Aplikační architektura škálovatelného AI chatu - historie a dlouhodobá paměť
V AI chat aplikaci bychom měli jednak udržovat historii konverzací, aby se k nim mohl uživatel vracet, ale také dlouhodobou paměť uživatele. Ta by měla jednak sloužit k zapamatování důležitých faktů o něm jako jsou jeho preference, zájmy a další věci co prozradí a druhak k udržování přehledu kdy a o čem se s AI bavil, aby na to bylo možné navázat v budoucnu nebo se na to odkázat v rámci konverzace. V tomto článku se podíváme, jak takovou paměť implementovat a jak ji integrovat do naší vysoce škálovatelné architektury.
Celý projekt prostupně vzniká na mém GitHubu
Historie
V rámci chatu potřebujeme udržovat historii ze dvou rozdílných důvodů.
Tím prvním je stav session, konverzace, protože aktuální rozhovor musí do LLM chodit celý a nechceme, aby tento stav byl svázaný s nějakou konkrétní instancí nějaké služby. Každá zpráva uživatele je řešena jako samostatný asynchronní process zpracování, což nám dává vysokou škálovatelnost, ale musíme si někde konverzaci pamatovat a natáhnout. Pro toto krátkodobé uložení potřebujeme něco rychlého a lokálního, použijeme tedy Redis. Až budeme mluvit o multi-region nasazení, tak tato komponenta bude lokální, tedy per-region. U této komponenty potřebujeme striktní konzistenci, aby se uživatelům chat nerozpadal, takže do Redis zapíše LLM worker zprávu synchronně. Tyto informace jsou důležité vlastně jen v průběhu konverzace a po krátkou dobu, kdy se z nich zpracovávají vzpomínky, takže time-to-live můžeme nastavit třeba na pár hodin nebo den.
Druhým je prezentace předchozích konverzací uživateli, aby si je mohl zpětně procházet a vracet se k nim. Tady už určitě nechceme zdržovat a eventuální konzistence s asynchronním zápisem do databáze je zcela v pořádku. Ať jsme připraveni na multi-region, tak určitě použijeme CosmosDB a získáme tak databázi, která je schopná globální replikace a eventuální konzistence přes celou planetu. Historické informace můžeme ukládat jen po nějakou omezenou dobu, třeba je nechat uživatelům přístupné jen 30 dní a následně je pravidelně mazat (třeba přes TTL v CosmosDB) nebo přesouvat do archivu v blob storage.
Konverzační paměť
Prvním typem paměti, který použijeme, je paměť konverzací. Jejím smyslem rozhodně není uchovávat veškeré texty, ale pouze extrakci ve formě základní sumarizace konverzace a klíčové atributy jako jsou sentiment, osoby, místa, témata a časové razítko. Tato paměť je následně opatřena embeddingem pro semantické vyhledávání v rámci CosmosDB. Konverzační paměť je LLM nabídnuta ve formě nástroje (function calling) a to se tak může samo rozhodnout když chce nahlédnout do historie. Hlavním smyslem je schopnost říct něco jako “jak jsme se bavili včera, tak tohle je podobné, ale…” nebo reagovat na otázky typu “minulý týden jsme mluvili o X, je to pořád aktuální?”.
Uživatelská paměť
Druhým typem paměti budou dlouhodobé informace o uživateli. V rámci zpráv bude AI asynchronně extrahovat klíčové informace v kategoriích jako jsou osobní preference, co chce od AI asistenta, znalosti, zájmy, co nemá rád, rodina a přátelé pracovní profil nebo cíle. V mé jednoduché implementaci se aktualizuje při každé zprávě (což je určitě zbytečné a nebyl by problém to dělat v dávkách), samozřejmě asynchronně a tak, že LLM má za úkol přidávat nové informace, pokud se objeví, ale také stávající konsolidovat. Na tom by šlo stavět dál, například mít u každé informace nějakou časovou značku kdy naposledy se potvrdila, abychom mohli implementovat zapomínání. To v mém prototypu není, ale smysl to dává.
