 1537
Running tokens per minute: 1537
Request time: 3.27 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 1537
Response 523 tokens: Data Quality Management (DQM) is essential for organizations that rely on data f...
x-openai-backendurl: https://p2-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 2060
Running tokens per minute: 2060
Request time: 3.90 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 1537
https://p2-apim-genai-gzgm.openai.azure.com/openai: 523
Response 1027 tokens: The quest to understand life, the universe, and everything is perhaps one of hum...
x-openai-backendurl: https://p2-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 3087
Running tokens per minute: 3087
Request time: 7.81 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 1537
https://p2-apim-genai-gzgm.openai.azure.com/openai: 1550
Response 984 tokens: The concept of life, the universe, and everything has fascinated humanity for mi...
x-openai-backendurl: https://p2-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 4071
Running tokens per minute: 4071
Request time: 13.97 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 1537
https://p2-apim-genai-gzgm.openai.azure.com/openai: 2534
Response 817 tokens: The concept of life, the universe, and everything is both a profound philosophic...
x-openai-backendurl: https://p2-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 4888
Running tokens per minute: 4888
Request time: 6.06 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 1537
https://p2-apim-genai-gzgm.openai.azure.com/openai: 3351
Response 487 tokens: Life, the universe, and everything is a vast and profound topic that has captiva...
x-openai-backendurl: https://p2-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 5375
Running tokens per minute: 5375
Request time: 3.44 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 1537
https://p2-apim-genai-gzgm.openai.azure.com/openai: 3838
Response 1028 tokens: The quest to understand life, the universe, and everything is perhaps one of the...
x-openai-backendurl: https://p2-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 6403
Running tokens per minute: 3201
Request time: 8.85 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 1537
https://p2-apim-genai-gzgm.openai.azure.com/openai: 4866
-----------------------------------
Final stats:
Running total tokens: 6403
Running tokens per minute: 3201
Request time: 60.75 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 1537
https://p2-apim-genai-gzgm.openai.azure.com/openai: 4866
Rate limiting
Můj Silver produkt nad základní přetékací politiku přidává rate limit nastavený na 1000 tokenů za minutu.
1
2
3
4
5
6
7
8
9
10
11
12
13
<policies>
<inbound>
<base />
<azure-openai-token-limit
counter-key="@(context.Subscription.Id)"
tokens-per-minute="1000"
estimate-prompt-tokens="true"
remaining-tokens-variable-name="remainingTokens" />
</inbound>
<outbound>
<base />
</outbound>
</policies>
Vyzkoušejme teď aplikaci s klíčem z Silver produktu. APIM teď po 1000 tokenech vrátí aplikaci 429 a ta musí počkat (SDK zvládá retry samo) a dobře vidíme, že to funguje. Můžeme tak efektivně ubránit naše endpointy před zbytečným přetížením nebo nějakou chybou či útokem. Samozřejmě si s tím lze hrát víc - například přidat další tiery s jinými limity nebo třeba udělat produkt, kde prvních x tokenů za minutu či hodinu bude od gpt-4o, ale pak se to přepne na gpt-4o-mini a tak podobně.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
Response 28 tokens: Hello! How can I assist you today?...
x-openai-backendurl: https://p1-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 28
Running tokens per minute: 28
Request time: 3.14 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 28
Response 623 tokens: Opening a Word document in Windows 11 can be done in several ways. Here are the ...
x-openai-backendurl: https://p1-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 651
Running tokens per minute: 651
Request time: 5.08 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 651
Response 517 tokens: Data Quality Management (DQM) is crucial in the context of Information Technolog...
x-openai-backendurl: https://p1-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 1168
Running tokens per minute: 1168
Request time: 3.74 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 1168
Response 499 tokens: Data Quality Management (DQM) is essential for organizations that rely on data f...
x-openai-backendurl: https://p1-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 1667
Running tokens per minute: 833
Request time: 60.44 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 1667
Response 548 tokens: Data quality management (DQM) is essential for organizations to ensure that thei...
x-openai-backendurl: https://p1-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 2215
Running tokens per minute: 1107
Request time: 3.50 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 2215
Response 1006 tokens: The question of life, the universe, and everything is one that has captivated hu...
x-openai-backendurl: https://p1-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 3221
Running tokens per minute: 1073
Request time: 64.73 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 3221
Response 956 tokens: The quest for understanding life, the universe, and everything is perhaps one of...
x-openai-backendurl: https://p1-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 4177
Running tokens per minute: 1044
Request time: 68.36 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 4177
Response 1029 tokens: Life, the universe, and everything is a concept that has intrigued humanity for ...
