Ukázka AI ad-hoc generovaného UI s Python FastHTML a OpenAI
Minule jsem popisoval, jak by mohlo AI využít svých znalostí programování k vytvoření ad-hoc uživatelského rozhraní. Dnes si něco takového vyzkoušíme, ale mějte na paměti, že je to jen jednoduchá ukázka konceptu. Určitě by se dalo generovat něco mnohem sofistikovanějšího a se zrychlováním modelů a současně s jejich větší inteligencí se tohle může dramaticky zlepšovat do budoucna.
Technologicky využiji minule popisované HTMX, tedy nadstavbu klasického HTML, která umí stránky dělat interaktivní a přitom renderované ze serveru. To pro nás bude důležité, protože vytvoření HMTX bude mít na starost jazykový model o4-mini a to jednak v reakci na otázku uživatele, ale také v reakci na interakci uživatele s tímto UI.
Celý příklad najdete u mě na GitHubu tady
V Pythonu se toho děje relativně málo. FastHTML udělá základní HTMX strukturu s oknem pro otázku uživatele, tlačítkem a místem pro vykreslení UI od AI. K tomu nějaké styly. Pak už jsou tam dvě funkce - jedna /userMessage, která přijme otázku uživatele a zavolá jazykový model, který vygeneruje HTML kód pro HTMX. Druhá funkce /process slouží pro situace, kdy uživatel na něco v tom AI UI klikne.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
from fasthtml.common import Form, Input, Button, Div, P, Title, Head, Meta, Link, Body, fast_app, serve, Style, Span
from openai import AzureOpenAI
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
from dotenv import load_dotenv
import os
from jinja2 import Template
import logging
# Configure logging
logging.basicConfig(level=logging.WARNING)
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
# Define the FastHTML app
app, rt = fast_app()
# --- Globals for session storage (simplified) ---
latest_user_question = None
latest_ai_snippet = None
# --- End Globals ---
# Load environment variables from .env file
load_dotenv()
# Get Azure OpenAI endpoint and model name from environment variables
AZURE_OPENAI_ENDPOINT = os.getenv("AZURE_OPENAI_ENDPOINT")
MODEL_NAME = os.getenv("MODEL_NAME")
# Set up Azure AD token provider for authentication
token_provider = get_bearer_token_provider(
DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default"
)
# Initialize Azure OpenAI client
client = AzureOpenAI(
azure_endpoint = AZURE_OPENAI_ENDPOINT,
azure_ad_token_provider=token_provider,
api_version="2025-04-01-preview"
)
@rt('/')
def get():
# Main container for the chat interface
chat_container = Div(
# Large element for AI output
Div(id='ai-output', cls='border p-4 min-h-[200px] bg-gray-100 rounded', innerHTML=P('AI responses will appear here.')),
# Form for user input
Form(
Input(id='user_query', name='user_query', type='text', placeholder='Enter your question here...', cls='border p-2 flex-grow rounded'),
Button(
Span('Send', cls='btn-text-label'),
Span(cls='spinner-graphic'),
id='send-button',
type='submit',
cls='bg-blue-500 text-white p-2 rounded ml-2 flex items-center justify-center relative w-[100px] h-[40px]'
),
hx_post='/userMessage',
hx_target='#ai-output',
hx_swap='innerHTML', # Replace the content of ai-output
hx_indicator='#send-button', # Indicator is now the button itself
cls='flex mt-4'
),
cls='container mx-auto p-4'
)
# Basic styling using Tailwind CSS CDN
return Title('FastHTML LLM Chat'), \
Head(
Meta(charset='UTF-8'),
Link(rel='stylesheet', href='https://cdn.jsdelivr.net/npm/tailwindcss@2.2.19/dist/tailwind.min.css'),
Style('''
@keyframes spin {
to { transform: rotate(360deg); }
