Jak potrápit reasoning AI? Co dát Člověče nezlob se?
Nové přemýšlecí AI modely jsou skvělé, ale jak je demonstrovat tak, aby to každý pochopil? Můžeme zkoušet složitá vědecká zadání nebo zapeklité úlohy v programovaní, které běžný model typu GPT-4o nezvládne. Jenže audience, která není z oboru (a tím myslím třeba, že je programátorem v konkrétním jazyce), je nezvládne taky. Potřeboval jsem najít něco, co si pamatujeme všichni a není problém to vyřešit. Velkou slabinou standardních modelů je velmi omezená schopnost simulace kroků s dodržením zadaných pravidel a tak i krátká sekvence Člověče nezlob se se může ukázat jako zásadní problém.
Tady je prompt, který jsem použil:
Ve hře Člověče nezlob se jsou následující pravidla:
- Pro nasazení figurky do hry musí hráč hodit 6 na kostce.
- Figurka se pohybuje po hrací ploše podle hodnoty na kostce.
- Pokud figurka skončí na poli, kde je již jiná figurka, tak tuto figurku vyhodí a ta se vrátí na start a musí být znova nasazena.
- Pokud hráč hodí 6, tak má nárok na další hod kostkou.
- V této zjednodušené hře má každý hráč pouze jednu figurku.
Tady jsou výsledky hodů kostkou pro jednotlivé hráče (červený začíná):
Červená - 4, 6, 3, 5, 6, 6, 1, 1, 6, 6, 6
Modrá - 2, 3, 3, 6, 6, 6, 5, 5, 2
Který hráč došel dál?
Jestli chcete, přestaňte teď číst a vyřešte si. Červený hráč je na tom ze začátku velmi dobře, ale modrý ho později vyhodí a tím se dostane dál.
Klasické modely
Žádný z klasických modelů, které jsem zkoušel to nedal - OpenAI, Anthropic ani Google. Potažmo Copilot M365, který v aktuální verzi stále běží na klasickém modelu, nezvládl situaci. Nicméně posun tam tedy rozhodně je zásadní, podívejme se na stařičký GPT-3.5 Turbo (ten co stál u zrodu ChatGPT), který se vlastně o nic nepokusil a pravidla naprosto nepochopil.
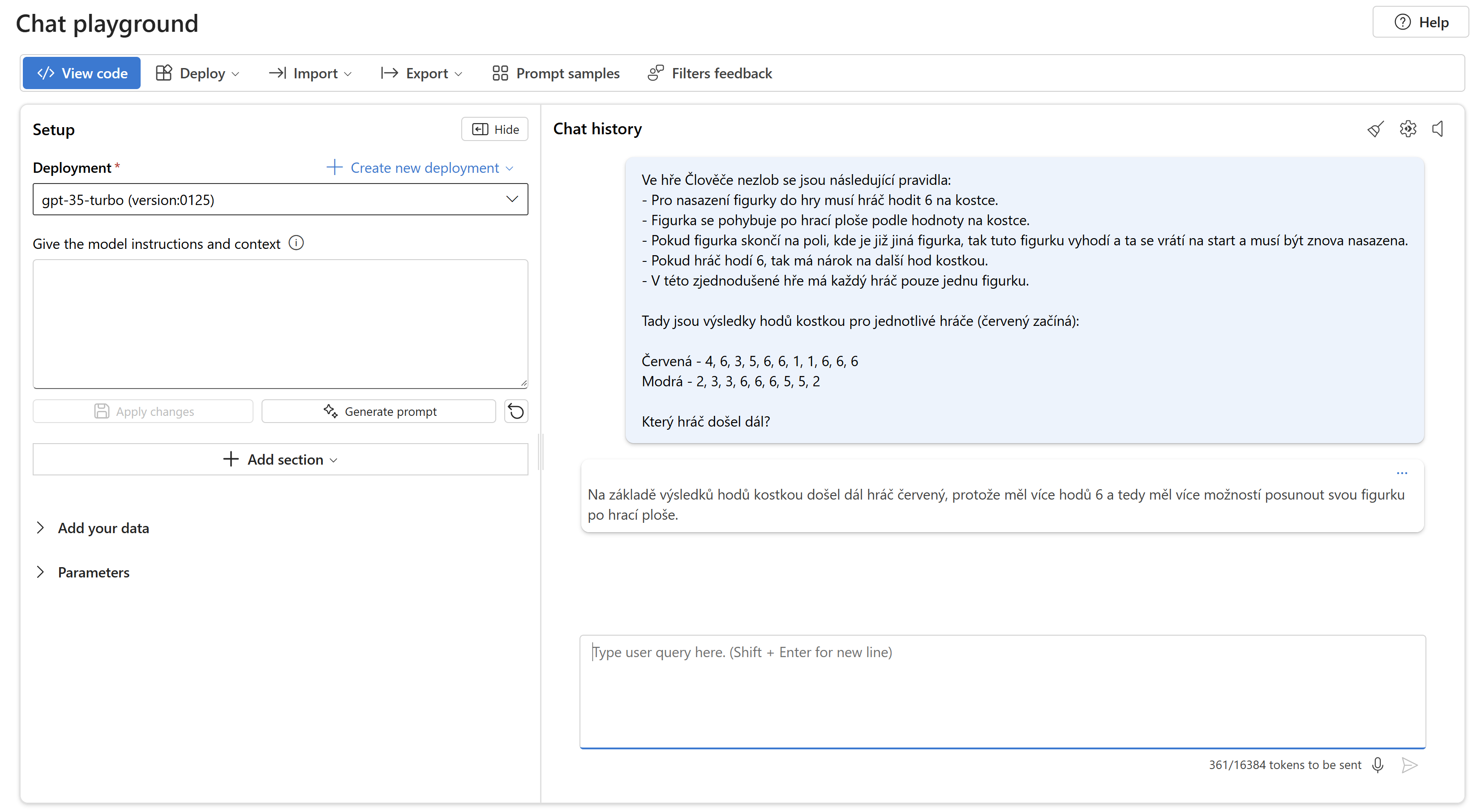
I po pošťouchnutí směrem k Chain of Thoughts to neudělá o moc lepší - pořadí zpřeházené, opakování hodu po šestce je velký problém, horko těžko zvládá problematiku nasazení figurky.