x-openai-backendurl: https://p1-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 5206
Running tokens per minute: 1301
Request time: 6.82 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 5206
Response 516 tokens: The concept of life, the universe, and everything has been a central theme in ph...
x-openai-backendurl: https://p1-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 5722
Running tokens per minute: 1144
Request time: 63.84 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 5722
Response 1028 tokens: The quest to understand life, the universe, and everything is a fundamental aspe...
x-openai-backendurl: https://p1-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 6750
Running tokens per minute: 1350
Request time: 6.91 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 6750
-----------------------------------
Final stats:
Running total tokens: 6750
Running tokens per minute: 1350
Request time: 286.57 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 6750
Sémantický caching
Je možné, že ve vaší aplikaci se některé základní dotazy opakují stále dokola - věci typu “ahoj, jak mi můžeš pomoci” nebo základní dotazy na produkt (jak se licencuje to a to, jaký je rozdíl mezi funkcí X a Y). Nebylo by možné tyto věci neodbavovat v LLM, které stojí nějaké peníze a trvá to vteřiny, ale odpovědět rovnou z nějaké cache? Rozhodně! Ale opatrně. Jak na to?
Lidé dělají překlepy a ve svých dotazech mohou mít použita trochu jiná slova, předložky, ale význam je stejný. Jednoduchá exact-match cache tak moc užitečná nebude, ale můžeme použít sémantický search s využitím embeddingů tak, jak se to dělá třeba u Retrieval Augmented Generation. Když přijde dotaz, uděláme embedding a koukli bychom do vektorové databáze (v případě APIM je to RediSearch) jestli tam nemáme uloženu předchozí odpověď na hodně podobnou otázku. Pokud ano, servírujeme z cache a dramaticky šetříme a navíc uživatel má odpověď podstatně rychleji.
Nicméně pozor na bezpečnost - odpověď jinému uživateli mohla obsahovat něco citlivého, takže nějaká centrální cache přes všechny uživatele představuje zásadní riziko. Proto doporučuji dva přístupy případně jejich kombinaci:
- Cache se nemusí vytvářet dynamicky, můžeme do ní vkládat klidně “ručně” a jen ji číst. Pokud máte například seznam častých otázek, tak je můžeme vzít, poslat do AI pro odpověď a výsledek si uložit s tím, že to máme pod kontrolou a víme, že v datech není nic citlivého. Na časté otázky tak uživatel dostane rychlou, levnou a bezpečnou odpověď z cache.
- Cache se dá ukládat podle nějakého klíče, což může být cokoli co APIM dostane například z requestu. Ve svém demu používám subscription key, takže cache je per aplikace, ale stejně tak to může být nějaký header s ID oddělení, konkrétního zákazníka nebo uživatele. Čili takto dynamickým způsobem nemůžu zaručit, že uložená odpověď neobsahuje nic specifického pro daného zákazníka, ale pokud ji ukládám per zákazník, tak to nemusí vadit. Mohli bychom samozřejmě řešit i to, že před uložením si projdeme texty modelem pro identifikaci třeba PII - to není špatná varianta, je to k dispozici jako služba v Azure Cognitive Services, ale bude to trochu složitější.
Za mě - začal bych polo-ručně připravenou cache pro nejčastější otázky a to hlavně takové ty úvodní, které se opakují stále dokola a nejsou specifické (uživatel se ptá na obecnou funkci - například jak mám zabalit zásilku před odesláním a ne mám zásilku číslo 123456789 a chci vědět kde je).
Tady je připravená politika - důležitý je parametr míry rozdílnosti. Větší číslo bude zachytávat více otázek jako podobných, menší bude přísnější.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
<policies>
<inbound>
<base />
<!-- <set-backend-service backend-id="${azapi_resource.embeddings_backend.name}" /> -->
<authentication-managed-identity resource="https://cognitiveservices.azure.com/" />
<azure-openai-semantic-cache-lookup
score-threshold="0.05"
embeddings-backend-id="${azapi_resource.embeddings_backend.name}"
embeddings-backend-auth="system-assigned"
ignore-system-messages="false"
max-message-count="2">
<vary-by>@(context.Subscription.Id)</vary-by>
</azure-openai-semantic-cache-lookup>
</inbound>
<outbound>
<azure-openai-semantic-cache-store duration="120" />
<base />
</outbound>
</policies>
Takhle to pak vypadá v testovací aplikaci. V mém případě je score-treshold takový, že otázky na data management, které jsou podobné, ale jsou v nich akcentovány trochu jiné aspekty, se nechají zpracovat LLM. Na druhou stranu otázky na smysl života, vesmírů a vůbec, jsou stejné a liší se jen v chybách v textu či drobnými změnami slov či interpunkce. Nastavení score-treshold je na vás a je potřeba si s ním pohrát. V mém příkladě jedu spíše na jistotu. Endpoint “none” ve výstupu představuje odpověď z cache.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
Response 28 tokens: Hello! How can I assist you today?...