}
/* Styles for the spinner graphic itself */
.spinner-graphic {
display: none; /* Initially hidden */
width: 20px; /* Spinner size for button */
height: 20px;
border: 3px solid rgba(255, 255, 255, 0.3); /* Lighter border for on-button */
border-top-color: #ffffff; /* White spinner on blue button */
border-radius: 50%;
animation: spin 0.8s linear infinite;
}
/* When the button (acting as indicator) is in htmx-request state */
#send-button.htmx-request .btn-text-label {
display: none; /* Hide text when request is active */
}
#send-button.htmx-request .spinner-graphic {
display: inline-block; /* Show spinner */
}
''')
), \
Body(chat_container)
@rt('/userMessage')
def post(user_query: str):
global latest_user_question, latest_ai_snippet # Allow modification of globals
logger.info('POST /userMessage started')
# Load system_message template from file
with open('prompts/system.jinja2', encoding='utf-8') as f:
template = Template(f.read())
# For a new user message, there's no previously generated snippet in this direct interaction
system_message = template.render(previously_generated_snippet=None)
latest_user_question = user_query # Store the user question
messages = [
{"role": "system", "content": system_message},
{"role": "user", "content": user_query}
]
logger.info('Sending data to LLM')
# Call the Azure OpenAI model
response = client.responses.create(
model=MODEL_NAME,
input=messages,
reasoning={
"effort": "low", # optional: low | medium | high
"summary": "detailed", # auto | concise | detailed
},
)
logger.info('Received response from LLM')
logger.debug(f'LLM full response: {response}')
content_text = None
try:
for item in response.output:
if getattr(item, 'type', None) == 'message' and hasattr(item, 'content'):
content_text = item.content[0].text
break
except Exception as e:
logger.error(f'Could not extract content text from LLM response: {e}')
return 'Error: Could not extract content from LLM response.'
if not content_text:
logger.error('No message output found in LLM response')
return 'Error: No message output found in LLM response.'
latest_ai_snippet = content_text # Store the AI snippet
logger.debug(f'LLM response: {content_text}')
return content_text
@rt('/process')
def post(interaction_details: str | None = None): # Make interaction_details optional
global latest_user_question, latest_ai_snippet # Allow access and modification of globals
actual_interaction_details_for_prompt: str
if interaction_details is None:
# This case will be hit if the HTMX snippet doesn't send `interaction_details`
logger.warning("POST /process: 'interaction_details' was not provided by the client. Ensure HTMX snippets use hx-vals correctly.")
# Provide a default value for the prompt to avoid breaking the flow
actual_interaction_details_for_prompt = "User clicked an interactive element, but specific details were not captured."
logger.info(f'POST /process proceeding with placeholder interaction details: "{actual_interaction_details_for_prompt}"')
else:
logger.info(f'POST /process started with interaction: {interaction_details}')
actual_interaction_details_for_prompt = interaction_details
if not latest_user_question:
logger.error('Original user question not found in session.')
return '<div id="ai-output" class="border p-4 min-h-[200px] bg-red-100 rounded text-red-700">Error: Original question context lost. Please start a new conversation.</div>'
if not latest_ai_snippet:
logger.error('Previously generated AI snippet not found in session.')