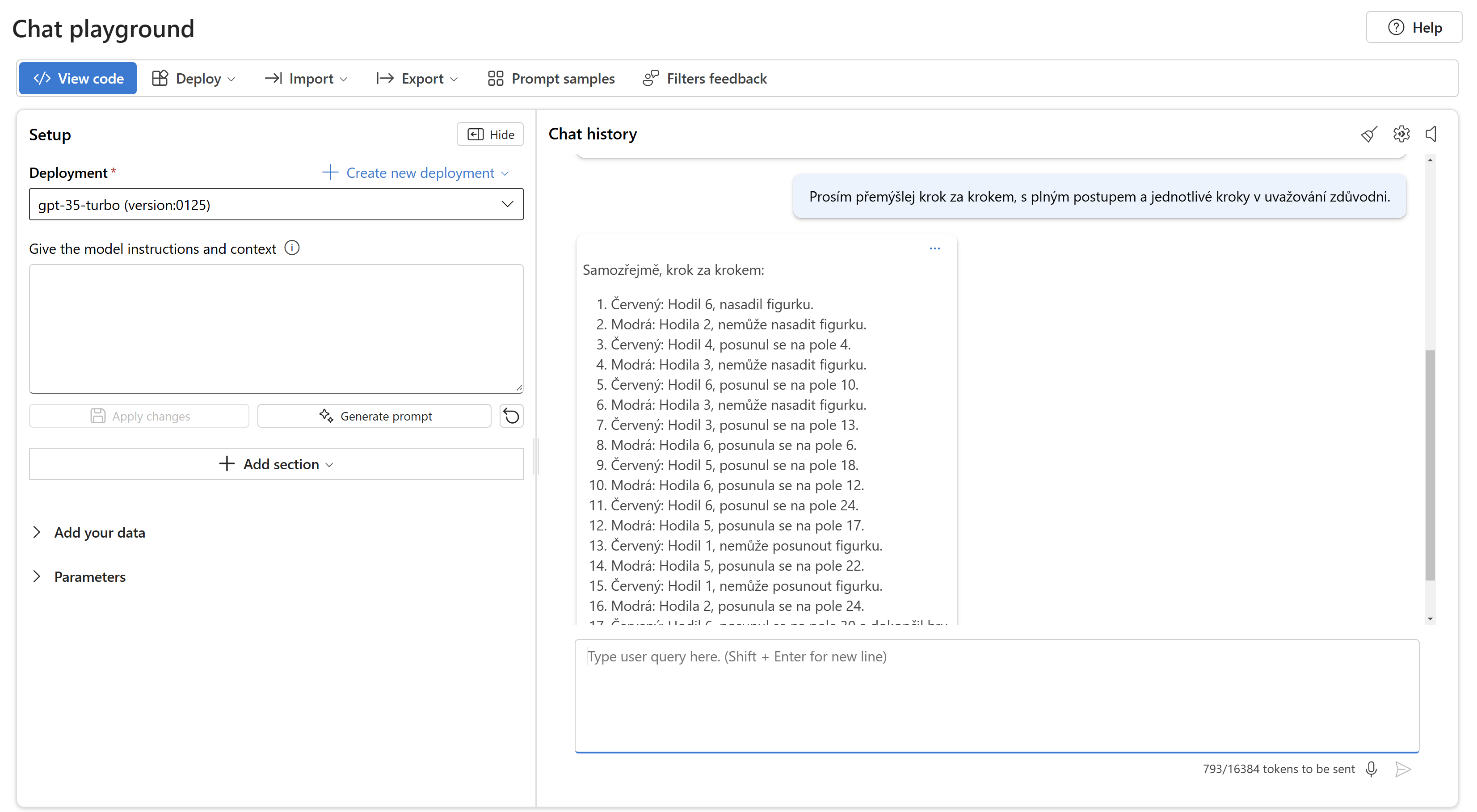
Tohle u moderních modelů nebyl problém. Potíž u nich je hlavně v tom, že si model propočítává tahy hráčů nezávisle na sobě, neuvědomuje si, že jeden hráč může ovlivnit druhého.