Distribuovaná architektura paměti, asynchronní zpracování a mikroslužby
Tady je aktualizovaná celková architektura:
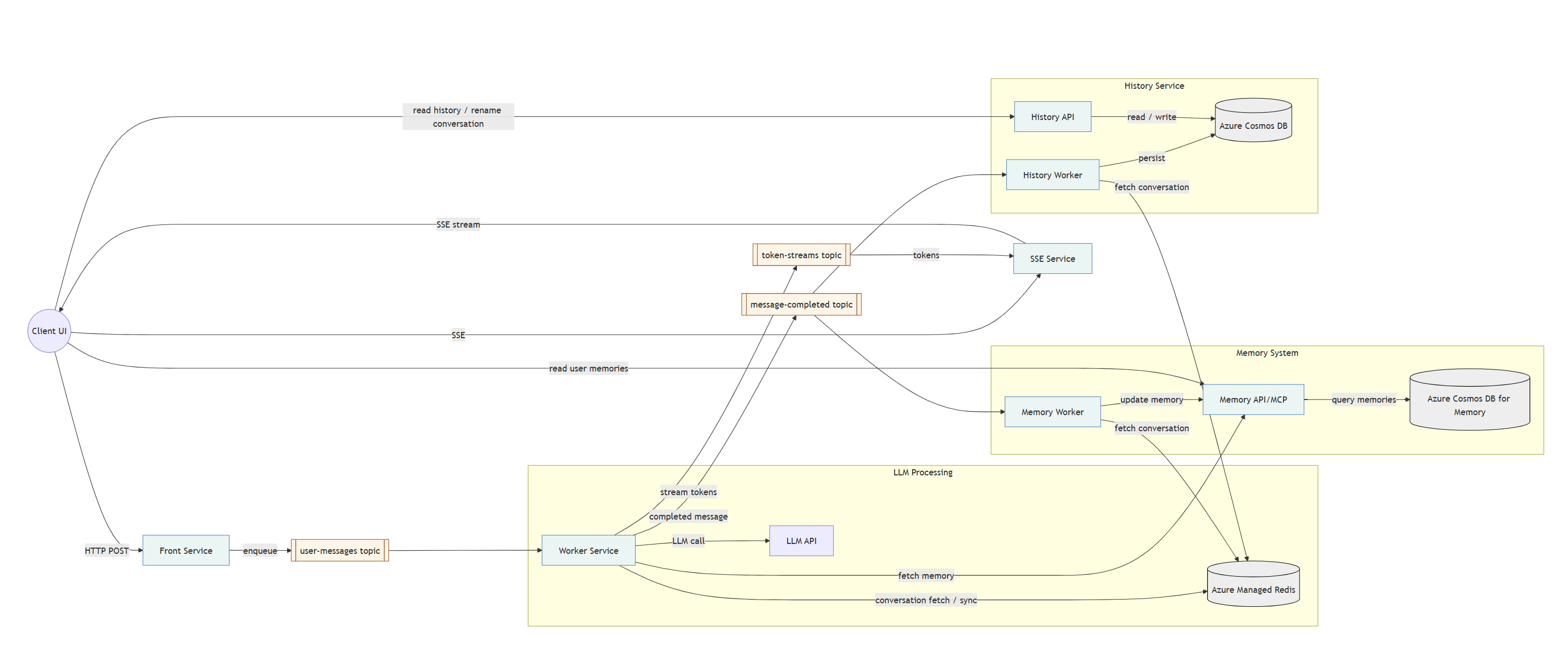
LLM worker nyní přistupuje do Redis pro vytažení stavu konverzace. Současně do Redis pro tuto informací chodí history worker a memory worker. Není to antipattern, nemají mít mikroslužby jasné vlastnictví dat a komunikovat přes API? Za normálních okolností ano, ale tady bychom vytvořili nepříjemné výkonnostní hrdlo bez zřejmého benefitu. Worker, jak jsme popsali minule, streamuje do topicu, z kterého potom SSE služba streamuje na klienta. Když je zpráva hotová, LLM worker updatuje historii konverzace v Redisu a to udělá synchronně - tohle potřebujeme mít najisto hotové. Následně vystřelí zprávu do topicu message-completed a tím má hotovo. Na tuto zprávu nezávisle na sobě reaguje history worker, který má za úkol updatovat historii v globální dlouhodobé databázi a také memory worker, který zahájí extrakci pro konverzační paměť a uživatelskou paměť.
LLM worker rovněž má k dispozici memory API (mohl by to být MCP server, ale pro jednoduchost je to zatím jednoduše API) jako function call, takže AI si může vytáhnout data z konverzační paměti. Zároveň si pro první zprávu konverzace (tam, kde dává system prompt) vytáhne dlouhodobou paměť uživatele a přidává ji do kontextu. V implementaci je toto jako “nice to have”, pokud paměť nebude odpovídat, jednoduše tam ty údaje v kontextu nebudou a jede se dál. Chat nemá přestat fungovat jen pro to, že zrovna nefunguje paměť.