# Potentially less critical, could try to recover or ask user to clarify
return '<div id="ai-output" class="border p-4 min-h-[200px] bg-yellow-100 rounded text-yellow-700">Warning: Previous AI response context lost. The AI might not fully understand the interaction.</div>'
# Load system_message template
with open('prompts/system.jinja2', encoding='utf-8') as f:
system_template = Template(f.read())
system_message = system_template.render(previously_generated_snippet=latest_ai_snippet)
# Load user_interaction_prompt template
with open('prompts/user_interaction_prompt.jinja2', encoding='utf-8') as f:
user_interaction_template = Template(f.read())
user_prompt_content = user_interaction_template.render(
original_user_question=latest_user_question,
interaction_details=actual_interaction_details_for_prompt # Use the potentially defaulted value
)
messages = [
{"role": "system", "content": system_message},
{"role": "user", "content": user_prompt_content}
]
logger.info('Sending data to LLM for /process')
try:
response = client.responses.create(
model=MODEL_NAME,
input=messages,
reasoning={
"effort": "low",
"summary": "detailed",
},
)
logger.info('Received response from LLM for /process')
logger.debug(f'LLM full response: {response}')
content_text = None
for item in response.output:
if getattr(item, 'type', None) == 'message' and hasattr(item, 'content'):
content_text = item.content[0].text
break
if not content_text:
logger.error('No message output found in LLM response for /process')
return '<div id="ai-output" class="border p-4 min-h-[200px] bg-red-100 rounded text-red-700">Error: No message output found in LLM response.</div>'
latest_ai_snippet = content_text # Update the latest AI snippet
logger.debug(f'LLM response for /process: {content_text}')
return content_text
except Exception as e:
logger.error(f'Error during LLM call in /process: {e}')
return f'<div id="ai-output" class="border p-4 min-h-[200px] bg-red-100 rounded text-red-700">Error processing your request: {str(e)}</div>'
logger.info('Starting FastHTML app')
serve()
Podívejme se na systémový prompt. Popisuji v něm zejména jaké HTMX atributy tam potřebujeme, aby fungovala animace při čekání na odpověď LLM, aby do interaktivních komponent dal správnou funkci (/process) a směroval její výsledek do správného elemetu (#ai-output). Pokud už existuje vygenerovaný HTMX kód z předchozí interakce, tak jej tady vložíme tak jak je a také původní otázku uživatele.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# ROLE
You are a helpful assistant that provides answers user question in fun, rich and interactive way by responding with HTMX code snippets.
# INSTRUCTIONS
- You will be provided with a question from the user.
- You will respond with a HTMX code snippet that can be used to create an interactive element on a web page.
- The HTMX code snippet should be designed to be fun and engaging, encouraging user interaction.
- All interactive elements such as buttons, forms or images that can be interacted with must be pointed to /process endpoint.
- Remember to make it interactive and point any actions to the /process endpoint, including relevant details of the new interaction using hx-vals with the key `interaction_details`.
- For any interactive elements (like buttons) that trigger a POST request to the `/process` endpoint, you MUST include the attribute `hx-indicator='#send-button'`. This will activate the loading spinner on the main 'Send' button during processing.
- Use proper HTMX attributes to ensure the interaction is smooth and user-friendly.
- Ensure all buttons in the HTMX snippet have distinct background colors that contrast well with the page background to ensure visibility.
- Feel free to use emojis to make the content more engaging and visually appealing.
- The HTMX code snippet should be self-contained and should not require any additional context or explanation.
- Use the `hx-target` attribute to point it to '#ai-output'
- You output MUST be a valid HTMX code snippet. No other text, no explanation or no tags such as triple backticks should be included.
- Make sure response is rich in content and visually appealing. Avoid using just "click here to learn more" without any context.
- Use a variety of HTML elements to create a visually appealing and engaging response.
- Using images from remote URLs is not allowed in order to prevent dead links. Make sure to use only icons from well known frameworks.
# Example strategies
- Make it a quiz with multiple choice answers guiding user to the right answer
- Create a fun fact generator with buttons to reveal different facts
- Use icons and buttons to create an interactive gallery
- Create a mini-game or puzzle that the user can interact with
{% if previously_generated_snippet %}
# PREVIOUSLY GENERATED SNIPPET
The user was previously shown the following HTMX snippet, which you generated:
'''html
{{ previously_generated_snippet }}
'''
They have now interacted with it. Please generate a new HTMX snippet based on their interaction and the original query.
{% endif %}
Uživatelský prompt používám pouze když už dochází k interakci s UI. To zásadní v něm je, že se do něj dá to, co UI posílá - tedy například informaci o tom, na které tlačítko uživatel kliknul. To pak LLM použije při generování HTML kódu, aby vědělo, co uživatel udělal a mohlo na to reagovat.
1
2
3
4
5
6
7
8
9
10
The user's original question was: "{{ original_user_question }}"
You previously generated an interactive HTMX snippet. The user interacted with this snippet.
Details of the interaction: "{{ interaction_details }}"
Based on this interaction and the original question, please generate a new, engaging HTMX snippet.
This new snippet should continue the conversation, offer more details, or guide the user further.
Remember to make it interactive and point any actions to the /process endpoint, including relevant details of the new interaction using hx-vals with the key `interaction_details`.