x-openai-backendurl: https://p1-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 28
Running tokens per minute: 28
Request time: 4.83 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 28
Response 493 tokens: To open a Word document in Windows 11, you can follow these steps: ### Method 1...
x-openai-backendurl: https://p1-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 521
Running tokens per minute: 521
Request time: 4.58 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 521
Response 510 tokens: Data Quality Management (DQM) is crucial in the context of IT for several reason...
x-openai-backendurl: https://p1-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 1031
Running tokens per minute: 1031
Request time: 7.96 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 1031
Response 498 tokens: Data Quality Management (DQM) refers to the processes and practices that ensure ...
x-openai-backendurl: https://p1-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 1529
Running tokens per minute: 1529
Request time: 3.51 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 1529
Response 586 tokens: Data quality management (DQM) is essential for organizations to ensure that thei...
x-openai-backendurl: https://p2-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 2115
Running tokens per minute: 2115
Request time: 4.64 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 1529
https://p2-apim-genai-gzgm.openai.azure.com/openai: 586
Response 985 tokens: Life, the universe, and everything is a concept that has fascinated humanity for...
x-openai-backendurl: https://p2-apim-genai-gzgm.openai.azure.com/openai
Running total tokens: 3100
Running tokens per minute: 3100
Request time: 7.22 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 1529
https://p2-apim-genai-gzgm.openai.azure.com/openai: 1571
Response 985 tokens: Life, the universe, and everything is a concept that has fascinated humanity for...
x-openai-backendurl: none
Running total tokens: 4085
Running tokens per minute: 4085
Request time: 0.10 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 1529
https://p2-apim-genai-gzgm.openai.azure.com/openai: 1571
none: 985
Response 985 tokens: Life, the universe, and everything is a concept that has fascinated humanity for...
x-openai-backendurl: none
Running total tokens: 5070
Running tokens per minute: 5070
Request time: 0.10 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 1529
https://p2-apim-genai-gzgm.openai.azure.com/openai: 1571
none: 1970
Response 985 tokens: Life, the universe, and everything is a concept that has fascinated humanity for...
x-openai-backendurl: none
Running total tokens: 6055
Running tokens per minute: 6055
Request time: 0.10 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 1529
https://p2-apim-genai-gzgm.openai.azure.com/openai: 1571
none: 2955
Response 985 tokens: Life, the universe, and everything is a concept that has fascinated humanity for...
x-openai-backendurl: none
Running total tokens: 7040
Running tokens per minute: 7040
Request time: 0.11 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 1529
https://p2-apim-genai-gzgm.openai.azure.com/openai: 1571
none: 3940
-----------------------------------
Final stats:
Running total tokens: 7040
Running tokens per minute: 7040
Request time: 33.17 seconds
Tokens per backend so far:
https://p1-apim-genai-gzgm.openai.azure.com/openai: 1529
https://p2-apim-genai-gzgm.openai.azure.com/openai: 1571
none: 3940
Monitoring
Jednou z výhod centralizace volání přes API Management je jednotný sběr logů a metrik. Já jsem si přidal specificky GenAI metriku s vlastními dimenzemi:
1
2
3
4
5
6
7
<azure-openai-emit-token-metric namespace="openai">
<dimension name="Client IP" value="@(context.Request.IpAddress)" />
<dimension name="API ID" value="@(context.Api.Id)" />
<dimension name="Subscription ID" value="@(context.Subscription.Id)" />
<dimension name="Backend URL" value="@(context.Variables.GetValueOrDefault<string>("backendUrl", "none"))" />
<dimension name="User ID" value="@(context.Request.Headers.GetValueOrDefault("x-user-id", "N/A"))" />
</azure-openai-emit-token-metric>
Pak se na to samozřejmě můžeme koukat.
