Aplikační architektura škálovatelného AI chatu - asynchronní chat, zpracování i streamování
Typický začátek AI chatbota je nějaký monolit. Vezme se třeba frontend příjemný pro Python vývojáře (Gradio, Streamlit) nebo se napíše v Reactu, Vue.js či Svetle a k tomu backend, který přijímá dotazy uživatele, posílá je do LLM a streamuje odpovědi. Pro PoC výborné, jenže není to aplikační architektura vytvořená pro škálování. Výpadky spojení často končí chybou, stavový backend se rozbije nebo nestíhá a jeho škálování je podobné situacím, kdy se stará webová aplikace namigruje do cloudu a veškeré škálování je o spouštění další repliky, nicméně díky stavovosti její přidání neulehčí stávajícím uživatelským instancím, neumožní nenásilné seškálování zpět, neulehčuje průběžné nasazování nových verzí či různé formy chytrého směrování a shardingu z důvodů produktových (VIP vs. normální vs. free zákazník), regulatorních (datová rezidence nebo specifické instance podle typu regulatoriky), operačních (různé instance různých LLM modelů a poskytovatelů) a tak podobně. Zkrátka. Často mluvíme o cloud-native aplikacích, ale AI chaty stavíme jako klasické monolity. V této sérii se pokusím navrhnout škálovatelnější architekturu.
Celý projekt prostupně vzniká na mém GitHubu
Škálovatelná architektura AI chatu s mikroslužbami a asynchronním zpracováním
Když se podíváte pod kapotu všech AI chat aplikací velkých hráčů (OpenAI, Google, Microsoft, Anthropic), dají se najít společné rysy. Základem je rozdělit problém do samostatných komponent schopných nezávislého nasazování a škálování a stavovost buď zcela eliminovat nebo ji externalizovat. Hlavním principem je, že každý uživatel a každá jednotlivá zpráva je zpracovávána samostatně a nezávisle na ostatních a nepotřebuje tedy, aby byl uživatel směrován stále na tu stejnou instanci s využitím například cookie sticky session. Dokonce potenciálně i při výpadku spojení při streamování odpovědi na konkrétní dotaz by mělo být možné na klientovi spojení obnovit vůči jiné replice a zbylé tokeny dostat.