Target your response to '#ai-output'.
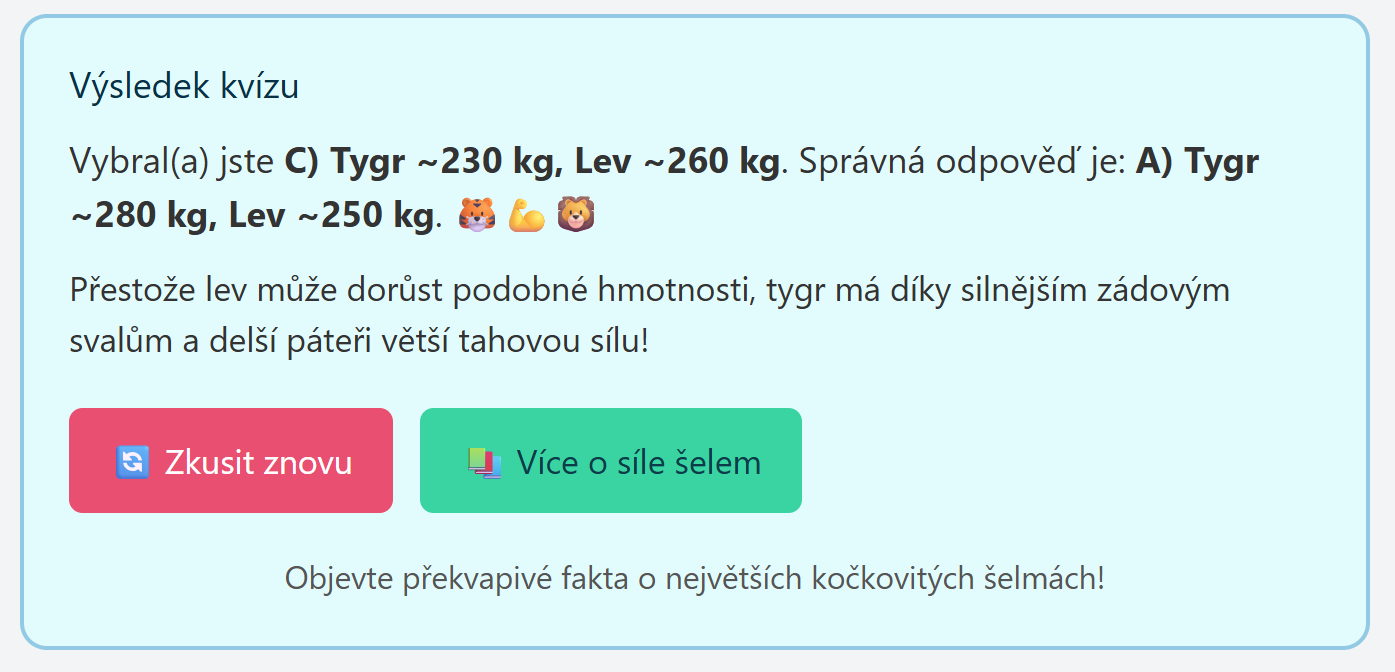
Pár výsledků
Tady screenshoty z několika interakcí. Není to nějak zázračné, ale na druhou stranu je to příklad skutečně plně dynamicky vytvořeného UI ad-hoc pro každou otázku a pro každou interakci.