Takhle to nedal Anthropic Claude Sonet 3.5
Následuje rovněž neúspěšný Copilot M365 (stále používá GPT-4o)
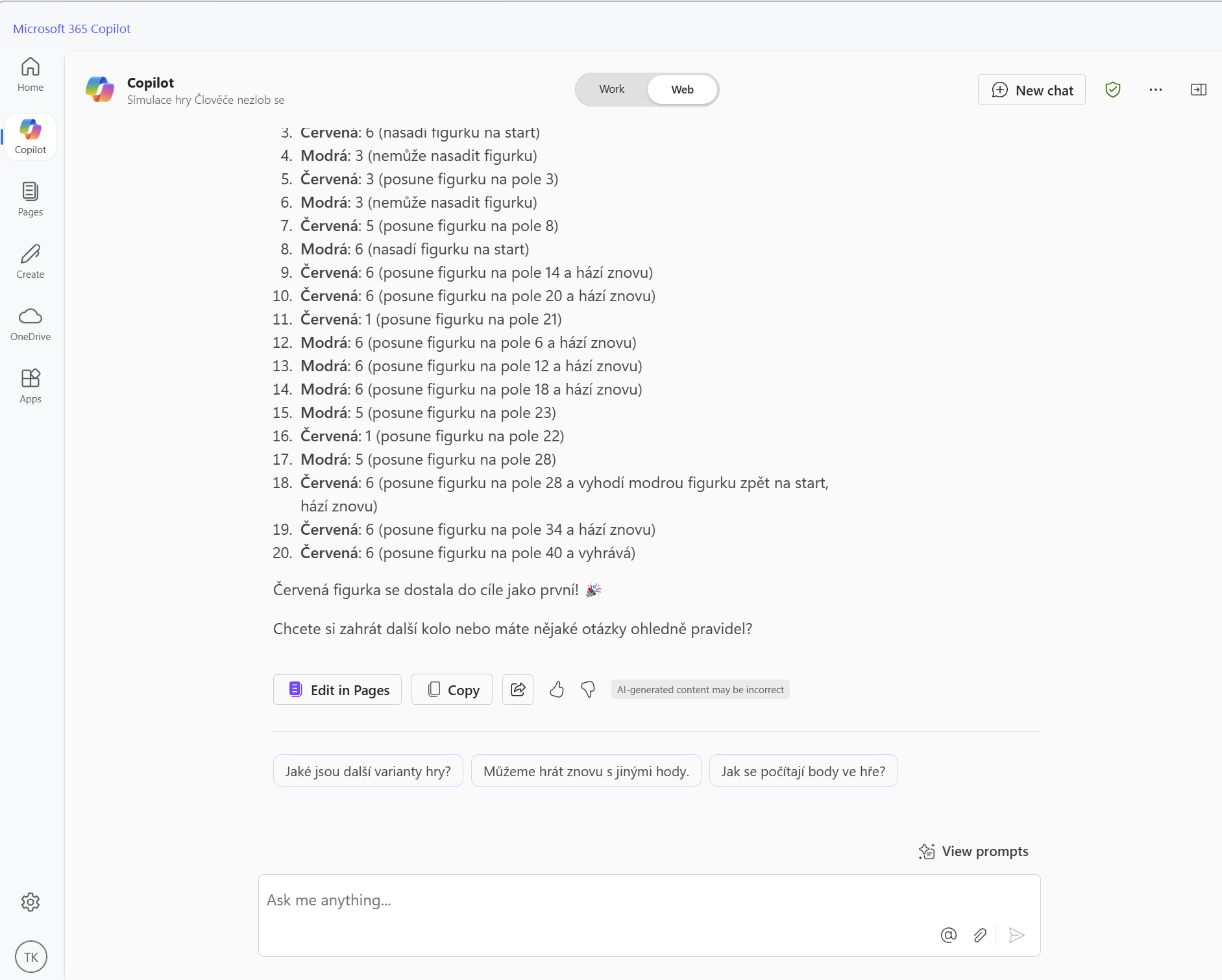
A samotné GPT-4o
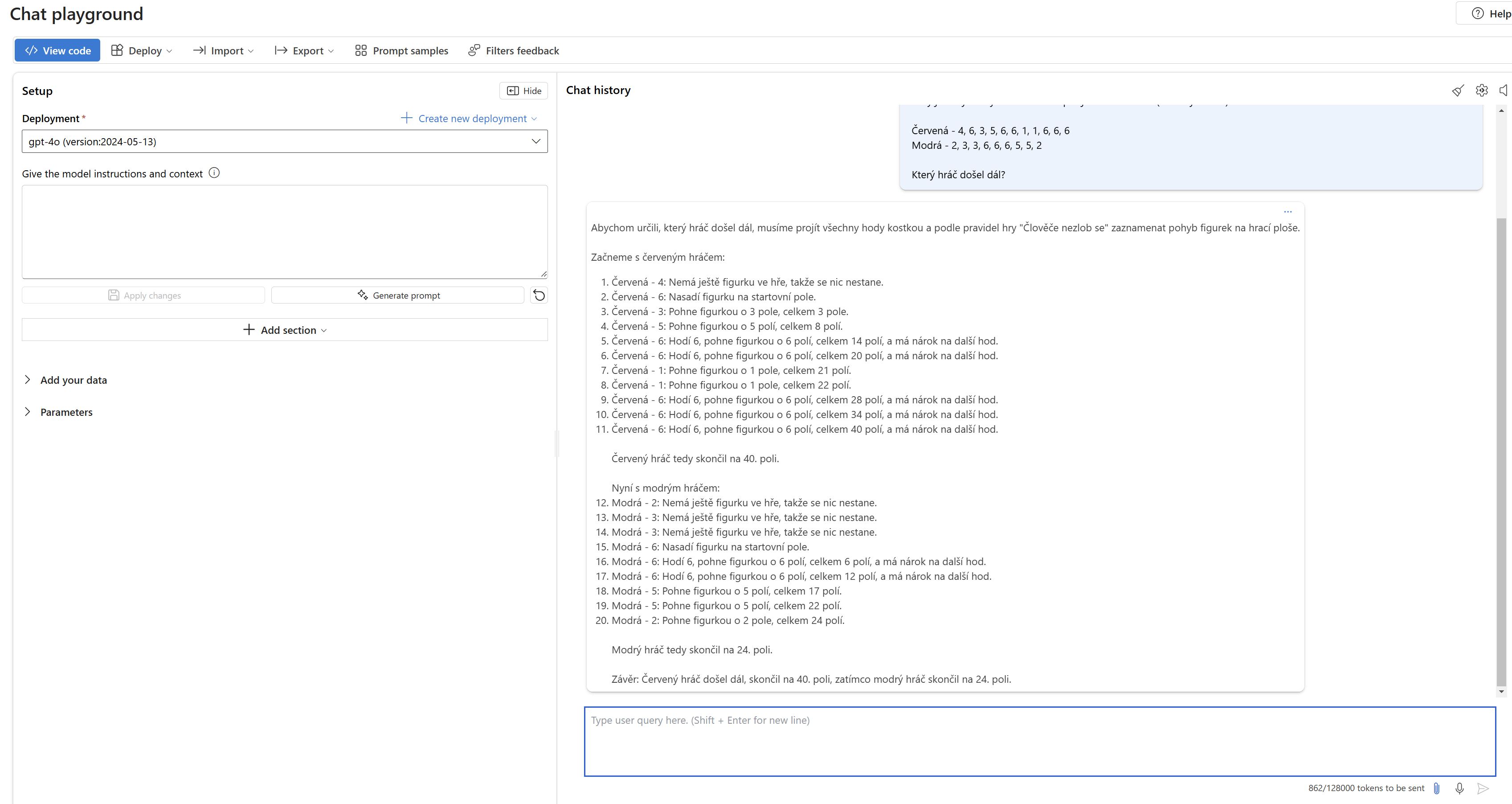
Co nejnovější Google Gemini 2.0 Flash? Kdepa.