Tady je základní pohled na architekturu:
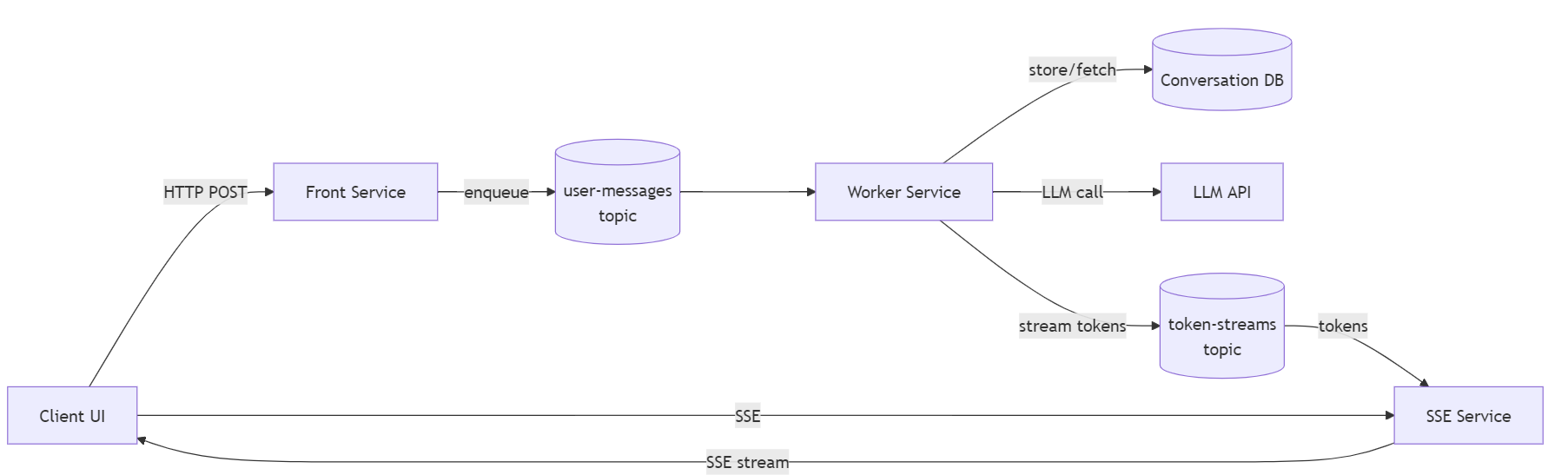
A tady je flow chart:
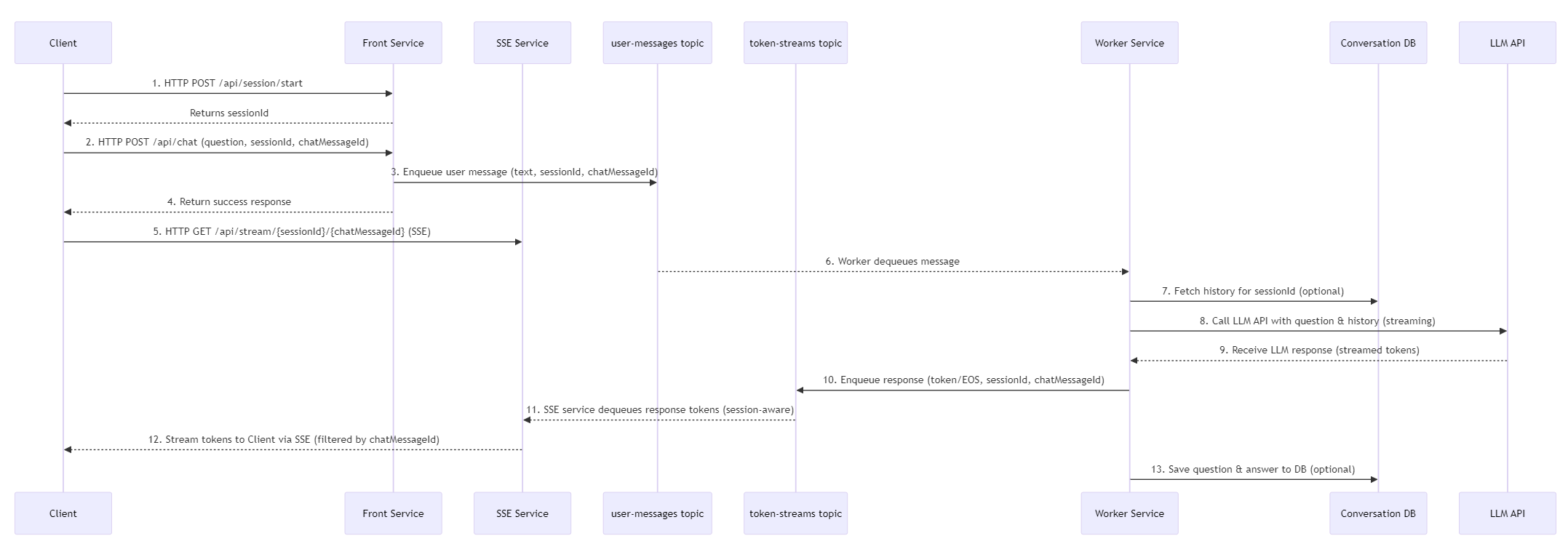
- Klient (jednoduchý webový frontend) si nejprve řekne ve Front Service o sessionId, což v příštích dílech spojíme i s nějakou autentizací a pamětí, ale o tom později.
- Jakmile uživatel něco napíše, odešle klient tuto zprávu na Front Service. Ta zprávu vezme a společné s ID session a ID zprávy ji pošle do fronty uživatelských zpráv (user-messages topic). V ten okamžik Front Service vrátí klientovi úspěšnou odpověď, že zpráva byla přijata a zpracovává se. Front Service tak nemá žádný stav v paměti a může horizontálně škálovat.
- Klient si na základě toho sestaví HTTP spojení na SSE službu. Ta je oddělená od ostatních a jejím cílem je držet spojení s klientem a posílat mu aktualizace, konkrétně jednotlivé kousky zpráv, tokeny nebo chunky, přes Server-Sent Events (SSE). Tady by šlo samozřejmě použít i WebSocket, ale v mém scénáři nepotřebujeme streamovat obousměrně, stačí od serveru. Je samozřejmě i varianta jít do SignalR, které je v Azure jako služba a jede na WebSocket s fallbackem na SSE, ale pro tenhle scénář si to chci vyřešit sám vlastní SSE službou. Tato SSE služba na základě messageId vytvoří spojení (session) do Service Bus Topic a kouká, jaké kusy textů se tam objevují (díky session principu má zaručené FIFO, takže nemusíme explicitně řešit pořadí zpráv - ale samozřejmě by to šlo) a ty streamuje přes SSE kanál do klienta. SSE služba má tedy spojení s klientem, nicméně to je použito pouze pro stream konkrétní zprávy, nikoli celé konverzace, takže každá další zpráva může být vyzvednuta z jiné instance (případně v okamžiku výpadku spojení lze toto navázat i s jinou instancí, protože neodeslané tokeny jsou stále v topicu). SSE služba má tak velmi nízkou stavovost, v podstatě jen z důvodu držení spojení pro streamování zpráv a s tím spojený menší overhead.