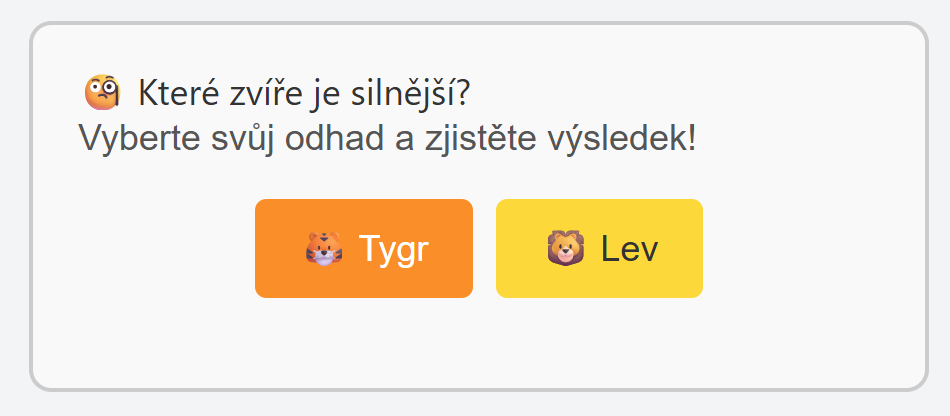
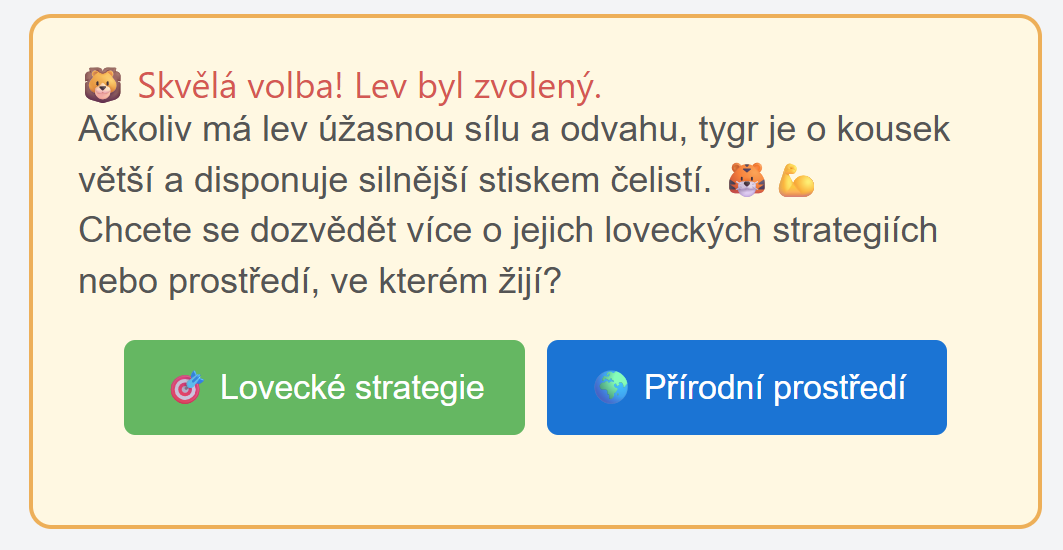
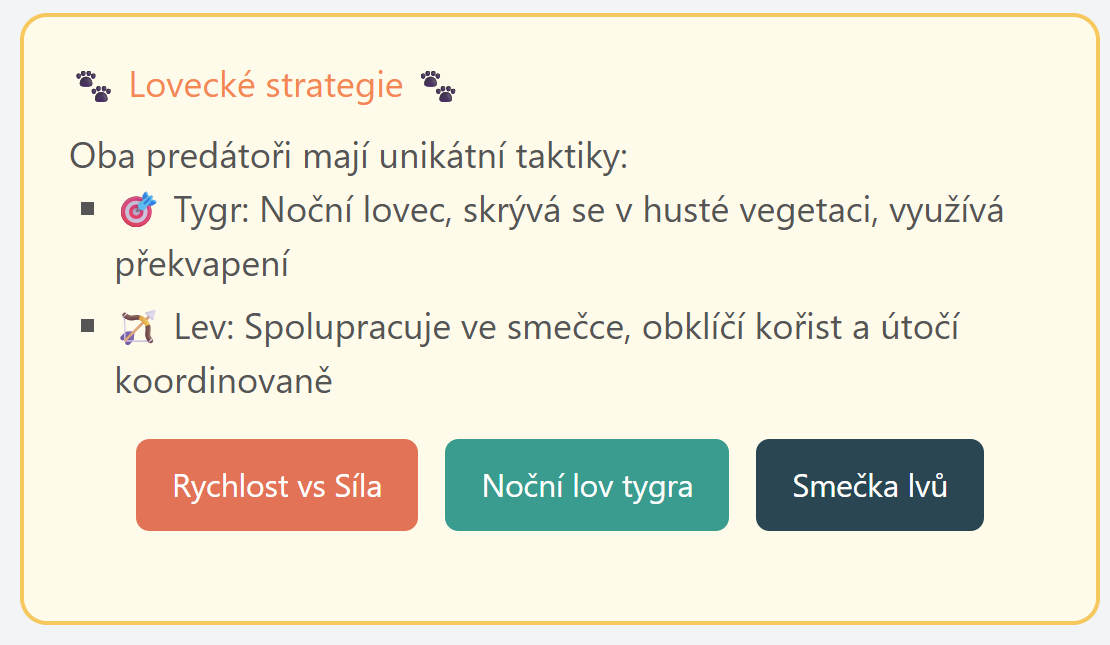