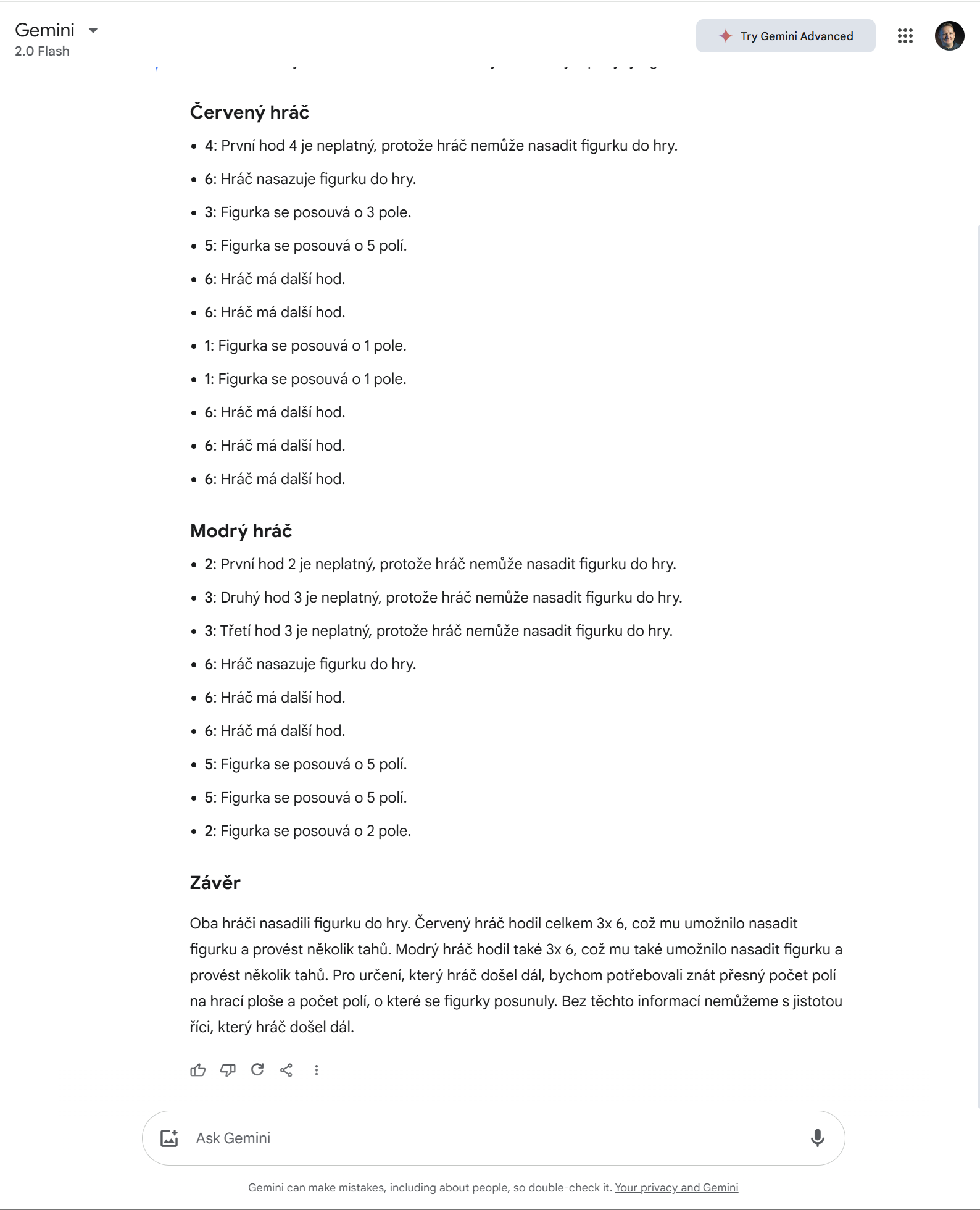
Možná tedy o trochu starší, ale chytřejší Gemini 1.5 Pro? Také ne.
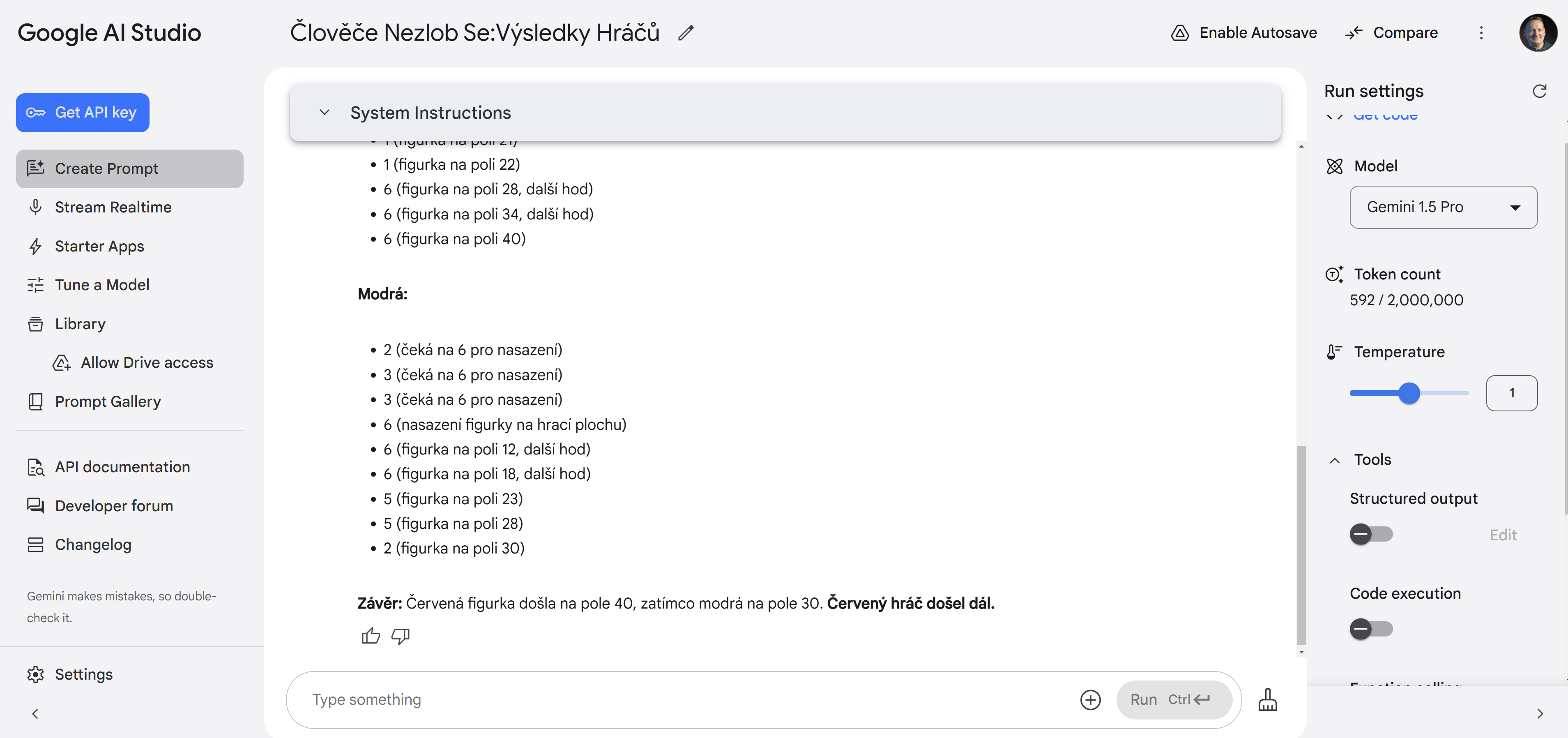
Říkám si - nepomohlo by, kdyby si to