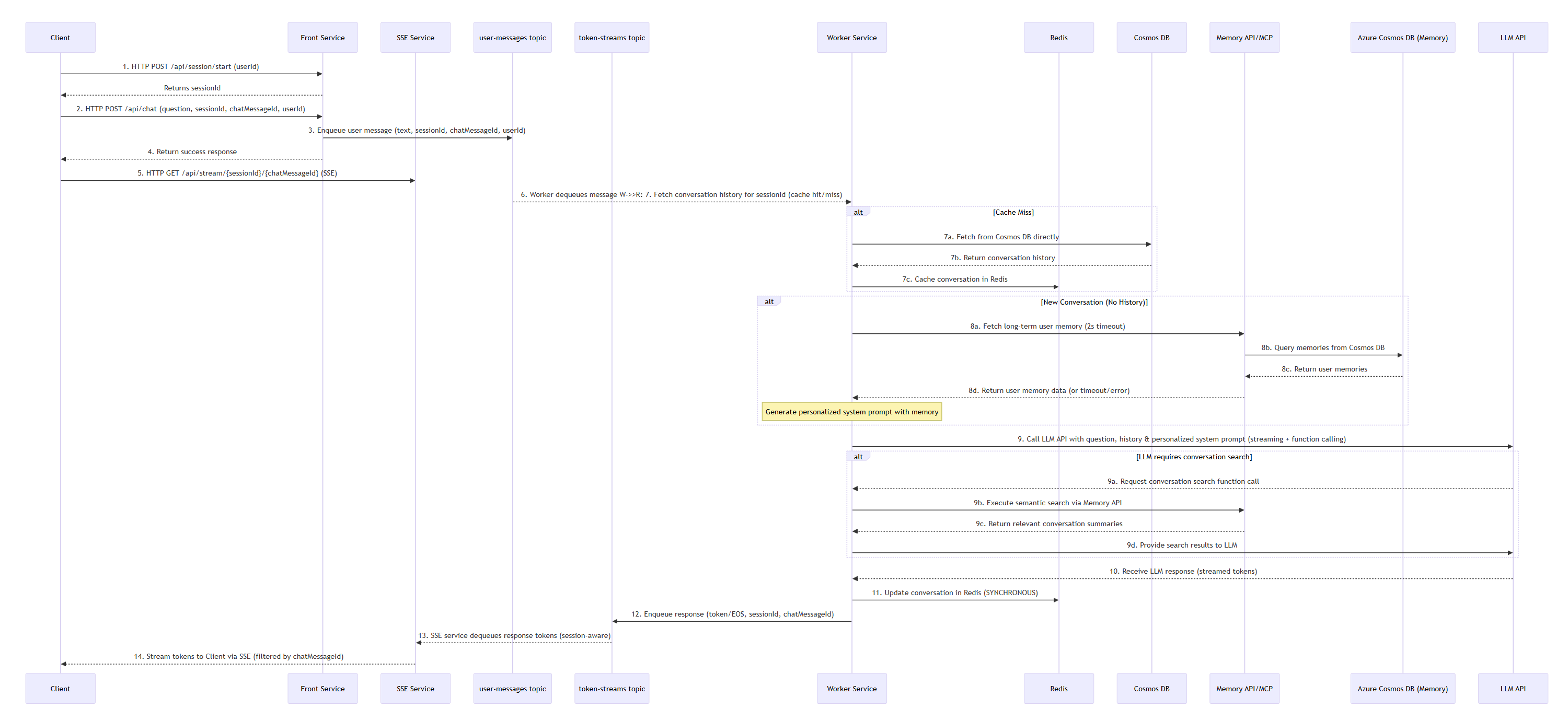
Sekvenční diagram požadavku uživatele:
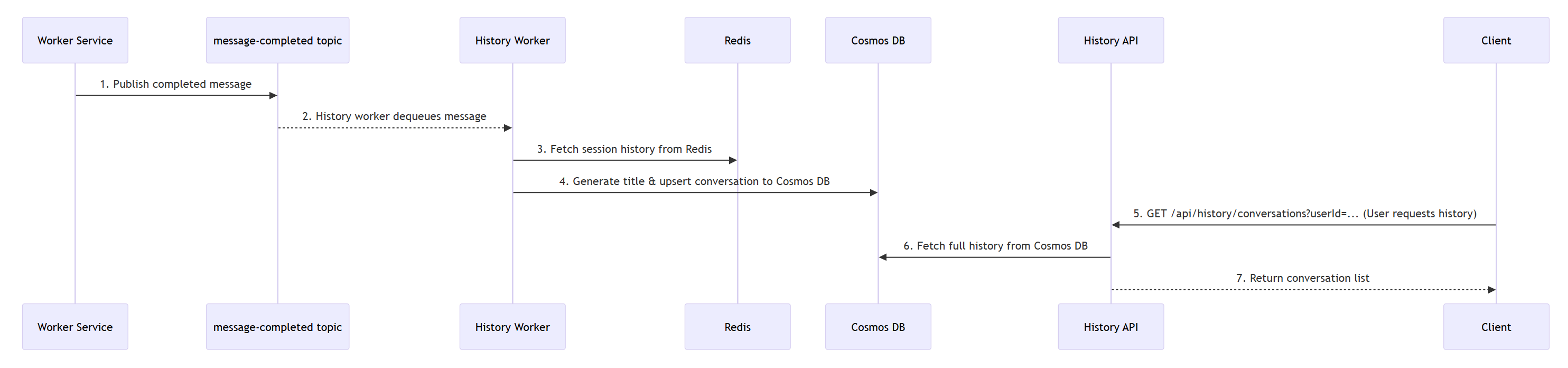
Tady je sekvenční diagram historie:
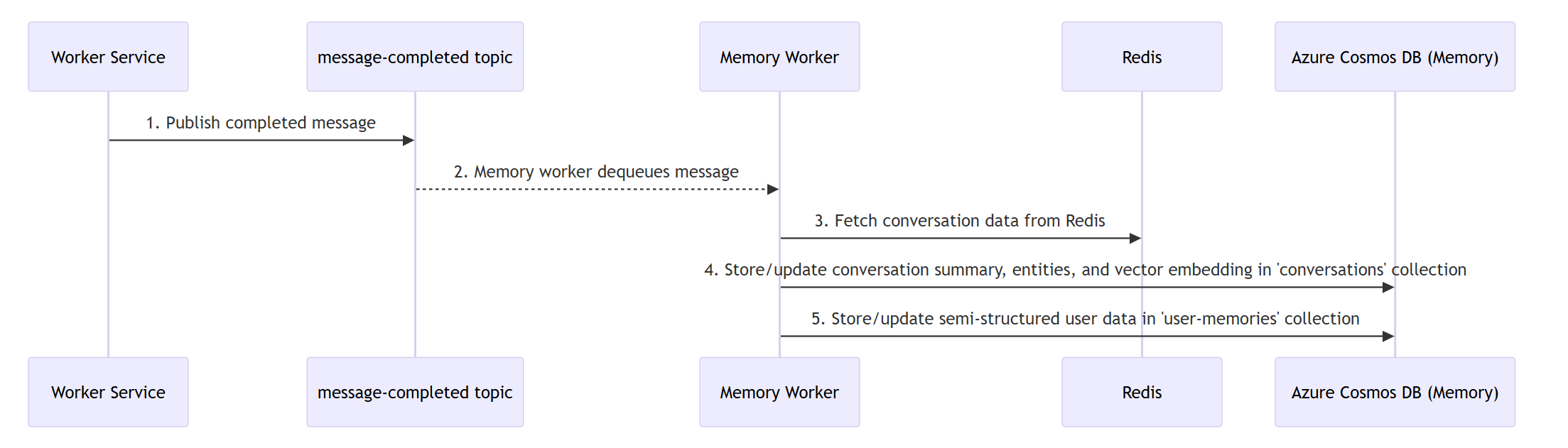
A také diagram paměťového systému:
Detailní popis je v architektonickém dokumentu a samozřejmě v kódu jednotlivých služeb na mém GitHubu.
Ukázka výsledku
Co bych chtěl v této sérii řešit?
- Základní architektura s asynchronním zpracováním a streamováním
- Paměť konverzací a dlouhodobá paměť ve jménu uživatele
- Observabilita a monitoring
- Autentizace a autorizace uživatelů
- Popis praktického postupu s GitHub Copilotem (od architektury ke kódu a ne naopak)
- Perf testy
- Chaos engineering
- CI/CD pipeline
- A/B testing a progressive delivery
- Multi-region active/active deployment