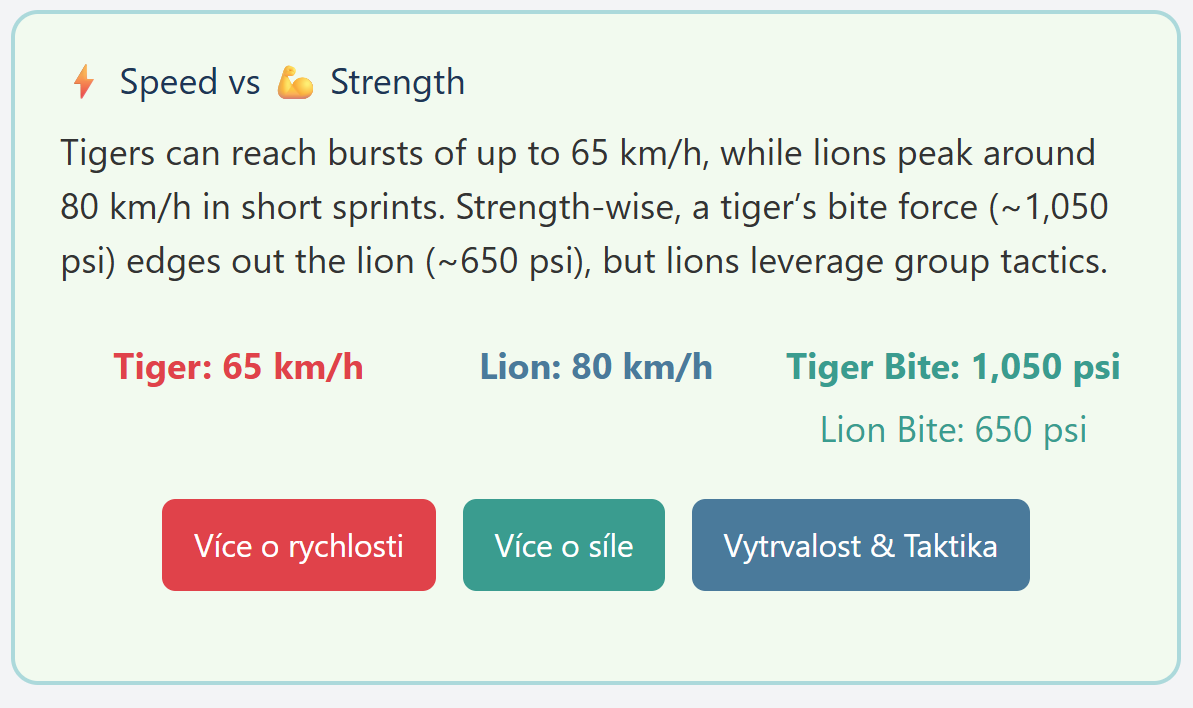


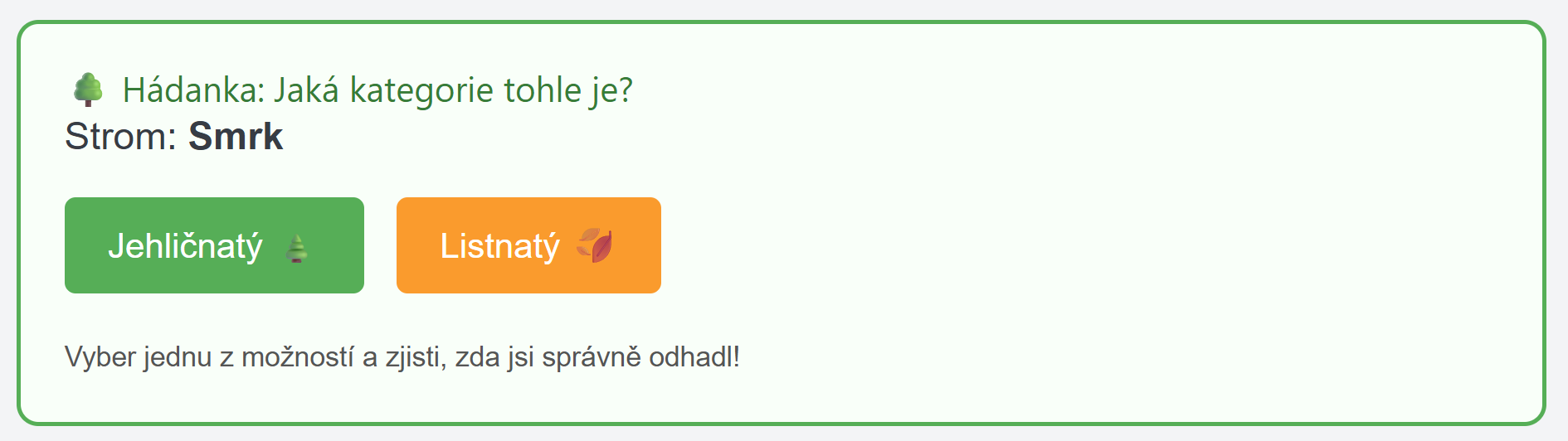
Nebo výuka stromů.

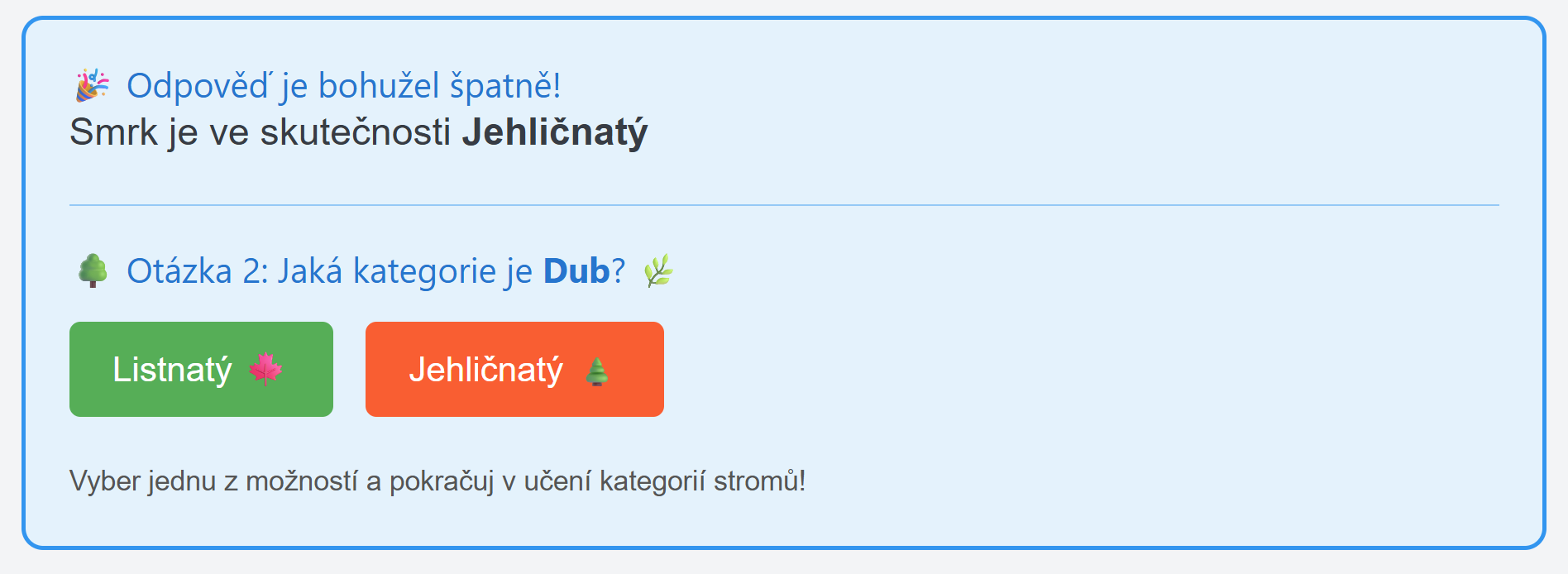