model mohl naprogramovat? Ne, nepomohlo.
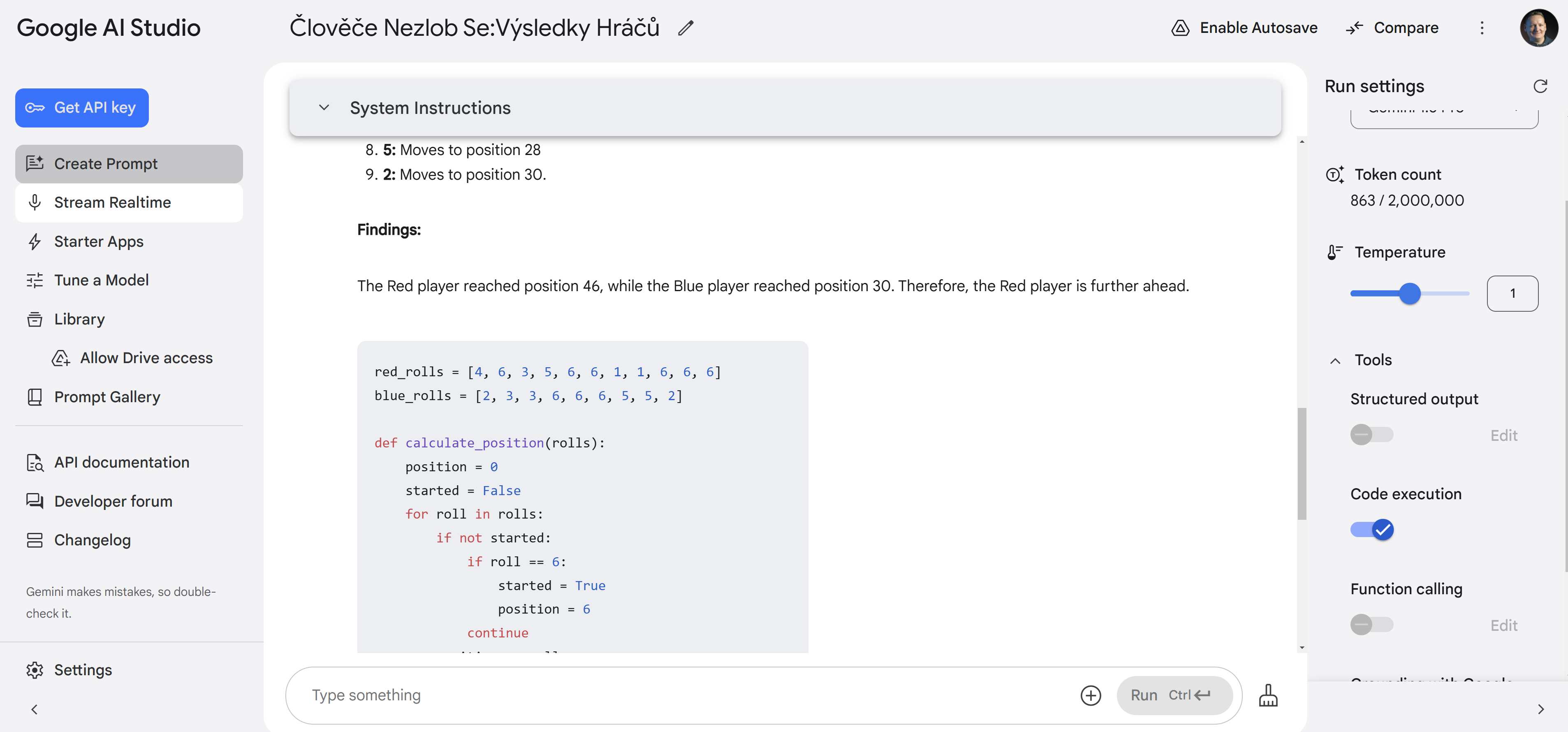
Dobře - z modelů, které jsem zkoušel, žádný nedokázal úlohu vyřešit. Čas se posunout k přemýšlecím modelům.