- LLM worker je služba, která nemá žádné synchronní API, ale čeká na zprávy v topicu uživatelských zpráv. Jakmile nějakou zprávu vyzvedne, vezme si ID session a ID zprávy a může si z databáze vyzvednout historii konverzace (to tam ještě nemám, paměť bude předmětem příštího článku). Poté zavolá LLM API s dotazem a historií a začne streamovat tokeny do topicu token-streams (LLM streamuje do workeru a ten do topicu). Stavovost je tedy opět minimální na úrovni zpracování jedné konkrétní zprávy. Pokud by došlo k havárii workeru v půlce odpovědi, worker nepotvrdí plné zpracování původní zprávy z topicu user-messages a ta se znovu zpracuje, takže nedojde k žádné ztrátě dat. Nicméně aktuálně by v implementaci klient dostal půl odpovědi a pak znovu odpověď celou. To by samozřejmě šlo vyřešit tak, že worker pošle speciální zprávu na začátek a pokud klient dostane nový identifikátor začátku, tak předchozí nedokončenou odpověď smaže z obrazovky a začne znovu. Nicméně havárie workeru bude poměrně vzácná. Všimněte si, že pro plánované terminace, tedy scale down, je v kódu workeru explicitně ošetřena logika reakce na SIGTERM (Azure Contaienr Apps signalizují, že se bude končit) tak, že worker už nebere nové zakázky, ale ty stávající dokončí a poté se ukončí. Worker tedy může být škálován nahoru i dolů nejen bez ztráty dat, ale i bez zbytečných duplicit nebo prodlev.
Vzali jsme tedy monolitickou aplikaci a rozmontovali na samostatně nasaditelné součástky což nám umožní nezávislé škálování, nezávislý vývoj, testování a nasazování a výbornou robustnost, schopnost oklepat se z různých výpadků a problémů.
Taková architektura nám dala i další zajímavé možnosti. Můžeme poměrně jednoduše implementovat různé formy chytrého směrování a shardingu.
- A/B testing a progressive delivery - dokážeme třeba jednoho workera nasadit v nové verzi a zkoumat jeho chování přímo v produkci bez nutnosti přesměrování celého provozu.
- Máme dobrou přípravu na active/active celoplanetární nasazení celého řešení přes různé regiony a kontinenty (fronty nebo cache jsou per-region state, CosmosDB je globální, ale eventuálně konzistentní state).
- Můžeme mít různé workery pro různé LLM modely a podle toho, jaký model si uživatel vybere, tak ho směrovat na jinou instanci třeba na základě nějakých metadat v hlavičce zprávy. Jakmile v příštím článku přidáme paměť, tak nebude problém začít konverzaci na jednom modelu a pokračovat v ní v jiném, protože každou zprávu řešíme zvlášť a každou si tak může vzít jiný worker podle toho, co má uživatel zrovna nastaveno.
- Podobně můžeme s workery šachovat co do geografické dostupnosti LLM modelů nebo je použít k balancování či segregaci.
- Můžeme mít také různé kategorie či kvality workerů, například nějaké běžící v secure enklávě (confidential computing) nebo nějaké “spotové” pro free tier naší služby apod.
- Celé řešení může efektivně škálovat i do nuly, takže pro vývoj a testování můžeme ušetřit tím, že se všechno samo uspí i samo probere.
- Service Bus sloužící pro integraci může běžet v cloudu a přitom dokážeme workery spouštět kdekoli. Můžeme si tedy představit i situaci, kdy si zákazník spustí worker třeba u sebe. Samozřejmě když jsou fronty i celá appka a LLM v cloudu, tak to nemusí dávat příliš velký smysl, ale distribuovaná architektura všechny tehle varianty umožňuje. Každá komponenta je nezávislá a může být kdekoli.
Použité Azure zdroje:
Takhle aplikace vypadá v prohlížeči:
Co bych chtěl v této sérii řešit?
- Základní architektura s asynchronním zpracováním a streamováním
- Paměť konverzací a dlouhodobá paměť ve jménu uživatele
- Observabilita a monitoring
- Autentizace a autorizace uživatelů
- Popis praktického postupu s GitHub Copilotem (od architektury ke kódu a ne naopak)
- Perf testy
- Chaos engineering
- CI/CD pipeline
- A/B testing a progressive delivery
- Multi-region active/active deployment