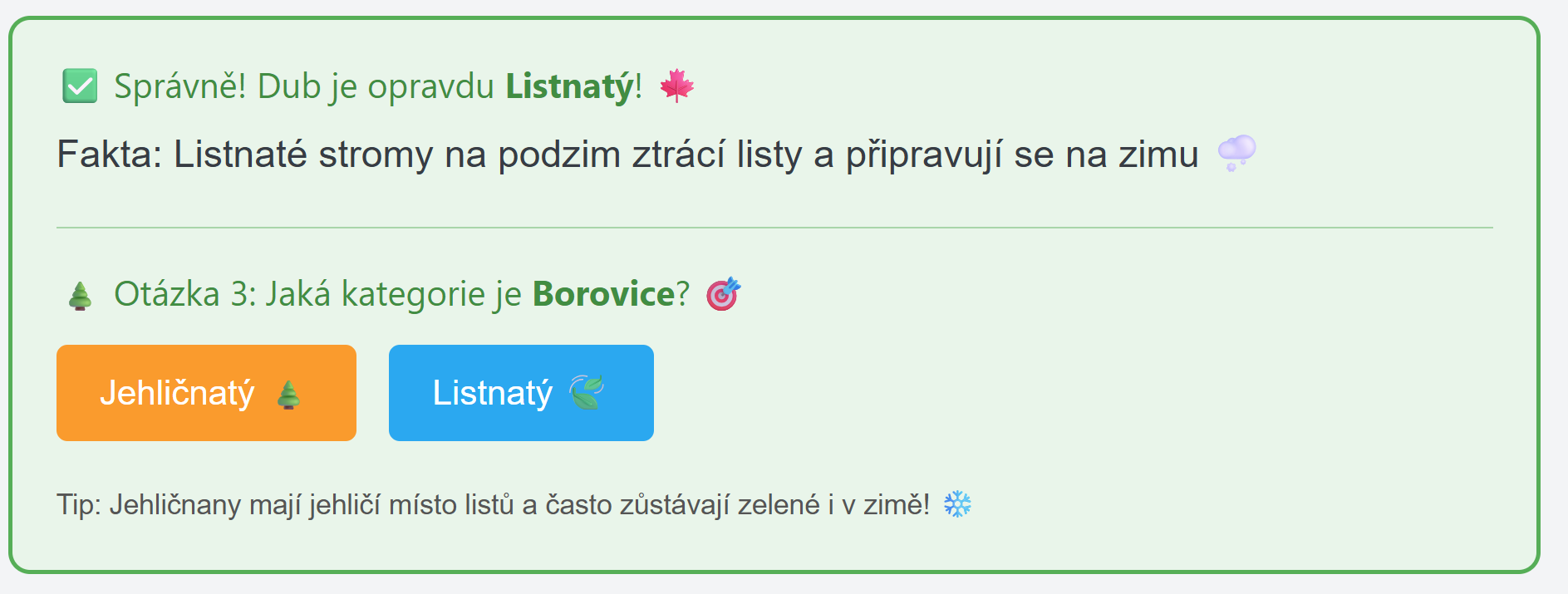

Závěr
Za mě je myšlenka UI vygenerovaného ad-hoc na základě předchozího chování uživatele nesmírně zajímavá. S tím, jak se budou vlastnosti AI rozvíjet a jeho reakce zrychlovat, stane se tohle běžnou součástí interakce s uživatelským rozhraním.