Reasoning modely
Reasoning modely fungují zjednodušeně řečeno tak, že mohou vést něco jako “vnitřní dialog”, tedy přemýšlet, a v průběhu toho hodnotit, které myšlenky jsou lepší a povedou k cíli. Model tedy provádí Reinforcement Learning, kde má v sobě schopnost generovat myšlenky a analyzovat vstupní informace (tak jak klasické modely popsané výše), ale také “hodnotící schopnost” sebe sama. Pokud vám to zní trochu jako multi-agent tak ano, to je způsob, jak vnést do generování textu možnost reflexe, hodnocení, specializace, nicméně tady je to funkce zabudovaná přímo v modelu, což je jednodušší a efektivnější pro generické situace. Dá se předpokládat, že o3 má v sobě Mixture of Experts, takže pro zrychlení inferencingu dokáže aktivovat jen část synapsí, ale to se nedá srovnávat s plnými agenty, kteří mohou mít odlišné modely, nástroje, znalostní báze, takže o3 nutně nenahrazuje multi-agent. Ale o tom jindy.
Jak se to povede o1-mini? No, nedal to, ale o kousek, je vidět, že na to šel dobře.
Tak co zkusit další myslící model, nový Gemini 2.0 Flash Thinking? Ne.
A co o3-mini? Ano, ten se dobral správného výsledku!
Nový Microsoft Copilot má funkci Think Deeper, která je postavena právě na tomto modelu, a je to vidět. Odpověď je správně přesto, že je číselně jiná, než o3-mini - jde o to jestli políčko po nasazení má index 0 nebo 1, což v zadání neříkám. Ale to není pointa - podstatné je pochopit jak interagují figurky a že se vyhodí.
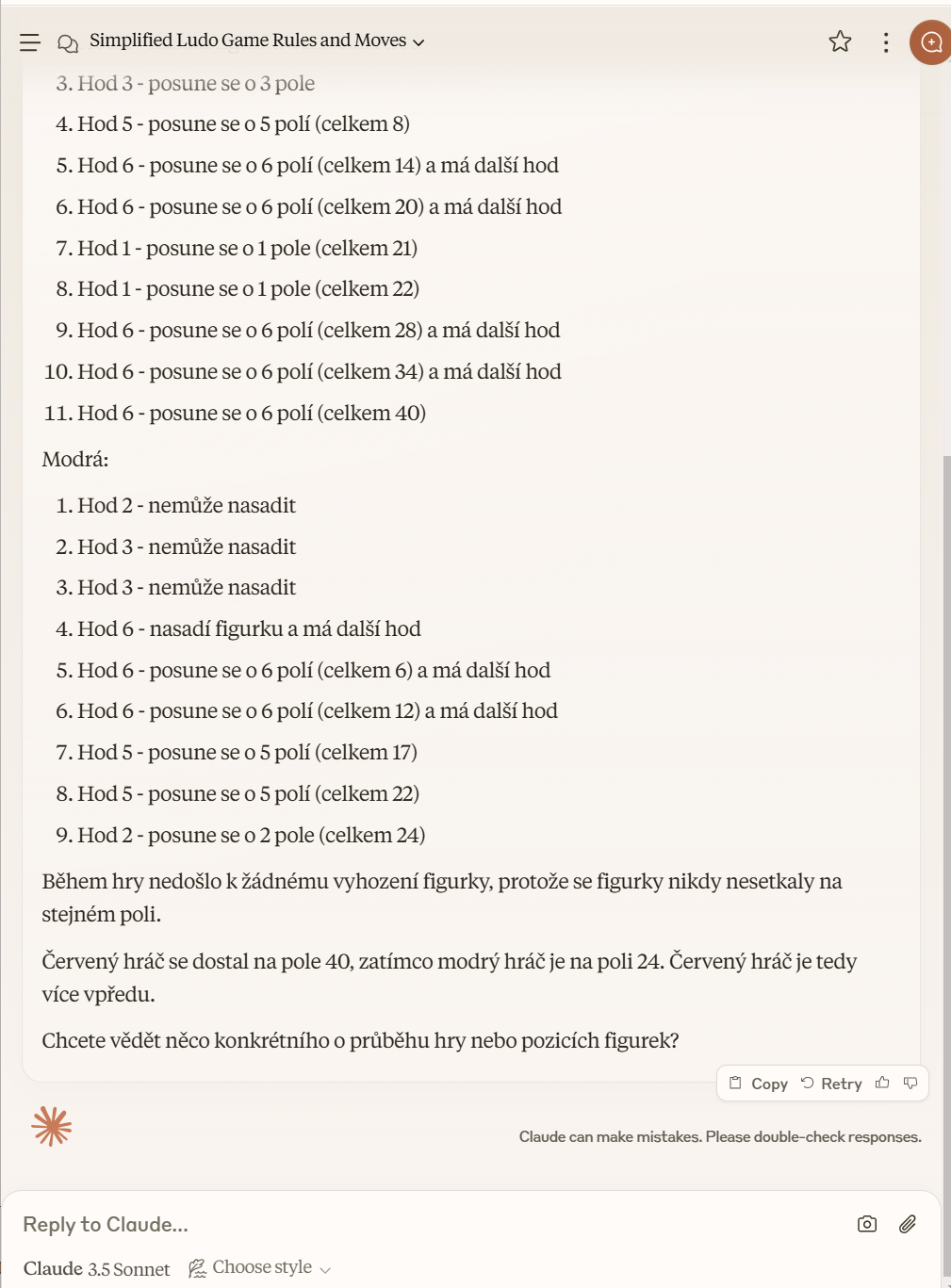
Co DeepSeek-R1? Zkoušel jsem, ale odpověď neznám. Mám v rámci AI Foundry u tohoto modelu omezené počty tokenů a přestože jsem to zkoušel několikrát, model to nikdy nestihl (přemýšlel a přemýšlel až vypršely tokeny). Nicméně tipuji, že na to rozhodně má, protože úvahy měl často velmi správné. To je na tomhle modelu fascinující - vidíte necenzurovaný výstup jeho přemýšlení.
Tak například - tady si model uvědomí, že nemůže počítat hráče izolovaně, protože se vzájemně ovlivňují vyhazováním.
Wait, no. Let’s not mix up deployment and movement. Each player needs to get a 6 to deploy their figurine. Until they roll a 6, they can’t move. Once they have deployed, they move on subsequent rolls.
…
The positions are calculated based on their own dice rolls, but if one player’s move would land on the other’s position, the other is sent back. But since each has only one piece, we need to track both players’ positions after each move to check for collisions.
But this might complicate things. Let me think.