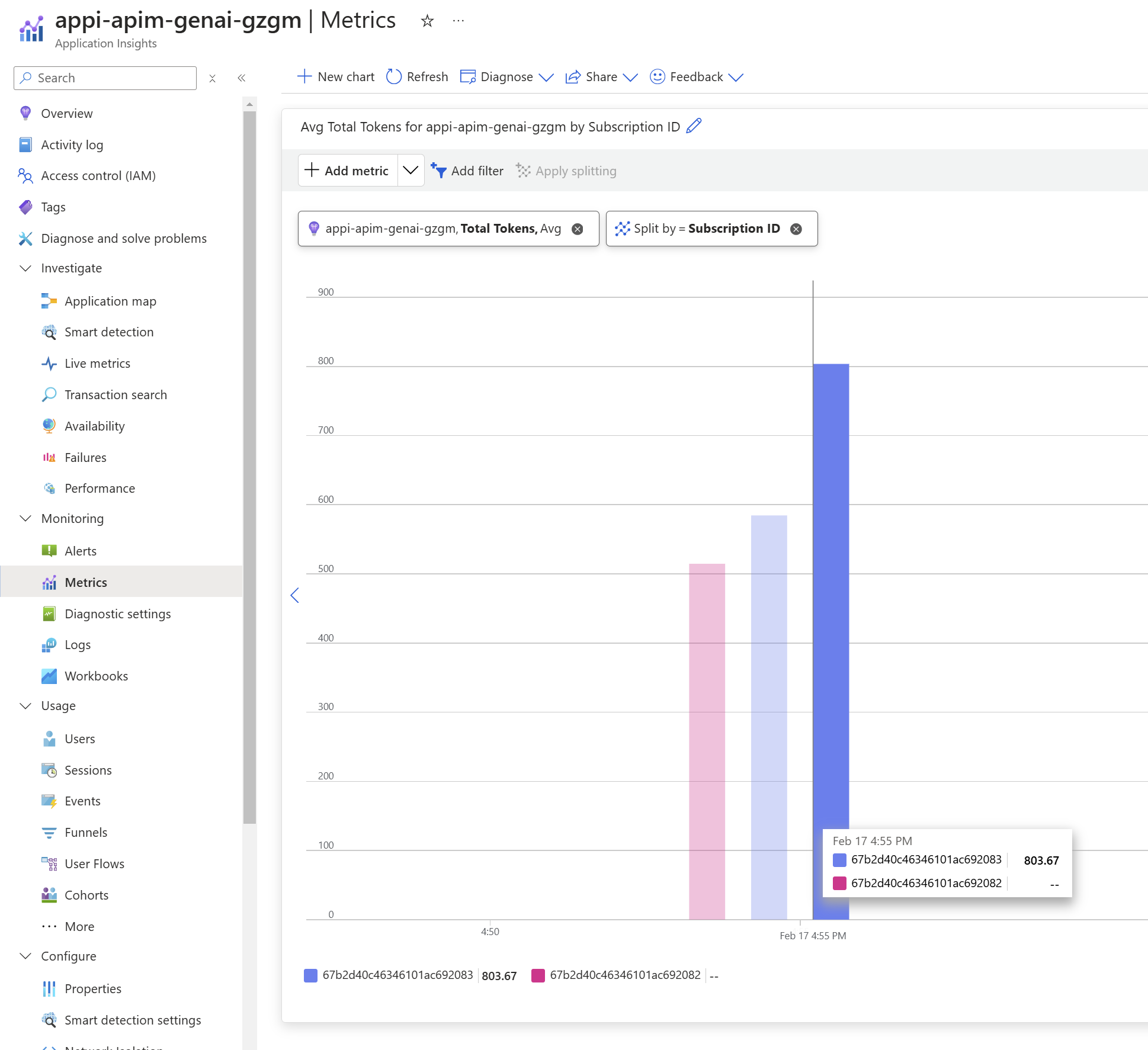
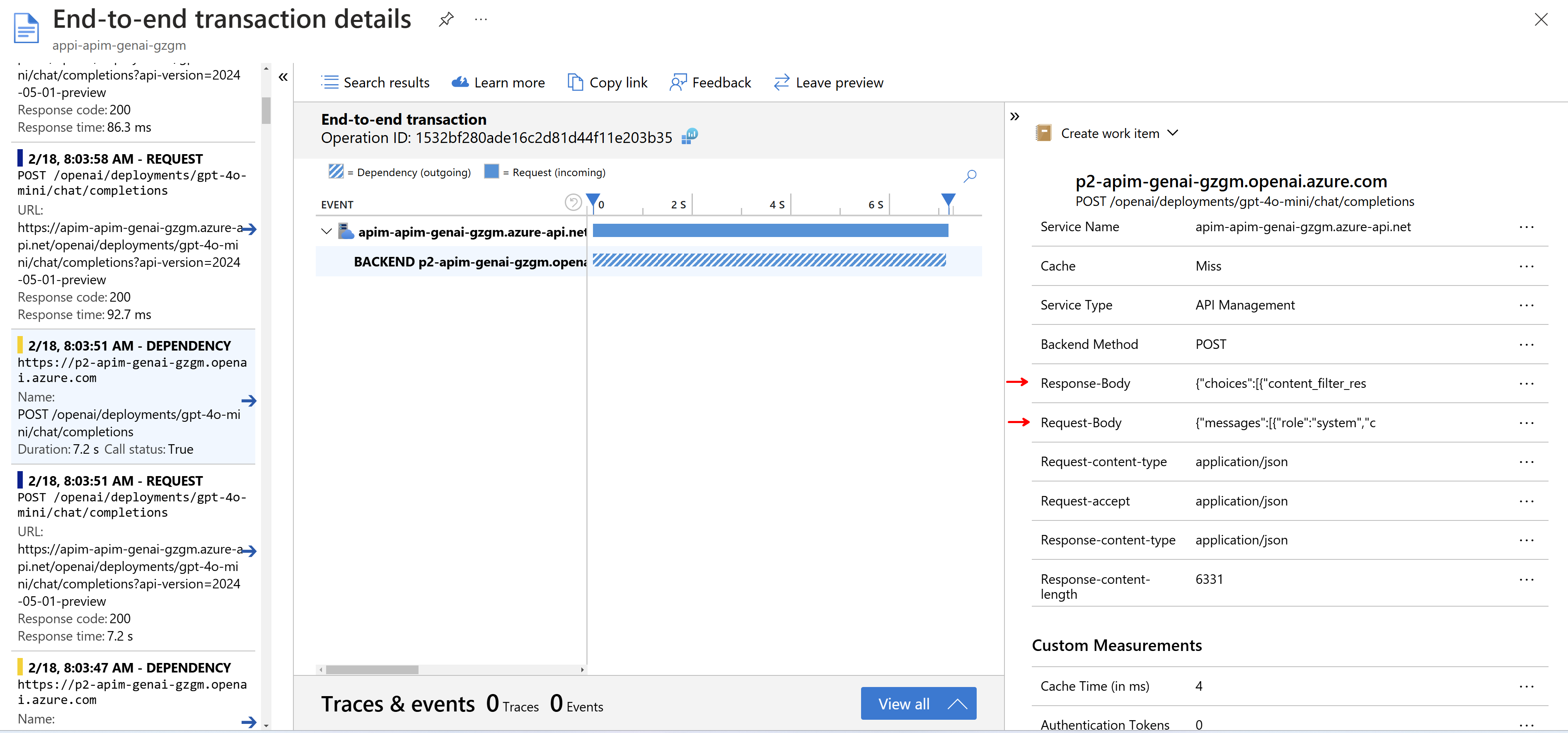
Kromě toho participuje API Management v trasování, takže i pokud vaše aplikace není instrumentovaná, můžete si klidně nejen nechávat informace o každém jednotlivém volání, ale dokonce i logovat celý obsah zpráv (ale pozor na bezpečnost a GDPR).
Závěr
Správa API je v moderní firmě zásadní, protože velké množství inovací jako jsou nové produkty a aplikace staví na službách, které už ve firmě existují nebo je připravuje jiný tým a ty je nutné dobře popsat, zabezpečit, monitorovat a řídit k nim přístup. Doby, kde nová aplikace začínala svůj život otázkou “v kterých databázích jsou data, která jsou pro nás zajímavá”, jsou snad už konečně pryč. Místo starého přístupu integrace přes databázi dnes použijete centrální katalog služeb ve formě třeba Azure API Managementu (možná v kombinaci s Azure API Center a Defender for APIs). AI mění hru, ale ne směrem k monolitickému centrálnímu mozku lidstva, ale k AI agentům se specializací na nějaké úkony a dovednosti. AI agent je pokračováním konceptu mikroslužby a má podobné vlastnosti - samostatný vývoj a nasaditelnost, vlastní perzistentní vrstvu a přístup na okolní API (v případě AI agentů jsou to nástroje, function calling). Role API managementu tak roste a je rozumné od něj očekávat porozumění nové měrné jednotce výkonu a zátěže - tokenům. To Azure API Management dělá.