But without knowing the order of turns, it’s hard to simulate interactions. Because if red moves and then blue moves, their positions could affect each other. But since the problem states each player’s sequence of rolls, perhaps we are to assume that each player’s sequence is their entire set of rolls in the order they occurred, taking into account consecutive rolls from 6s, but without considering the other player’s moves in between. But that seems unlikely, because in reality, turns alternate.
Wait, the problem might be… … But the problem’s lists are for each player: Red has 11 rolls, Blue has 9 rolls. So perhaps these are the exact sequences each player rolled during their respective turns, including extra rolls from 6s.
No ale vzápětí popře sám sebe a má myšlenku, že to možná není třeba.
But the answer may not require considering interactions between players (i.e., knocking each other out), since the question is just which went further. So even if their paths cross and they could knock each other out, perhaps the problem assumes they are on separate tracks or the positions aren’t affected by each other, so we can calculate each’s movement independently.
Takhle to jde tam a zpátky a je krásně vidět, jak s tím model bojuje. Je dost bolestivé na to koukat - je to něco jako když pomáhám synovi pochopit složitou úlohu na přijímačky, je mi jasné jak na to, a on se s tím pere a už už je na dobré cestě, aby z ní vzápětí sešel.
Každopádně předpokládám, že pokud budu mít dost tokenů, model to snad nějak dá. V této myšlence je vidět, že mu správně došlo, že dojde ke kolizi - to je důležité! Jenže má to celé o 6 posunuté, protože v tento moment mu nedochází. že 6 hozená pro nasazení figurky neznamená, že se figurka pohne o 6, ale že se nasadí a pohne se až příště.
Red’s position after being kicked: back to start (0). So after Blue’s move that puts Red back, Red’s turn comes. Let’s process:
After Blue moves to 28 by!jumpingover Red and kicking him back:
Blue’s position is 28, and Red is back to start.
Pokud jste jako já hledali něco, co dokáže AI pořádně zatopit, takže se oddělí zrno od plev, a přitom to všichni dobře známe a není to raketová věda, tak podle mě Člověče nezlob se je to, co jsme chtěli. Držení se pravidel a simulace, to jsou pro jazykové modely složité otázky. A to si vezměme, že až figurka obejde celé kolo, čeká ji cesta do domečku, kde nelze přeskakovat. Ufff, tak to už je moc, jak jsme to ve školce mohli dát?